『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。
本文要介绍的是 2020 年 OSDI 期刊中的论文 —— Twine: A Unified Cluster Management System for Shared Infrastructure1,该论文实现的 Twine 是 Facebook 过去十年生产环境中的集群管理系统。在该系统出现之前,Facebook 的集群由为业务定制的独立资源池组成,因为这些资源池中的机器可能有独立的版本或者配置,所以无法与其他业务共享。
Twine 的出现解决了不同资源池中机器配置不同的问题,提供了动态配置机器的功能,这样可以合并原本独立的资源池,提高资源整体的利用率,在业务申请资源时可以根据需要配置机器,例如:改变内核版本、启用 HugePages 以及 CPU Turbo 等特性。

图 1 - Twine 设计决策
Kubernetes 是今天十分热门的集群管理方案,不过 Facebook 的方案 Twine 却做出了与 Kubernetes 相反的决策,实现了截然不同的解决方案。需要注意的是使用 Kubernetes 并不一定意味着要使用静态集群、私有节点池和大容量机器,我们仍然可以通过引入其他模块实现动态集群等特性,只是 Kubernetes 本身不支持这些设计。我们在这篇文章中仅会讨论上述三大决策的前两个以及 Twine 如何实现水平扩容、管理大规模的集群。
架构设计
作为可以管理上百万机器、支撑 Facebook 业务的核心调度管理系统,Twine 的生态系统非常复杂,我们在这里简单介绍该系统中的一些核心组件:
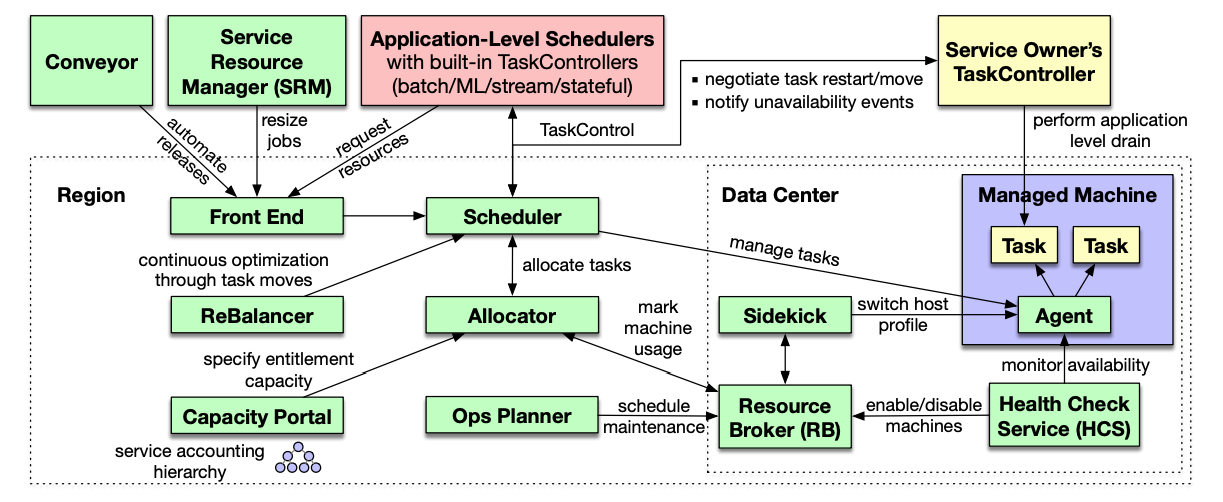
图 2 - Twine 生态系统
- 分配器(Allocator):对应 Kubernetes 中的调度器,负责为工作负载分配机器,它在内存中维护了所有机器的索引和属性并使用多线程处理资源的调度分配;
- 调度器(Scheduler):对应 Kubernetes 中的控制器,它负责管理工作负载的生命周期,当集群出现硬件故障、日常维护等情况时会推动系统做出响应;
- 应用程序调度器(Application-Level Schedulers):对应 Kubernetes 中的 Operator,如果我们想使用特殊的逻辑管理有状态服务,需要实现自定义的调度器;
分配器、调度器和应用程序调度器是 Twine 系统中的核心组件,然而除了这些组件之外,生态中还包含前端界面、优化集群工作负载的平衡器和指定特定业务容量的服务。在了解这些具体组件之后,这里我们围绕文章开头提出的动态集群和自定义配置展开讨论 Twine 的设计。
动态集群
Twine 的动态集群建立在其抽象出的权利(Entitlement)上,每个权利集群都包含一组动态分配的机器、属于特定业务的伪集群。数据中心中的机器和任务之间建立其的这层抽象使机器的分配变得更加动态:
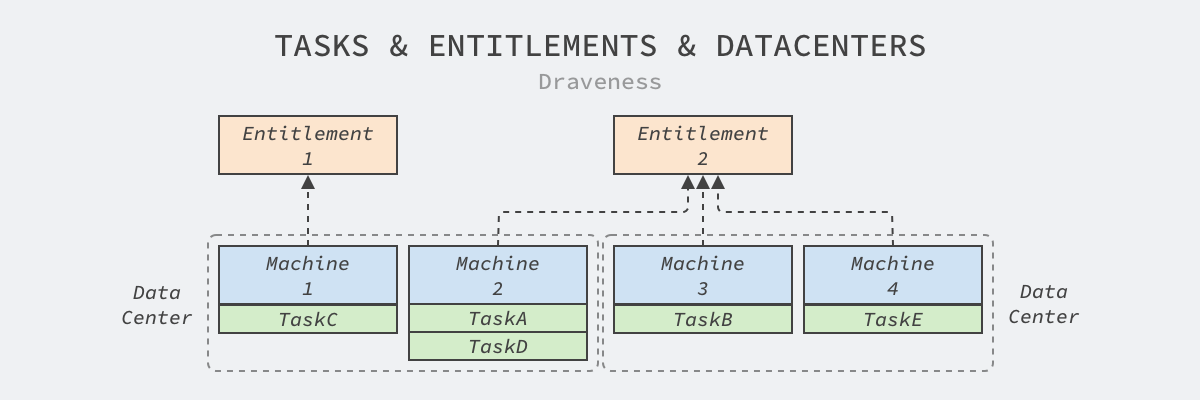
图 3 - 任务、权利和数据中心
分配器不仅会将机器分配给权利集群,还会把同一个权利集群中的工作负载调度到特定的机器上。
需要注意的是,我们在这里简化了 Twine 中的模型,Facebook 的数据中心会由几十个主配电板(Main Switchboard、MSB)组成,它们具有独立的电力供应和网络隔离,配电板上的机器可以看做属于同一个集群。
自定义配置
私有的节点池很不利于机器的共享,但是确实有很多业务对机器的内核版本和配置有要求,例如:很多机器学习或者数据统计的任务都需要使用 Linux 的 HugePages 优化性能,但是 HugePages 可能会损害在线服务的性能。
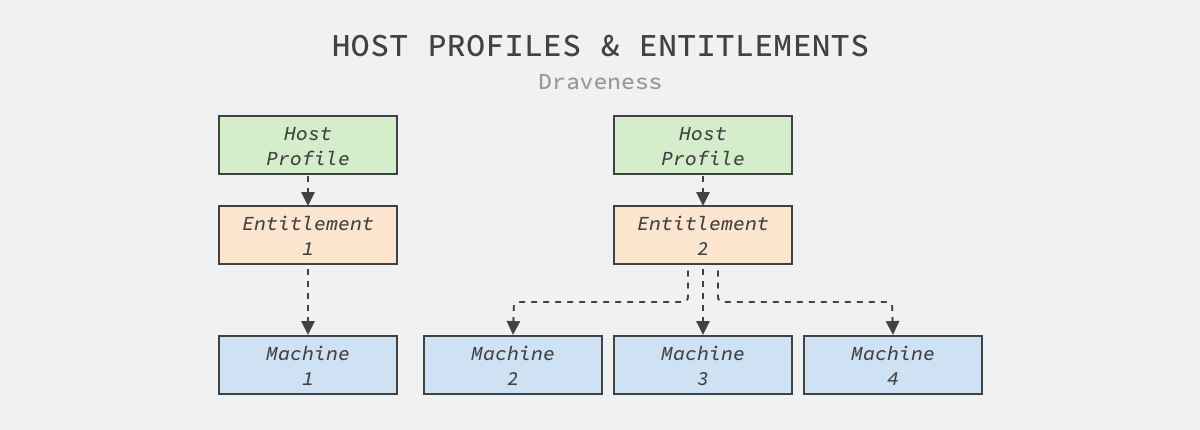
图 4 - 主机配置
Twine 由此引入了主机配置的概念,为每个权利集群绑定独立的主机配置,当数据中心的机器被分配到某个伪集群时,会根据集群的配置更新机器,为工作负载提供最符合需求的运行环境,这在 Facebook 内将 Web 层的服务性能提高了 11%,也是目前的 Kuberentes 无法满足的。
集群规模
Facebook 的集群规模也是目前世界领先的,虽然目前的集群规模还没有突破百万级,但是随着业务的快速发展,Twine 很快就需要支持百万级别的物理机管理,它会通过下面两个原则支撑这个数量级的节点:
- 通过按照权利集群分片的方式水平扩容;
- 通过分离关注点减少调度系统的工作量;
分片
分片是集群或者系统想要实现水平扩容的最常见方式,Twine 为了支持水平扩容就以权利集群的维度分片;作为虚拟集群,Twine 可以在分片之间迁移权利集群,不需要重启机器上的任务,然而跨权利集群的迁移就需要滚动更新的支持了。
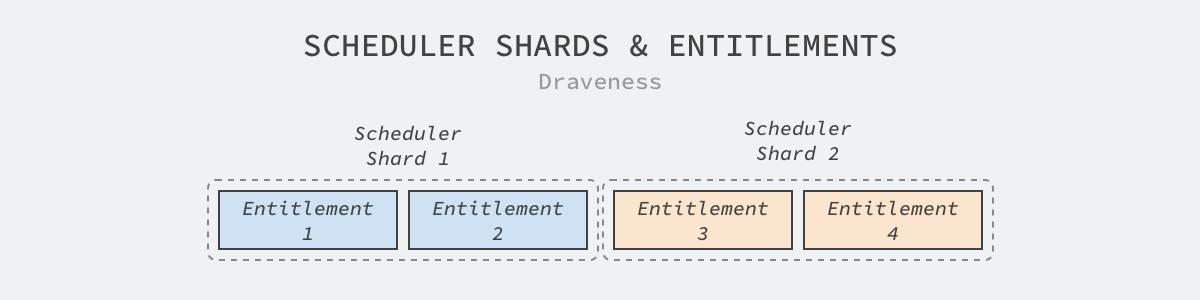
图 5 - 调度器分片
通过分片,集群管理系统的水平扩容就变得非简单,而 Twine 最大的分片中管理了 170,000 台机器,这与 Kubernetes 能够支持 5,000 节点相比有将近两个数量级的差距。
除了分片之外,联邦也是解决集群管理规模的有效手段,Kubernetes 社区的联邦可以让同一个任务在多个独立集群运行,可以支持多地区、混合云甚至多云的部署,但是因为需要跨集群同步信息,所以实现相对比较复杂;Twine 的调度器可以在分片中的机器不足时动态迁移新的机器,所以可以使用单个调度器管理一个服务的所有副本。这里就不讨论两种方案的优劣了,各位读者可以自行思考,不过作者还是倾向于通过的联邦管理多个集群。
分离关注
Kubernetes 是一种中心化的架构,所有的组件都会从集群中的 API 服务器读取或者写入信息,所有的数据都存储在独立的持久存储系统中,而中心化的架构和存储系统也成为了 Kubernetes 集群管理的瓶颈。
Twine 在设计上尽量避免了中心化的存储系统并分离原本属于单个组件的职责,拆分到了调度器、分配器、资源代理、健康检查服务和主机配置服务中,每个服务也有独立的存储系统,这就能够避免单存储系统带来的扩容问题。
总结
在 Kubernetes 大行其道的今天,能够看到 Facebook 分享其内部集群管理系统的不同设计还是有很大意义的,这让我们重新思考 Kubernetes 中设计带来的潜在问题,例如:中心化的 etcd 存储,很多使用 Kubernetes 的大公司为了让其能够管理更多节点,都会选择修改 etcd 的源代码或者替换存储系统。
Kubernetes 对于集群规模较小的公司还是有很大好处的,而其本身确实能够解决集群管理中 95% 的问题,Kubernetes 也不是银弹,它没法做到解决场景内的全部问题。在应用 Kubernetes 时,中小规模的公司可以全盘接收 Kubernetes 的架构和设定,而大公司可以在 Kubernetes 的基础上做一些定制,甚至参与到标准的制定中增加技术影响力、提高话语权并且帮助支撑公司业务成长。
推荐阅读
Tang C, Yu K, Veeraraghavan K, et al. Twine: A Unified Cluster Management System for Shared Infrastructure[C]//14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020: 787-803. ↩︎

转载申请

本作品采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接,图片在使用时请保留全部内容,可适当缩放并在引用处附上图片所在的文章链接。
Go 语言设计与实现
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴! 《Go语言设计与实现》 的纸质版图书已经上架京东,本书目前已经四印,印数超过 10,000 册,有需要的朋友请点击 链接 或者下面的图片购买。
