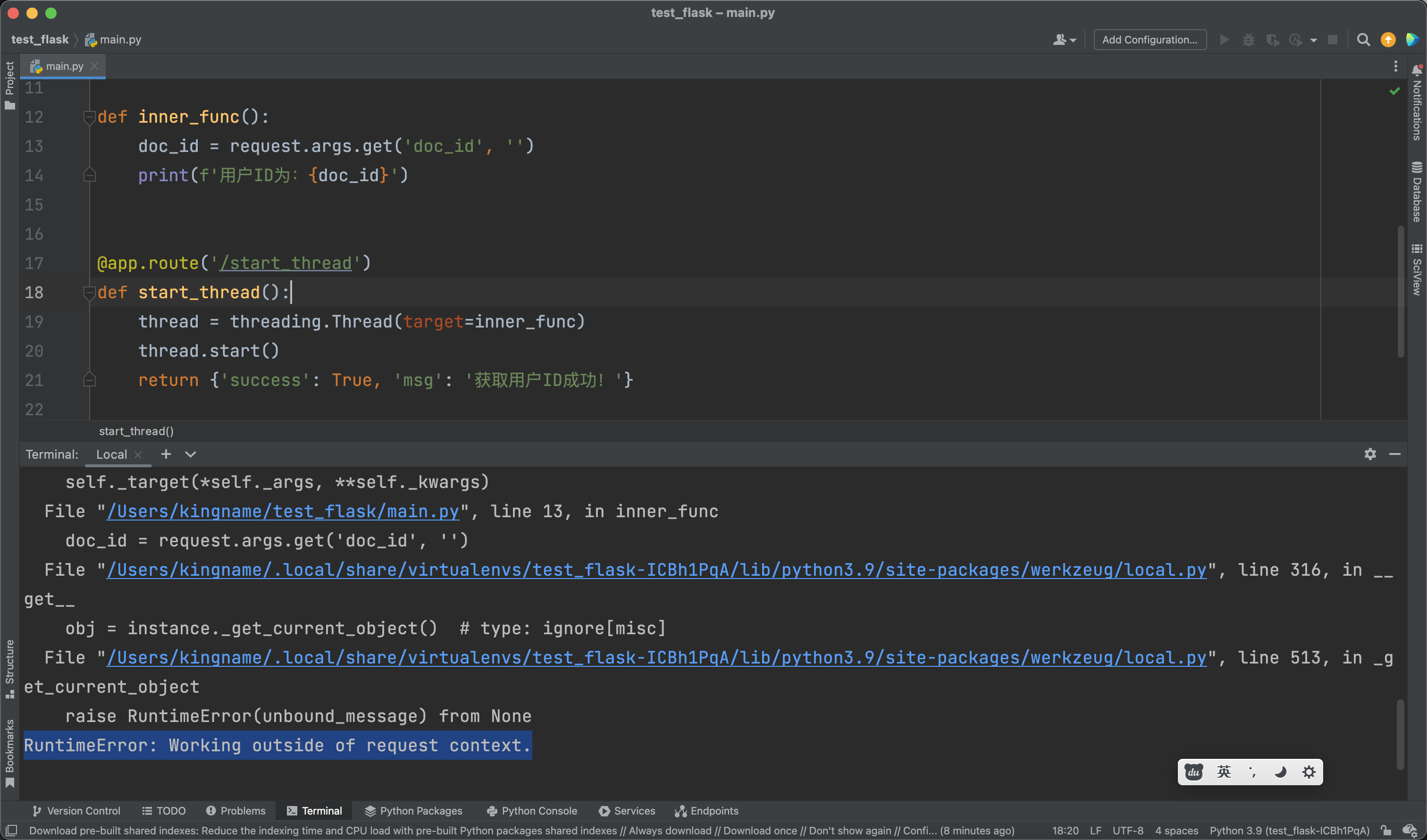
如果你在Flask中启动过子线程,然后在子线程中读写过g对象或者尝试从request对象中读取url参数,那么,你肯定对下面这个报错不陌生:RuntimeError: Working outside of request context..
例如下面这段Flask代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import threading
from flask import Flask, request
app = Flask(__name__)
def inner_func():
doc_id = request.args.get('doc_id', '')
print(f'用户ID为:{doc_id}')
@app.route('/start_thread')
def start_thread():
thread = threading.Thread(target=inner_func)
thread.start()
return {'success': True, 'msg': '获取用户ID成功!'}
|
请求/start_thread接口就会报错,如下图所示:
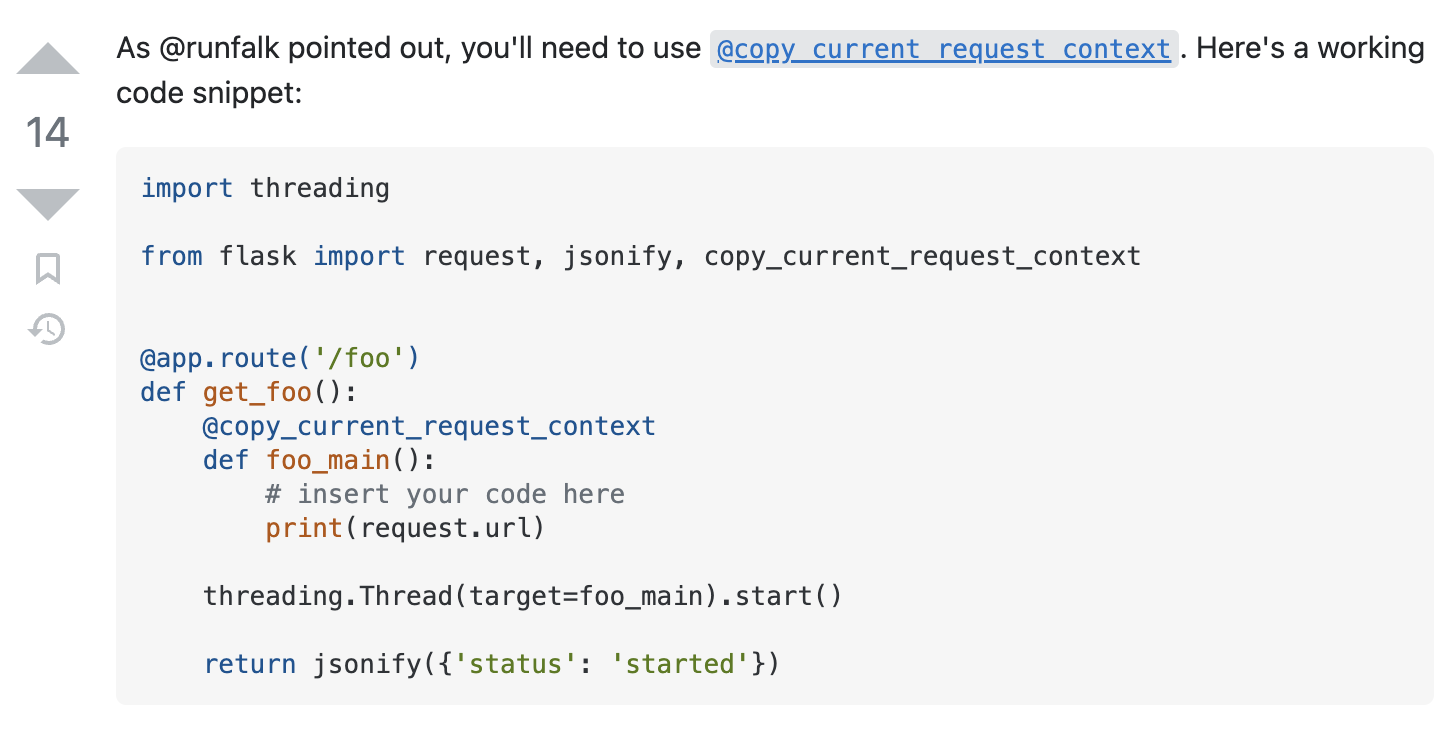
如果你在网上搜索flask thread RuntimeError: Working outside of request context. ,那么你可能会看到官方文档或者StackOverFlow上面提供了一个装饰器@copy_current_request_context。如下图所示:
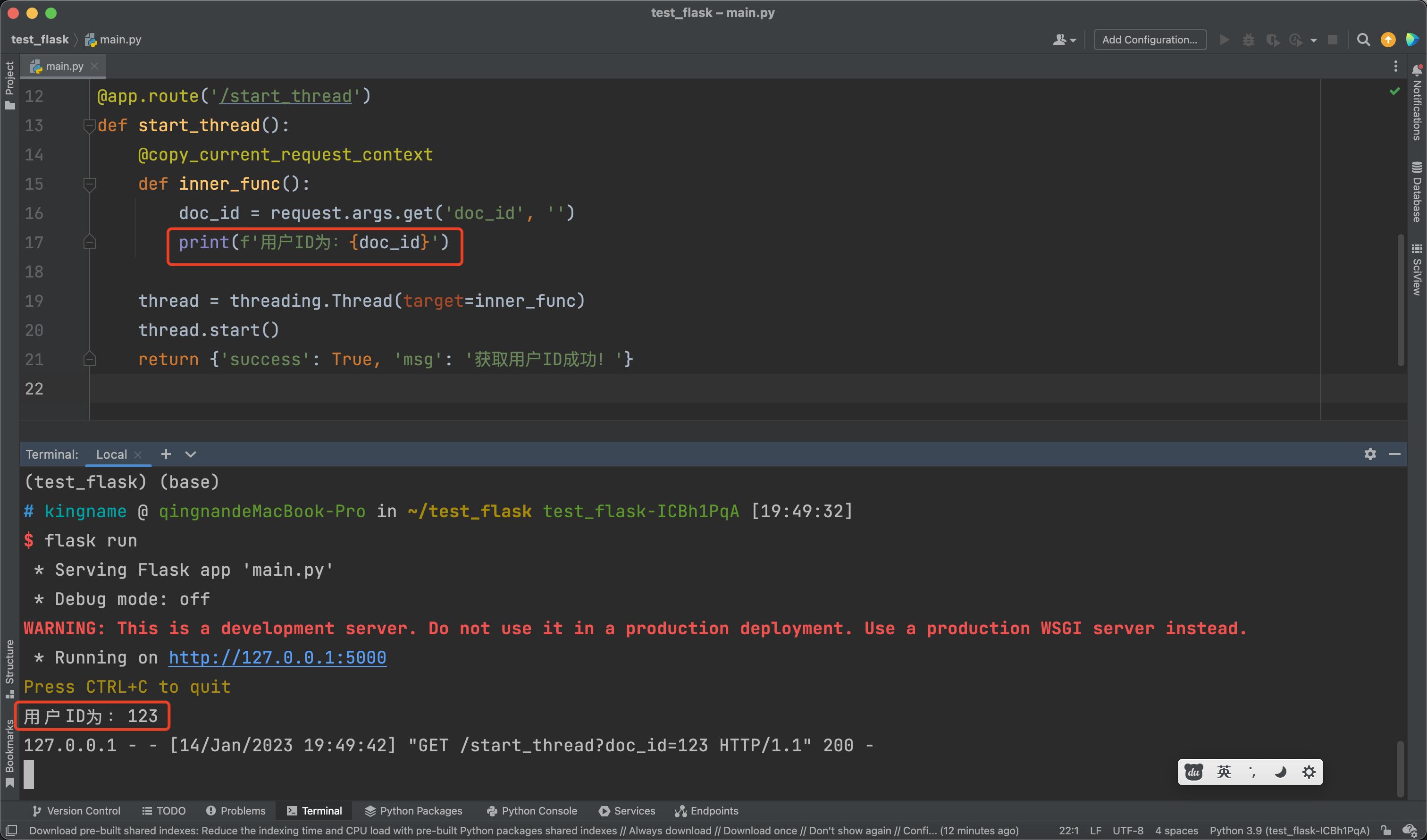
照着它这样写,确实能解决问题,如下图所示:
但无论是官网还是StackOverFlow,它的例子都非常简单。但是我们知道,启动线程有很多种方法,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import threading
job = threading.Thread(target=函数名, args=(参数1, 参数2), kwargs={'参数3': xxx, '参数4': yyy})
job.start()
import threading
class Job(threading.Thread):
def __init__(self, 参数):
super().__init__()
def run(self):
print('子线程开始运行')
job = Job(参数)
job.start()
from multiprocessing.dummy import Pool
pool = Pool(5)
pool.map(函数名, 参数列表)
|
网上的方法只能解决第一种写法的问题。如果想使用方法2和方法3启动子线程,代码应该怎么写呢?如果在子线程中又启动子线程,再用一次@copy_current_request_context还行吗?
相信我,你在网上搜索一下午,只有两种结果:一是找不到答案,二是找到的答案是晚于2023年1月14日的,因为是别人看了我这篇文章以后,再写的。
解答上面的问题前,还是说明一下我对于在后端启动子线程这个行为的观点。例如有些人喜欢在后端挂一个爬虫,请求接口以后,通过线程启动爬虫,爬虫开始爬数据。又或者,有些人在后端上面挂了一些复杂的程序代码,请求接口以后,后端启动子线程,在子线程中运行这些代码。
我一向是不建议在后端又启动子线程去做复杂操作的。无论你使用的是Flask还是Django还是FastAPI。正确的做法应该是使用消息队列,后端只是把触发任务的相关参数发送到消息队列中。下游真正的运行程序从消息队列读取到触发参数以后,开始运行。
但有时候,你可能综合考虑性价比,觉得再增加一个消息队列,成本太高;或者干脆是要赶工期,不得不先暂时使用多线程来解决问题,那么这篇文章将会极大帮助到你。
尽量不要在子线程中读取请求相关的参数
如果你的子线程不需要读写g对象,也不需要从请求中读取各种参数,那么你就可以关闭这篇文章了。因为你的子线程可以直接运行,不会遇到什么的问题,例如:
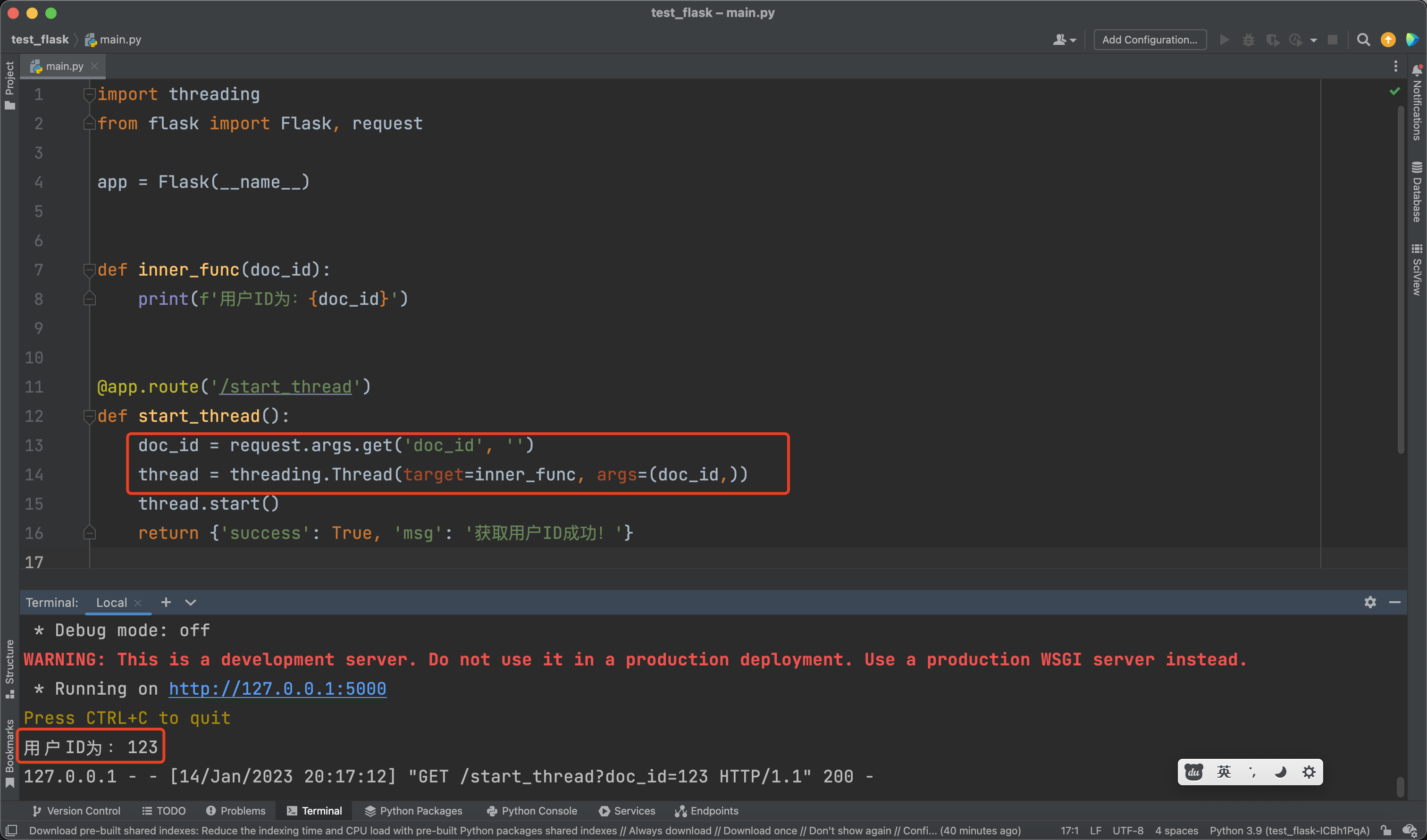
所以最好的解决方法,就是在启动子线程之前,提前先获取到子线程需要的每一个参数,然后把这些参数在启动子线程的时候作为函数参数传进去。如果你是从零开始写代码,那么一开始这样做,就可以帮你避免很多麻烦。
但如果你是修改已有的代码,并且嵌套太深,已经没有办法一层一层传入参数,或者代码量太大,不知道哪些地方悄悄调用了g对象或者读写了请求上下文,那么你可以继续往下看。
装饰闭包函数而不是一级函数
上面的简单多线程写法,有一个地方需要特别注意,被@copy_current_request_context装饰的子线程入口函数inner_func,必须是闭包函数,不能是一级函数。如下图所示:
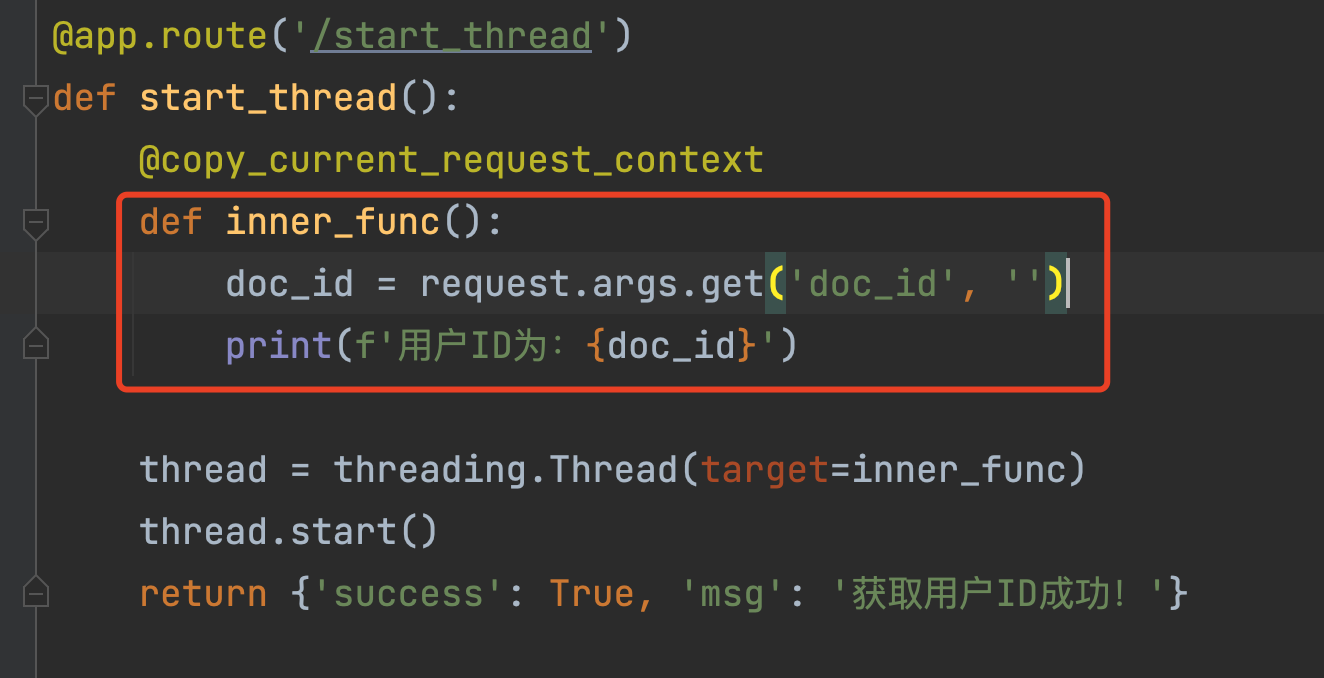
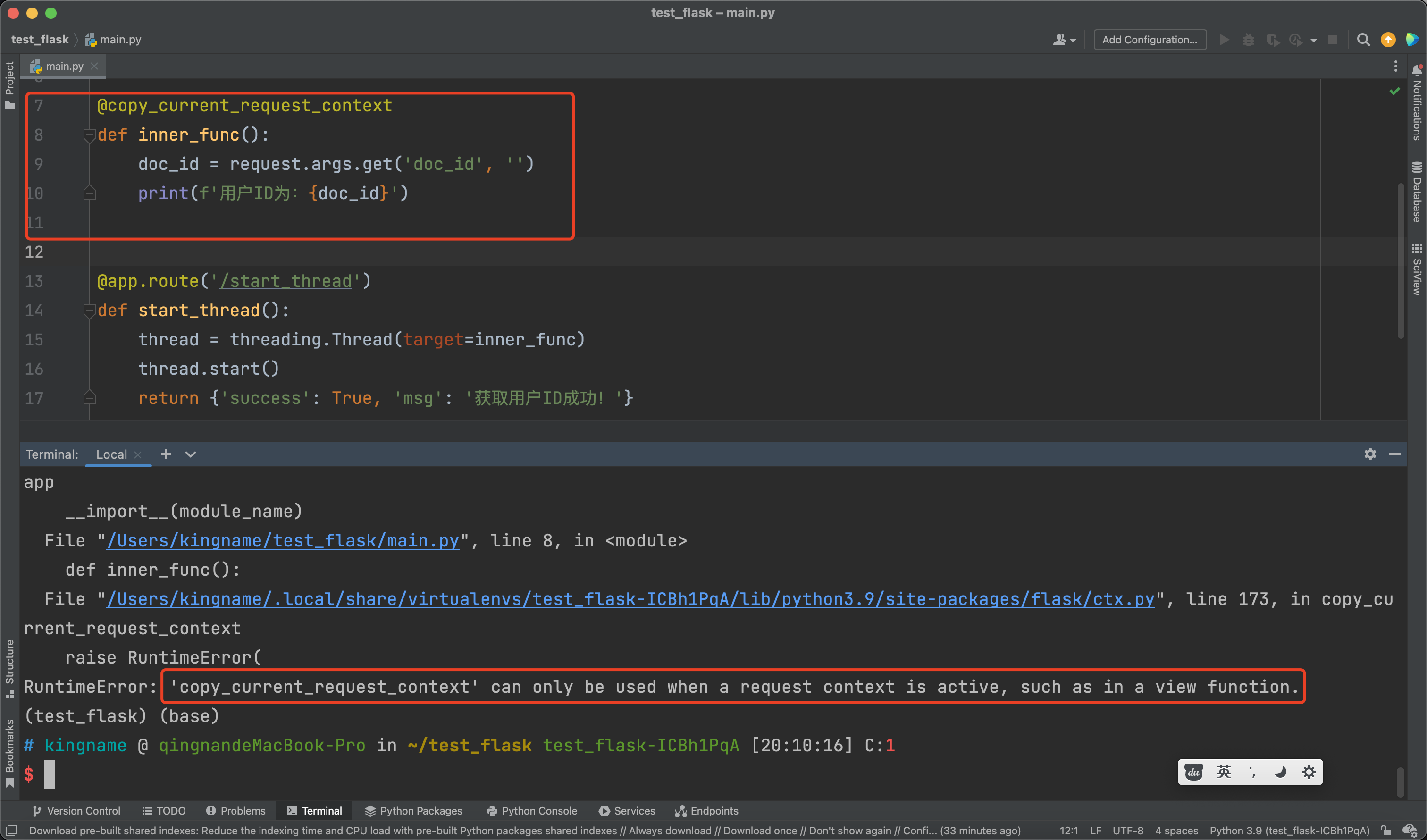
如果不小心装饰了一级函数,就会报如下的错误:
线程池复制请求上下文
当我们使用multiprocessing.dummy来实现线程池时,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| from multiprocessing.dummy import Pool
from flask import Flask, request, copy_current_request_context, g
app = Flask(__name__)
@app.route('/start_thread', methods=['POST'])
def start_thread():
@copy_current_request_context
def crawl(doc_id):
url_template = request.json.get('url_template', '')
url = url_template.format(doc_id=doc_id)
print(f'开始爬取:{url}')
doc_id_list = [123, 456, 789, 111, 222, 333, 444]
pool = Pool(3)
pool.map(crawl, doc_id_list)
return {'success': True, 'msg': '爬取文章成功!'}
|
运行效果如下图所示:
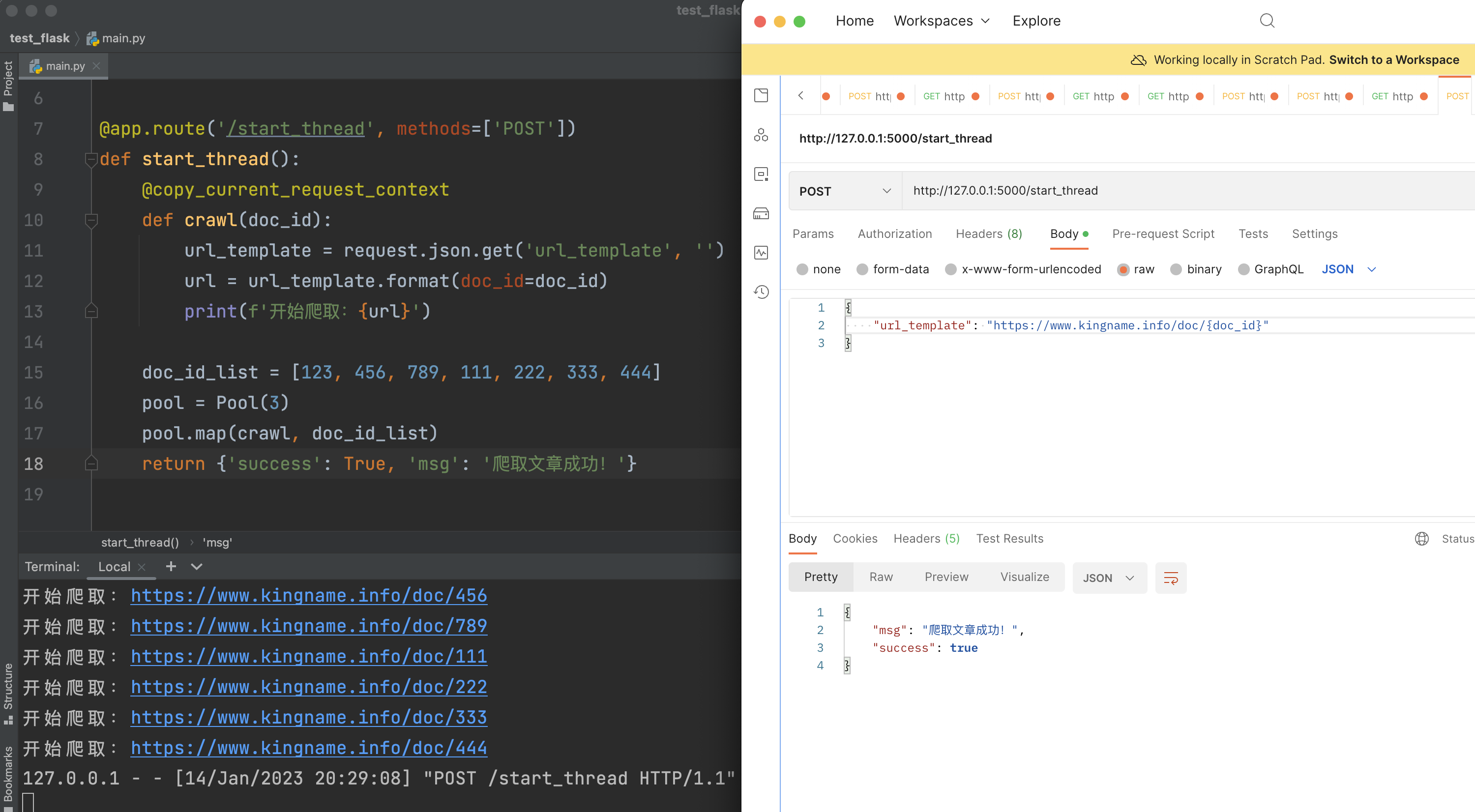
写法上整体跟threading.Thread启动简单线程的方法差不多。
用类定义线程时复制请求上下文
当我们额外定义了一个线程类时,需要把被装饰的闭包函数传入到子线程中,然后在子线程的run()方法中运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import threading
from flask import Flask, request, copy_current_request_context
app = Flask(__name__)
class Job(threading.Thread):
def __init__(self, func):
super().__init__()
self.func = func
def run(self):
self.func()
@app.route('/start_thread', methods=['POST'])
def start_thread():
@copy_current_request_context
def runner():
doc_id = request.json.get('doc_id', '')
print(f'docId的值是:{doc_id}')
job = Job(runner)
job.start()
return {'success': True, 'msg': '读取文章成功!'}
|
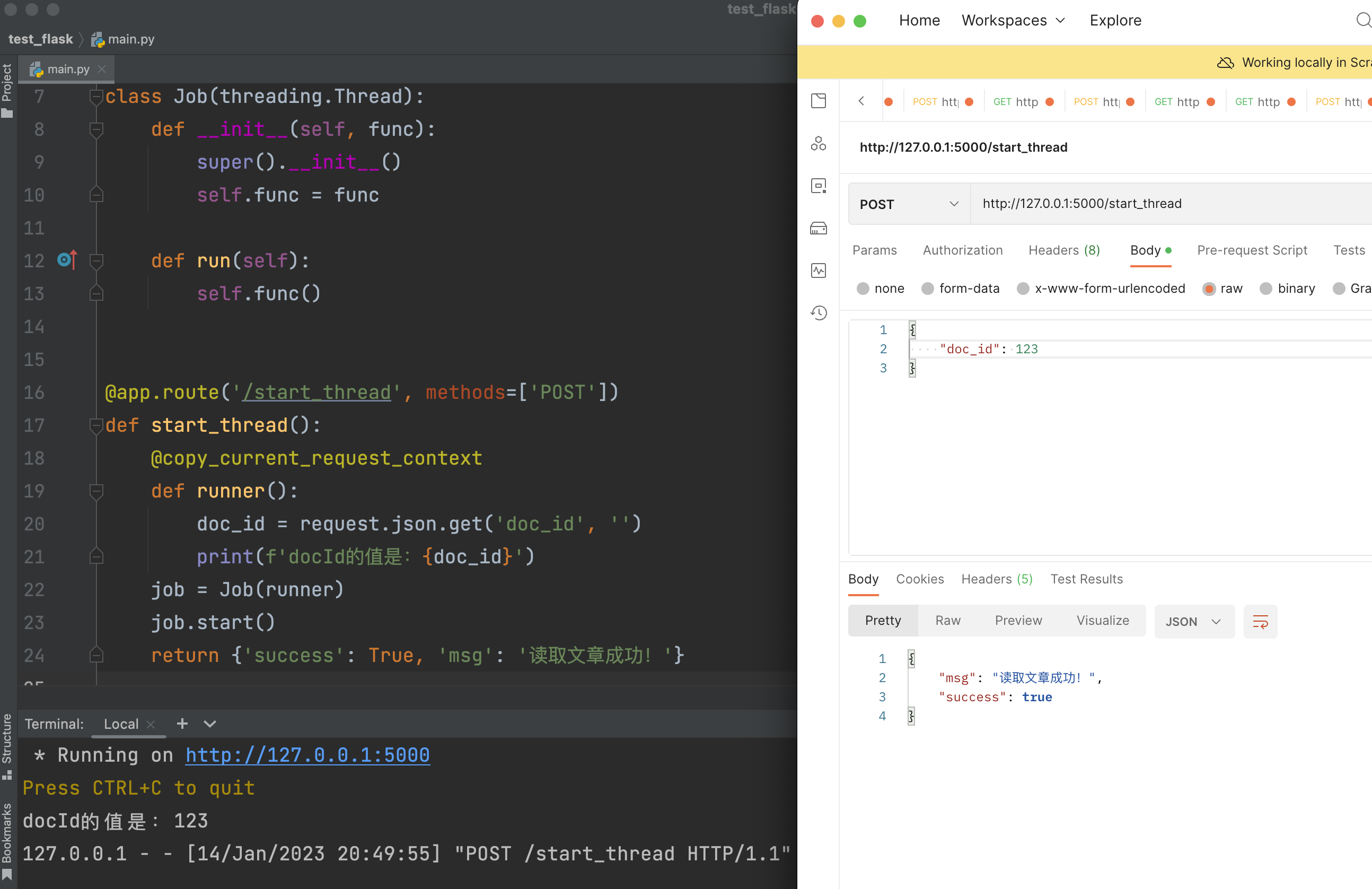
运行效果如下图所示:
嵌套子线程复制请求上下文
有时候,我们先创建了一个子线程,然后在子线程中,又需要创建孙线程。并且在孙线程中读取请求上下文。例如下面的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import threading
from multiprocessing.dummy import Pool
from flask import Flask, request, copy_current_request_context
app = Flask(__name__)
def deep_func_runner(doc_id_list):
@copy_current_request_context
def deep_func(doc_id):
category = request.args.get('category', '')
url = f'https://www.kingname.info/{category}/{doc_id}'
print(f'开始爬取:{url}')
pool = Pool(3)
pool.map(deep_func, doc_id_list)
@app.route('/start_thread', methods=['POST'])
def start_thread():
@copy_current_request_context
def runner():
doc_id_list = [111, 222, 333, 444, 555, 666, 777, 888, 999]
deep_func_runner(doc_id_list)
job = threading.Thread(target=runner)
job.start()
return {'success': True, 'msg': '读取文章成功!'}
|
此时使用@copy_current_request_context就会报您一个错误:ValueError: at 0x104446700> was created in a different Context。如下图所示:
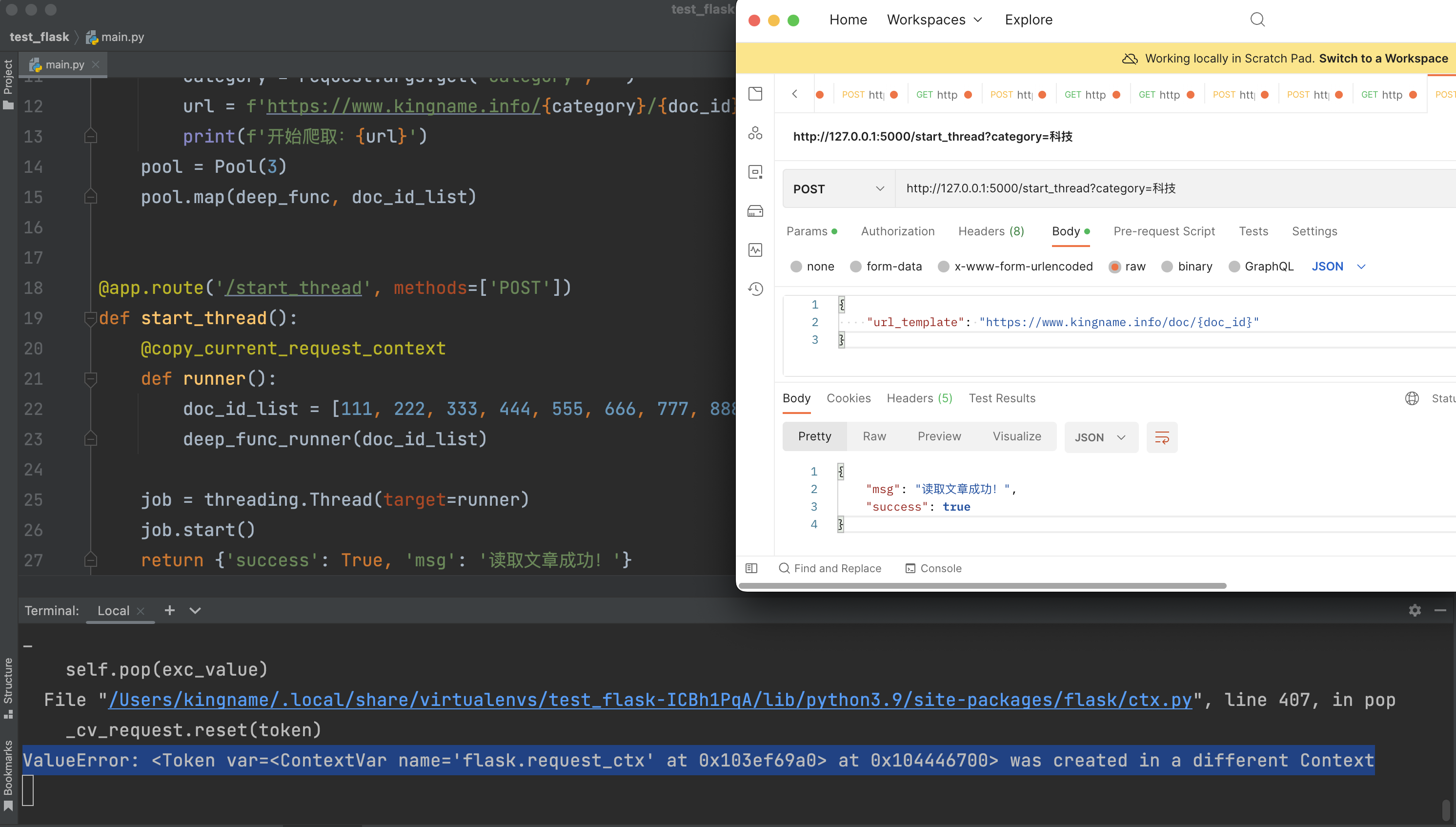
这个时候,我们就需要额外再创建一个装饰器:
1
2
3
4
5
6
7
| def copy_current_app_context(f):
from flask.globals import _app_ctx_stack
appctx = _app_ctx_stack.top
def _(*args, **kwargs):
with appctx:
return f(*args, **kwargs)
return _
|
@copy_current_app_context这个装饰器需要放到孙线程里面@copy_current_request_context的上面。完整的代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import threading
from multiprocessing.dummy import Pool
from flask import Flask, request, copy_current_request_context
app = Flask(__name__)
def copy_current_app_context(f):
from flask.globals import _app_ctx_stack
appctx = _app_ctx_stack.top
def _(*args, **kwargs):
with appctx:
return f(*args, **kwargs)
return _
def deep_func_runner(doc_id_list):
@copy_current_app_context
@copy_current_request_context
def deep_func(doc_id):
category = request.args.get('category', '')
url = f'https://www.kingname.info/{category}/{doc_id}'
print(f'开始爬取:{url}')
pool = Pool(3)
pool.map(deep_func, doc_id_list)
@app.route('/start_thread', methods=['POST'])
def start_thread():
@copy_current_request_context
def runner():
doc_id_list = [111, 222, 333, 444, 555, 666, 777, 888, 999]
deep_func_runner(doc_id_list)
job = threading.Thread(target=runner)
job.start()
return {'success': True, 'msg': '读取文章成功!'}
|
运行效果如下图所示,孙线程也正常启动了:
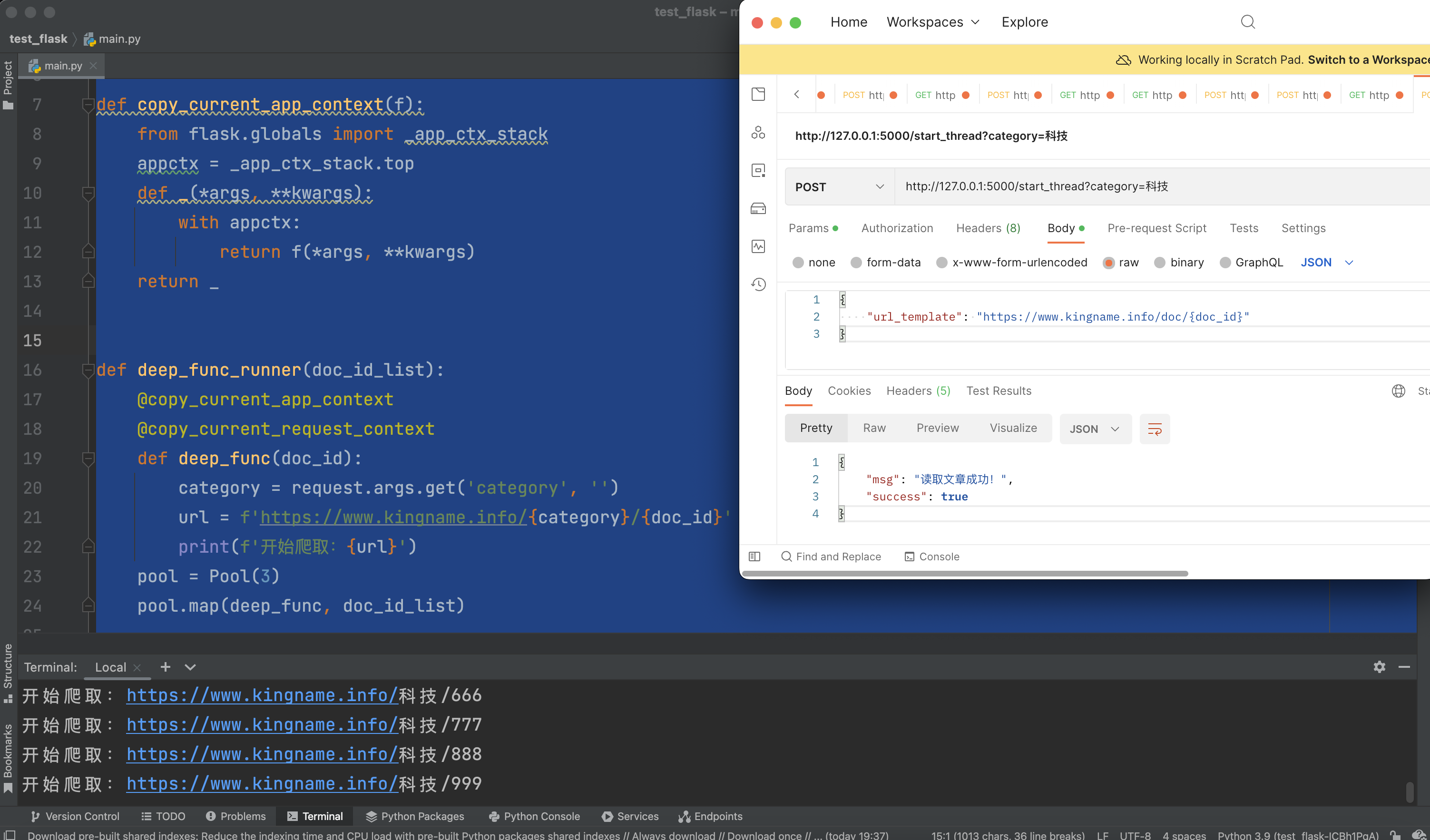
总结
- 非必要不在后端中创建子线程
- 创建子线程时,如果能把参数从外面传入,就不要让子线程自己去Flask的上下文读取
@copy_current_request_context需要装饰闭包函数,不能装饰一级函数- 嵌套子线程需要同时使用
@copy_current_app_context和@copy_current_request_context两个装饰器来装饰孙线程的闭包函数