NSQ 最初是由 bitly 公司开源出来的一款简单易用的分布式消息中间件,它可用于大规模系统中的实时消息服务,并且每天能够处理数亿级别的消息。
特性
- 分布式: 它提供了分布式的、去中心化且没有单点故障的拓扑结构,稳定的消息传输发布保障,能够具有高容错和高可用特性。
- 易于扩展: 它支持水平扩展,没有中心化的消息代理(
Broker),内置的发现服务让集群中增加节点非常容易。 - 运维方便: 它非常容易配置和部署,灵活性高。
- 高度集成: 现在已经有官方的
Golang、Python和JavaScript客户端,社区也有了其他各个语言的客户端库方便接入,自定义客户端也非常容易。
组件
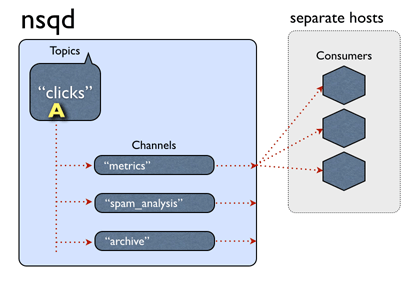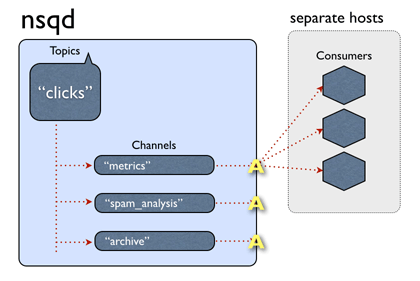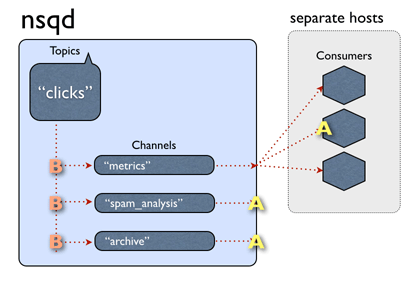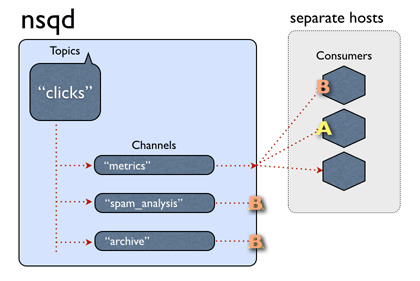
Topic:一个 topic 就是程序发布消息的一个逻辑键,当程序第一次发布消息时就会创建 topic。
Channels: channel 与消费者相关,是消费者之间的负载均衡, channel 在某种意义上来说是一个“队列”。每当一个发布者发送一条消息到一个 topic,消息会被复制到所有消费者连接的 channel 上,消费者通过这个特殊的 channel 读取消息,实际上,在消费者第一次订阅时就会创建 channel。 Channel 会将消息进行排列,如果没有消费者读取消息,消息首先会在内存中排队,当量太大时就会被保存到磁盘中。
Messages:消息构成了我们数据流的中坚力量,消费者可以选择结束消息,表明它们正在被正常处理,或者重新将他们排队待到后面再进行处理。每个消息包含传递尝试的次数,当消息传递超过一定的阀值次数时,我们应该放弃这些消息,或者作为额外消息进行处理。
nsqd: nsqd 是一个守护进程,负责接收(生产者 producer )、排队(最小堆 min heap 实现)、投递(消费者 consumer )消息给客户端。它可以独立运行,不过通常它是由 nsqlookupd 实例所在集群配置的(它在这能声明 topics 和 channels,以便大家能找到)。
nsqlookupd: nsqlookupd 是守护进程负责管理拓扑信息。客户端通过查询 nsqlookupd 来发现指定话题( topic )的生产者,并且 nsqd 节点广播话题(topic)和通道( channel )信息。有两个接口: TCP 接口, nsqd 用它来广播。 HTTP 接口,客户端用它来发现和管理。
nsqadmin: nsqadmin 是一套 WEB UI,用来汇集集群的实时统计,并执行不同的管理任务。 常用工具类:
nsq_to_file:消费指定的话题(topic)/通道(channel),并写到文件中,有选择的滚动和/或压缩文件。
nsq_to_http:消费指定的话题(topic)/通道(channel)和执行 HTTP requests (GET/POST) 到指定的端点。
nsq_to_nsq:消费者指定的话题/通道和重发布消息到目的地 nsqd 通过 TCP。
拓扑图
Nsq 推荐通过他们相应的 nsqd 实例使用协同定位发布者,这意味着即使面对网络分区,消息也会被保存在本地,直到它们被一个消费者读取。更重要的是,发布者不必去发现其他的 nsqd 节点,他们总是可以向本地实例发布消息。
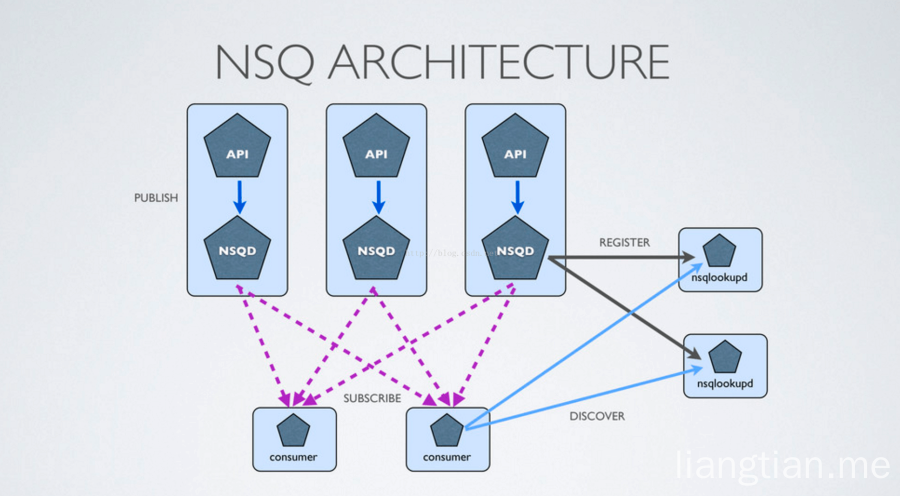
首先,一个 producer 向 nsqd节点发送消息,要做到这点,首先要先打开一个连接(tcp/http),然后发送一个包含 topic 和消息主体的发布命令,topic 会将消息存储在内存的 memoryMsgQueue(优先)或者 磁盘上(backendQueue),通过 messagePump,topic 会复制这些消息并且 put 到在每一个连接 topic 的 channel 上。
每个 channel 的消息都会进行排队,直到一个 consumer 把他们消费,如果此队列超出了内存限制,消息将会被写入到磁盘中。nsqd 节点首先会向 nsqlookupd 广播他们的位置信息,一旦它们注册成功,consumer 将会从nsqlookupd 服务器节点上发现所有包含事件 topic 的 nsqd 节点。
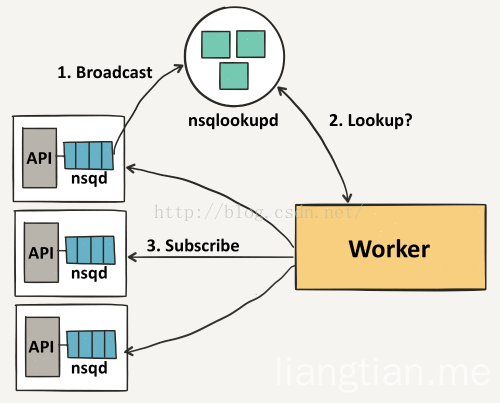
然后每个 consumer 向每个 nsqd 主机进行订阅操作,用于表明 consumer 已经准备好接受消息了。
缺点
-
nsq 内部的消息不是持久化的,因为 topic 和 channel 都使用了 memoryMsgQueue,因为当机器 down 掉之后,是无法恢复内存中的消息的
-
一条消息可能不止被发送一次,这种情况很容易发送,当一条 inFlight 的消息在 timeout 之后返回 FIN,这个时候该条消息已经被重新发送了,同理,message 的 group commit 也很容易导致这种情况,如果 consumer 要求绝对 unique,需要自行解决
-
消费者接收到消息可能是无序的,因为 topic 和 channel 都使用了 backendQueue,而 messagePump 的时候是一同 select race 的,因此可能会导致 message un-ordered
总结
-
nsqlookupd 存放元信息,包括运行着的 nsqd 实例有哪些,在哪些 nsqd 实例上存放着指定 topic/channel 的数据,所以在 nsqd 机器上线/producer 向 nsqd 发送消息/consumer 向 nsqd 订阅消息的时候,都需要向 nsqlookupd 上报
-
那么 nsqd 机器是如何知道 nsqlookupd 的地址呢,在 nsqd 实例启动的时候,会从 option 配置文件中读取设定的地址并存储在内存中,在运行过程中,当配置文件中的 nsqlookupd 地址更改时候,nsqd 会将 nsqd 实例/nsqd 上的 topic/channel 依次向 nsqlookupd 注册
-
producer 可以通过 http/tcp 方式向 nsqd 生产数据,nsqd 写到对应 topic 的内存 queue/磁盘 backupqueue 中
-
消费者通过 nsqlookupd 查询指定 topic 所在的 nsqd 实例,通过 tcp 与其建立连接,这样会在 topic 中建立 consumer 指定的 channel,开始消费
-
nsq 采用 push 模式,消费者会通过回传字段告诉 nsqd 是否还能消费,推消息速率是否过快,也可以设置丢失字段,允许 nsqd 在指定 channel 上丢弃部分数据
-
nsqd 借鉴了 redis 的概率过期算法,动态管理用于传输过程中的消息/延迟发送消息的 goroutine 数量,当抽样 Channel 中需要处理这两种消息的比率很少时,会动态减少 goroutine 数量,反之,会动态增加
使用方式
两种方式一种是直接连接另一种是通过 nsqlookupd 进行连接
直连方式
nsqd 是独立运行的,我们可以直接使用部署几个nsqd 然后使用客户端直连的方式使用.
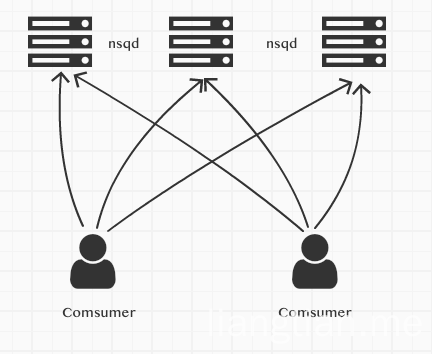
例子: 目前资源有限,我就都在一台机器上模拟了,启动两个nsqd
|
|
正常启动会有类似下面的输出:
|
|
简单使用:
|
|
上面代码的方法: c.ConnectToNSQDs(adds),是连接多个nsqd服务 然后运行多个客户端实现 这时,我们发送一个消息
|
|
nsqd会根据他的算法,把消息分配到一个客户端客户端的输入如下
|
|
但是这种做的话,需要客户端做一些额外的工作,需要频繁的去检查所有nsqd的状态,如果发现出现问题需要客户端主动去处理这些问题。
总结
我使用的客户端库是官方库 go-nsq,使用直接连nsqd的方式,
如果有nsqd出现问题,现在的处理方式,他会每隔一段时间执行一次重连操作。想去掉这个连接信息就要额外做一些处理了。
如果对nsqd进行横向扩充,只能是自己民额外的写一些代码调用ConnectToNSQDs或者ConnectToNSQD方法。
去中心化连接方式 nsqlookupd
官方推荐使用连接nsqlookupd的方式,nsqlookupd用于做服务的注册和发现,这样可以做到去中心化。
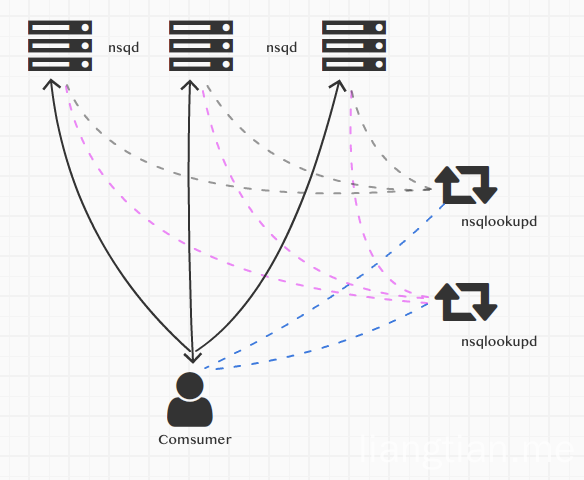
图中我们运行着多个nsqd和多个nsqlookupd的实例,客户端去连接nsqlookupd来操作nsqd
我们要先启动nsqlookupd,为了演示方便,我启动两个nsqlookupd实例, 三个nsqd实例
|
|
为了演示横向扩充,先启动两个,客户端连接后,再启动第三个。
|
|
–lookupd-tcp-address 用于指定lookup的连接地址 客户端简单代码
|
|
方法ConnectToNSQLookupds就是用于连接nsqlookupd的,但是需要注意的是,连接的是http端口7201和8201,库go-nsq 是通过请求其中一个nsqlookupd的 http 方法http://127.0.0.1:7201/lookup?topic=testTopic1 来得到所有提供topic=testTopic1的nsqd 列表信息,然后对所有的nsqd进行连接,
|
|
我们演示一下橫向扩充,启动第三个nsqd
|
|
这里会有一个问题,当我启动了一个新的nsqd但是他的topic是空的,我们需指定这新的nsqd处理哪些topic。 我们可以用nsqadmin查看所有的topic。 启动 nsqadmin:
|
|
然后去你的nsqd上去建topic
|
|
这个时候客户端日志有输出:
|
|
已经连上我们的新nsqd了
我手动关闭一个nsqd实例, 客户端的日志输出已经断开了连接
|
|
并且nsqd和nsqlookupd也断开了连接,客户端再次从nsqlookupd取所有的nsqd的地址时得到的总是可用的地址。
去中心化实现原理
nsqlookupd用于管理整个网络拓扑结构,nsqd用他实现服务的注册,客户端使用他得到所有的nsqd服务节点信息,然后所有的consumer端连接 实现原理如下,
nsqd把自己的服务信息广播给一个或者多个nsqlookupd 客户端连接一个或者多个nsqlookupd,通过nsqlookupd得到所有的nsqd的连接信息,进行连接消费, 如果某个nsqd出现问题,down机了,会和nsqlookupd断开,这样客户端从nsqlookupd得到的nsqd的列表永远是可用的。客户端连接的是所有的nsqd,一个出问题了就用其他的连接,所以也不会受影响。