第六章 基本排序方法
- 基本的意思是:适用于小规模或特殊结构
- 基本排序方法之间的时间复杂度只相差常数因子:都与 N^2 成正比
- 可用来改进更复杂算法的效率
- 不占用额外的内存空间
- 排序:
- 内部排序:任意访问元素
- 外部排序:必须顺序访问
- 数组:适合顺序分配
- 链表:适合链式分配
- 非适应性:所执行的操作序列独立于数据顺序(只使用了比较-交换操作),适于硬件实现
- 自适应性:操作序列与比较结果有关,大部分算法都是这类
- 减少开销:
- 换成更高效的算法
- 缩短内部循环
- 额外内存空间:
- 原位排序:小堆栈或表
- 引用数据:N
- 足够空间:副本
- 稳定的:相同关键字排序后位置不变
- 不稳定的:相同关键字排序后位置改变
- 强制稳定:
- 改用稳定排序较好
- 排序前为各关键字添加小索引
- 加长关键字
- 访问的元素过大:使用间接排序
- 选择排序:选出最小(最大)元素,与第一个元素交换,然后对除第一个元素外的其余元素重复选择
- 对数据不敏感
- 对已排序或全部元素相同:等同于随机元素序列,因为未利用已有顺序,还是平方
- 移动数据次数少:适用于大元素
- 插入排序:将较大(较小)元素(可能有多个元素)向后移动,每次有序数组大小加 1
- 对一个有序数组插入一个新元素(有序数组的下个元素),与有序数组的每个元素从右到左比较
- 运行时与总逆序数有关,与分布无关
- 优化策略:
- 提前停止执行(新元素 >= 有序数组中的元素):因为这时新元素已插入到正确位置
- 设置最小(最大)观察哨关键字
- 去掉内部循环中的无用操作
- 比较次数少
- 对已排序文件:线性
- 对部分排序的文件:高效,因为插入排序(和冒泡排序)执行过程中也是部分有序的
- 对已排序的文件添加或修改:使用插入排序高效,但不适合冒泡排序
- 效率较低的原因:交换操作只涉及近邻元素,每次只能移动一位
- 冒泡排序:遍历文件,顺序不对则交换,重复直至全部有序
- 也属于选择排序,但需开销更多工作将元素放到合适位置
- 内部 for 循环中:
- 冒泡排序:从右边(未排序)向左移动
- 插入排序:从左边(已排序)向右移动
- 非适应性
- 最坏、最好差别不大
- 对已排序:线性
- 对于小型文件:选择排序、插入排序的效率是冒泡排序的 2 倍
- 优化:
- 提前终止外部循环:当其中一步没有交换时,这时是已排序的
- 鸡尾酒排序(Cocktail shaker sort)
- 希尔排序:
- 在使文件变得 h- 有序时,通过将较大的元素右移,把元素插入在 h- 子文件中某些元素前面
- 每第 h 个元素的集合是一个有序文件:h 个独立的已排序文件,相互交叉在一起
- 步骤:
- 对 n 个元素,取一个整数 d < n。将 n 个元素分成 d 组,位置相差为 d 倍数的分成一组,每组 n/d 个元素
- 对 d 逐渐减小,直至为 1:对每组使用插入排序
- 插入排序的改进:通过允许非相邻元素进行交换来提高效率
- N^1.25
- 步长序列:
- 通常以几何级别减小:2 的幂
- 能提高 25% 的效率:
for (h = 1; h <= (r-l)/9; h = 3*h+1):1, 4, 13, … - 最好:1, 5, 19, …
- 最简单:1, 8, 23, …
- 指针排序(索引排序):不移动元素,维持一个索引数组,元素的关键字仅比较时访问。不会交换真的元素,而是交换索引,可通过索引来访问元素
- 原位排序(合适置换、原位重排)
- 可以避免扰乱要排序的数据和避免移动整个记录
- 可用于对只读访问的数据排序
- 灵活:操纵数据而不改变数据
- 记录还是过大:还是选择使用选择排序
- 链表排序:
- 适用于指向正在操纵的表节点的指针是由应用系统的其它部分操纵的时:这时只能改变节点中的链接,而不能改变关键字值等其它信息
- 高效支持链表操作时才会高效
- 排序后使得按链接访问(遍历)时是有序的,同时其它链接不改变顺序
- 关键字索引统计(计数排序):
- 关键字必须是在一个小范围内的整数
- 对于 N 个介于 0-R-1 之间的关键字:线性
- 大小为 R 的辅助表用于存放统计数
- 大小为 N 的表用于重排记录
第七章 快速排序
- 在两部分有序时重排以使整个文件有序:一个选择操作,后跟两个递归调用
- 通用:易于实现
- 处理多种不同输入
- 消耗资源少
- 原位排序:小辅助栈
- 平均与 NlgN 成正比
- 最坏平方
- 不稳定:基于数组的快速排序无法稳定
- 内部循环小
- 分治(递归):
- 分别进行排序,每次将一个元素移到最终位置
- 数组中有一个或零个元素时终止(基线条件)
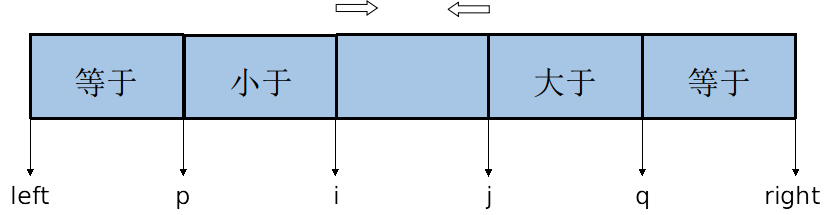
- a[l]-a[i-1] 中的元素都比 a[i] 小(大)
- a[i+1]-a[r] 中的元素都比 a[i] 大(小)
- 左指针 l 从左扫描,直到找到比 i 大(小)的元素,停止
- 右指针 r 从右扫描,直到找到比 i 小(大)的元素,停止
- 停止并交换这两个元素,直至两个指针相遇,这时完成划分,再将右指针与 i 交换
- 当元素与 i 相等时:两个指针都停止并交换较好
- 优化策略:
- 混合算法:在遇到小的子文件(阈值M在5-25之间)时调用插入排序
- 几乎所有的递归算法在小问题中都会占据大部分时间
- 三者取中划分(采样):取三个元素的中位数作为划分元素
- 5% 提升
- 最坏情况几乎不可能发生
- 随机元素(概率算法):最坏可能性变小
- 消除递归、用内嵌代码代替函数调用、使用观察哨
- 三者取中划分 + 小的子文件阈值:20%-25% 提升
重复关键字:
- 使用三路划分方法:
- 扫描时,将遇到的左子文件中与划分元素相等的放到最左边(leftEqual 指针指向),右子文件中与划分元素相等的放到最右边(rightEqual 指针指向)
- 然后,当两个扫描指针相遇时,等值关键字的精确位置就知道了,只需将所有等值关键字交换到划分元素两边即可
- 数组中的元素组成:
选择算法(第 k 大(小)元素问题):快排中的划分过程:partition 函数
- 平均:线性
- 最坏:与快排相同,平方
- 修改选择过程,可保证线性
- 快排基础:找出文件第 k 大(小)元素
- 将文件分为两个部分:k 个最小元素 + N-k 个最大元素
第八章 归并与归并排序
- 归并操作:将两个独立的文件合并成一个文件
- 将文件分为两部分来排序,对这两部分有序的文件进行组合,以使整个文件都有序
- 两个递归调用 + 一个归并过程
- 无论任何输入都为:与 NlgN 成正比,加上与 N 成正比的额外空间
- 顺序访问数据:适合链表(同样高效)、适合外部排序(多路归并)
- 两路归并:给定两个已排序文件,取出其中最小(大)文件放入最终文件
- 两个有序子文件不相交:彼此不共享元素和存储空间
- 独特应用:将新一组小文件排序,再与大文件归并
- 优化策略:
- 对小文件改用插入排序:10%-15% 提升
- 使用抽象原位排序来避免复制数组的额外开销:
- 在复制时将第二个数组变成倒序(无需额外开销),因此相关的指针改为从右向左移动
- bitonic 序列:关键字先递增再递减(或先递减再递增)
- 不稳定
- 代价:需要在内循环中放入检测是否到达末尾的代码
- 解决:重新生成 bitonic 序列,这样就无需观察哨
- 结合以上优化策略:40% 提升
- 自顶向下(Top-down,递归法):先处理左半部分,后处理右半部分
- 自底向上(Bottom-up,迭代法):从左到右处理其余最小的
- 自然归并排序(链表归并):
- 不是 ceil(lgN) 而是 ceil(lgS),S 为原数组中有序子文件个数
- 含有有序子文件的块:高效的
- 与快速排序的对比:
- 归并排序:
- 以最小开始,以最大结束
- 分成两部分,分别处理每部分
- 快速排序:
- 以最大子文件开始,以最小结束
- 大多数工作在递归调用之前就已完成
第九章 优先队列与堆排序
- 优先队列:
- 插入新元素、删除最大(小)元素
- 栈和队列的推广
- 排序:先插入所有记录,然后依次取出
- 无序表:选择排序
- 有序表:插入排序
- 重复关键字:含有最大(小)关键字值的记录
- 堆有序树的有向链表(三链)
- 堆:优先队列的一种实现
- 堆有序:每个关键字必定大于(小于)或等于所有子节点
- 数组表示:根节点 a[1]、子节点 a[2], a[3],再下一层以此类推
- 位置:i 处节点的父节点为: floor(i/2),两个子节点为:2i, 2i+1
- 完全二叉树:N 个节点,路径节点约为:lgN,最下一层节点:N/2,每层节点数是下一层的一半,最多 lgN 层
- 链表实现:
- 三链堆有序的完全树
- 联赛
- 二项队列
- 堆化(修正堆):先侵犯堆的条件,再遍历堆,在需要的时候修改堆使其满足堆有序的条件
- 不断与父节点(子节点)比较并交换
- 堆底:向上遍历,直到根节点
- 替换根节点:向下遍历,直到堆底
- 数组中第一个元素即为堆顶,最后一个元素为树表示中最右边最下面的元素
- 插入:在数组末尾插入新元素,然后向上堆化
- 取出最大(小)元素:取出堆顶元素,由数组末尾元素代替,再向下堆化
- 构造堆:
- 一个个插入:平均线性,最坏线性对数
- 自底向上:从数组中间开始向后扫描,对每个节点进行向下堆化。平均、最坏:线性
- 堆排序:构造堆后,循环交换堆顶元素和数组末尾元素,并对堆顶进行向下堆化
- 可用于第 k 大元素问题:最好常数
- 与输入无关
- 不稳定
- 无额外时间
- Floyd 改进:有最少比较次数,适用于比较开销较大的元素,但需要额外空间
- 二项队列:
- 二项树等于 2 次幂堆:
- 节点数为 2 的幂次
- 根节点大于所有节点
- 堆有序:二项树
- 连接(join):常量
- 最大根节点:根节点
- 另一个根节点:左子节点
- 最大左子树:另一棵右子树
- 优先队列操作最坏情况
| 插入 | 删除最大(小) | 删除 | 找最大 | 修改优先级 | 连接 | |
|---|---|---|---|---|---|---|
| 有序数组 | N | 1 | N | 1 | N | N |
| 有序表 | N | 1 | 1 | 1 | N | N |
| 无序数组 | 1 | N | 1 | N | 1 | N |
| 无序表 | 1 | N | 1 | N | 1 | 1 |
| 堆 | lgN | lgN | lgN | 1 | lgN | N |
| 二项队列 | lgN | lgN | lgN | lgN | lgN | lgN |
| 理论最佳 | 1 | lgN | lgN | 1 | 1 | 1 |
第十章 基数排序
- 每次只对关键字的一块进行处理
- 把关键字看作以 R 为基数的数字,对不同的 R 值(基)处理独立位
- 整数:表示为二进制数,R=2 或 R=2的幂:访问每组中的位代价较低
- 字符串类型:R=128 或 R=256,按照字节大小把基对齐
- 提取操作:从一个关键字中提取出第 i 个数字
- 最高位优先(MSD):从左往右检查,先处理最高位,需要检查的信息最少
- 与快排类似,根据关键字开始的几位划分,递归处理子文件
- 最低位优先(LSD):从右往左检查,先处理最低位,先处理最不重要的数字
- 关键点:关键字索引统计:只要有足够空间存放 2^w 大小的表,就可以线性时间对 w 位关键字进行排序
- 二进制快速排序:
- 2^b 用作划分元素(可能不在文件中)
- 递归调用对少于 1 位的关键字调用的:次数由位数决定
- 开始指针取决于硬件中每个字的位数、整数和负数表示方法
- 退化时划分频繁:所有位的值都相等
- 递归分界线:由待排数据范围和数字的二进制表示法决定
- MSD:
- 将数组分成 R 部分
- 文件已基本有序:效率很高
- 优化:
- 调整 R 的值,减少小文件:限制空桶数量:合适的基数 + 合适的划分小文件的值
- 递归参数转换消除数组复制的开销
- 链表实现
- 处理缺乏随机性的数据:
- 将所有字符串排序情况信息都考虑进去
- 桶跨度启发式法
- 三路基数快速排序:
- 对关键字控制字节进行三路划分,只在中间子文件移动到下一字节(关键字的控制字节与划分元素的控制字节相同)
- 划分操作适合关键字不同部分含有非随机的不同类型的关键字,且无需额外数组
- 适合:
- 重复关键字
- 关键字位于小的范围
- 小文件和 MSD 可能慢的情况
- 不同基数对应的排序方法:
- 中间大小的基数:高效处理重复关键字
- 非常大的基数(大于字的大小):普通快排
- 基数 2:二进制快排
- 适合向量:多关键字快速排序
- 大型文件:标准 MSD:多路划分
- 小型文件:三路基数快排:避免大量空桶
- LSD:
- 关键字索引统计:稳定,高效
- 基于固定长度关键字,控制关键字只在最后一遍涉及
- 控制结构简单,基本操作适合机器语言实现,可直接改编到有特殊用途的高性能硬件中
- 对 w- 字节的 N 个记录:与 Nw 成正比
- 长关键字短字节:与 NlgN 成正比,需详细说明关键字中的字节数而不是关键字的数目
- 短关键字长字节:线性
- 最坏情况:关键字都相等,需要检查所有字节:线性
- 随机数据:亚线性,
- 使 lgR(每字节位数)为字大小的 1/4:
- 从字中提取字节而不是位
- 中途使用插入排序:2 遍
- 4 遍关键字索引统计
第十一章 特殊用途的排序方法
- 应用:
- 高性能增强的系统
- 专门为排序设计的具有特殊用途的硬件
- 基于某种新型结构设计的系统
- 低层模型:只允许比较-交换操作
- 高层模型:在较慢的外部介质或独立的并行处理器上读写大块数据
- Batcher 奇偶归并排序:归并排序的一种版本,基于分治归并算法,只使用比较-交换操作
- 数据移动:
- 完美混洗(Perfect shuffle)
- 2^n-2^n 方阵以行为主序:n 次完美混洗:转置(以列为主序)
- 先分成两半,先去第一半第一个元素,再取另一半第一个元素等等
- 从 0 开始编号,前一半元素编到偶数编号,后一半元素编到奇数编号
- 完美逆混洗(Perfect unshuffle)
- 偶数到前半,奇数到后半
- 用交换、混洗或类似操作来重排数据
- 自顶向下归并:归并过程用 Batcher,属于非适应性
- 作为排序网的 Batcher 方法:
- 比较器(比较-交换模块):能够执行比较-交换操作的模块
- 排序网:只能比较-交换,是一种并行计算模型
- 外部排序:
- 从外部存储器读入,把内存写入外部存储器
- 待排文件过大所以不能放入内存:大块形式,串行化随机高效,随机访问达到外部设备峰值性能
- 访问记录开销巨大:排序-归并:对文件扫描,分成等于内存的数据块,对块进行排序。若干遍扫描后创建大的文件块(可选),用于将有序块归并
- P(归并的阶数):顺序访问:P 为可用设备的一半
- 平衡多路归并:
- 步骤:初始分布遍;几次多路归并遍
- 降低开销:替换选择(增加内存);多阶段归并(增加设备)
- 虚拟内存:访问地址分散,不适合堆、基数排序
- 运行时间 = 读写整个文件时间 * 所使用遍数
- 并行排序:
- 待排文件分布在多个独立的并行处理器
- 增加处理器,则开销(通信)增加:这时应使用 Batcher 网络
- 处理器间的通信约束:大块数据顺序处理