ANTLR (ANother Tool for Language Recognition)是一个强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文档。它被广泛用于构建语言、工具和框架。ANTLR根据语法定义生成解析器,解析器可以构建和遍历解析树。
安装 以Linux系统为例,我们首先安装Java17
~ java -versionjava version "17.0.6" 2023-01-17 LTSJava(TM) SE Runtime Environment (build 17.0.6+9-LTS-190)Java HotSpot(TM) 64-Bit Server VM (build 17.0.6+9-LTS-190, mixed mode, sharing)随后我们下载antlr4的完整依赖包
wget https://www.antlr.org/download/antlr-4.13.0-complete.jar并把依赖包添加到Java的CLASSPATH中,将以下命令添加到~/.zshrc文件中
export CLASSPATH="/home/raymond/Desktop/antlr4/antlr-4.13.0-complete.jar:$CLASSPATH"之后我们就可以使用antlr4的Tool和TestRig了
~ java org.antlr.v4.ToolANTLR Parser Generator Version 4.13.0-o ___ specify output directory where all output is generated-lib ___ specify location of grammars, tokens files-atn generate rule augmented transition network diagrams-encoding ___ specify grammar file encoding; e.g., euc-jp-message-format ___ specify output style for messages in antlr, gnu, vs2005-long-messages show exception details when available for errors and warnings-listener generate parse tree listener (default)-no-listener don't generate parse tree listener-visitor generate parse tree visitor-no-visitor don't generate parse tree visitor (default)-package ___ specify a package/namespace for the generated code-depend generate file dependencies-D<option>=value set/override a grammar-level option-Werror treat warnings as errors-XdbgST launch StringTemplate visualizer on generated code-XdbgSTWait wait for STViz to close before continuing-Xforce-atn use the ATN simulator for all predictions-Xlog dump lots of logging info to antlr-timestamp.log-Xexact-output-dir all output goes into -o dir regardless of paths/package~ java org.antlr.v4.gui.TestRigjava org.antlr.v4.gui.TestRig GrammarName startRuleName[-tokens] [-tree] [-gui] [-ps file.ps] [-encoding encodingname][-trace] [-diagnostics] [-SLL][input-filename(s)]Use startRuleName='tokens' if GrammarName is a lexer grammar.Omitting input-filename makes rig read from stdin.可以在~/.zshrc中添加如下别名
alias antlr4='java org.antlr.v4.Tool'alias grun='java org.antlr.v4.gui.TestRig'后面就可以直接使用antlr4和grun命令了
一个简单的例子 我们从一个最简单的例子来看antlr4,创建一个名为Hello.g4的文件并输入如下内容
1 2 3 4 5 grammar Hello; // 语法名称,必须要和文件名称一样 r : 'hello' ID ; // 表示匹配字符串hello和ID这个token,语法名称用小写字母定义 ID : [a-z]+ ; // ID这个token的定义只允许小写字母,词法名称用大写字母定义 WS : [ \t\r\n]+ -> skip ; // 忽略一些字符
随后执行antlr4 Hello.g4 -o code命令将语法文件转化为Java的代码,具体生成的文件如下
HelloBaseListener.javaHello.interpHelloLexer.interpHelloLexer.javaHelloLexer.tokensHelloListener.javaHelloParser.javaHello.tokens之后执行命令javac *.java将所有的Java代码进行编译,编译完了之后执行命令grun Hello r -tree并输入相关文本内容,之后输入EOF(Linux上面是Ctrl + D)可以得到解析结果
➜ grun Hello r -treehello antlr<EOF>(r hello antlr)其中Hello是语法文件的名称,r则是语法的名称,-tree表示以lisp语法展示语法,我们也可以使用-gui选项展示语法树。
Visual Studio Code提供了antlr4的插件 ,可以方便的进行语法高亮和格式化等操作。IntelliJ Idea也提供了插件 ,具有快速生成代码、设置生成代码的参数以及查看语法树等功能。
使用antlr4构建一个计算器 首先我们创建一个Calc.g4文件,具体内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 grammar Calc; // 语法的名称,要和文件名称一致 calc: (expr)* EOF; // 一个或多个表达式 expr: BRACKET_L expr BRACKET_R // 圆括号 | (ADD | SUB)? (NUMBER | PERCENT_NUMBER) // 正负数字和百分数 | expr (MUL | DIV) expr // 乘除法 | expr (ADD | SUB) expr; // 加减法 PERCENT_NUMBER: NUMBER PERCENT; // 百分数 NUMBER: DIGIT (POINT DIGIT)?; // 小数 DIGIT: [0-9]+; // 数字 BRACKET_L: '('; // 左括号 BRACKET_R: ')'; // 右括号 ADD: '+'; SUB: '-'; MUL: '*'; DIV: '/'; PERCENT: '%'; POINT: '.'; WS: [ \t\r\n]+ -> skip; // 跳过空格换行等字符
执行命令antlr4 Calc.g4 -o code来生成代码,并将生成的代码放到code文件夹中。进入code文件夹,执行javac *.java命令编译代码。编译完代码之后,就可以执行测试程序了
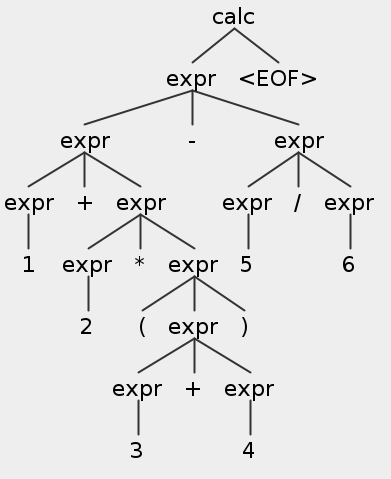
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ➜ grun Calc calc -tree 1 + 2 * (3 + 4) - 5 / 6 (calc (expr (expr (expr 1) + (expr (expr 2) * (expr ( (expr (expr 3) + (expr 4)) )))) - (expr (expr 5) / (expr 6))) <EOF>) ➜ grun Calc calc -tokens 1 + 2 * (3 + 4) - 5 / 6 [@0,0:0='1' ,<NUMBER>,1:0] [@1,2:2='+' ,<'+' >,1:2] [@2,4:4='2' ,<NUMBER>,1:4] [@3,6:6='*' ,<'*' >,1:6] [@4,8:8='(' ,<'(' >,1:8] [@5,9:9='3' ,<NUMBER>,1:9] [@6,11:11='+' ,<'+' >,1:11] [@7,13:13='4' ,<NUMBER>,1:13] [@8,14:14=')' ,<')' >,1:14] [@9,16:16='-' ,<'-' >,1:16] [@10,18:18='5' ,<NUMBER>,1:18] [@11,20:20='/' ,<'/' >,1:20] [@12,22:22='6' ,<NUMBER>,1:22] [@13,31:30='<EOF>' ,<EOF>,2:0] ➜ grun Calc calc -gui 1 + 2 * (3 + 4) - 5 / 6
第一个命令是生成Lisp风格的语法树,第二个命令是查看相应的token,第三个命令生成的语法树如下所示
通过Java代码调用生成的Lexer和Parser 还是以上面的例子为例,这次我们把词法分析和语法分析的内容分开来,分别创建CalcLexerRules.g4和Calc.g4文件,它们的内容分别如下
CalcLexerRules.g4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 lexer grammar CalcLexerRules; PERCENT_NUMBER: NUMBER PERCENT; NUMBER: DIGIT (POINT DIGIT)?; DIGIT: [0-9]+; BRACKET_L: '('; BRACKET_R: ')'; ADD: '+'; SUB: '-'; MUL: '*'; DIV: '/'; PERCENT: '%'; POINT: '.'; WS: [ \t\r\n]+ -> skip;
Calc.g4
1 2 3 4 5 6 7 8 9 10 grammar Calc; import CalcLexerRules; // 引入CalcLexerRules的词法规则 calc: (expr)* EOF; expr: BRACKET_L expr BRACKET_R | (ADD | SUB)? (NUMBER | PERCENT_NUMBER) | expr (MUL | DIV) expr | expr (ADD | SUB) expr;
创建这两个文件之后,执行命令antlr4 Calc.g4 -o code生成代码,antlr会自动把CalcLexerRules.g4的内容引入进来。在生成代码的code文件夹下创建Java文件CalcTest.java,并使用Java代码调用生成的Lexer和Parser类中的方法
CalcTest.java
1 2 3 4 5 6 7 8 9 10 11 12 13 import org.antlr.v4.runtime.CharStreams;import org.antlr.v4.runtime.CommonTokenStream;import org.antlr.v4.runtime.tree.ParseTree;public class CalcTest { public static void main (String[] args) throws Exception { CalcLexer lexer = new CalcLexer (CharStreams.fromString("1 + 2 * (3 + 4) - 5 / 6" )); CommonTokenStream tokens = new CommonTokenStream (lexer); CalcParser parser = new CalcParser (tokens); ParseTree tree = parser.calc(); System.out.println(tree.toStringTree(parser)); } }
添加了如上的类之后,执行命令javac *.java编译源码文件,之后执行命令java CalcTest来运行Java代码,得到结果如下
(calc (expr (expr (expr 1) + (expr (expr 2) * (expr ( (expr (expr 3) + (expr 4)) )))) - (expr (expr 5) / (expr 6))) <EOF>)运行结果和上面的grun的测试结果是一致的。
通过Visitor访问代码 上面我们使用Java代码调用了CalcLexer和CalcParser类,接下来我们实现一个Visitor,通过Visitor来访问我们所需要访问的AST节点,并执行计算器的计算功能。
这里我们使用Idea的ANTLR v4 插件来生成代码,上面的词法文件CalcLexerRules.g4不需要任何改变,而语法文件Calc.g4修改如下
1 2 3 4 5 6 7 8 9 10 11 12 13 grammar Calc; @header { package com.nosuchfield.antlr4; } import CalcLexerRules; // 引入词法分析文件 calc: (expr)* EOF # calculationBlock; expr: BRACKET_L expr BRACKET_R # expressionWithBr | sign = (ADD | SUB)? num = (NUMBER | PERCENT_NUMBER) # expressionNumeric | expr op = (MUL | DIV) expr # expressionMulOrDiv | expr op = (ADD | SUB) expr # expressionAddOrSub;
这里我们添加了@header标记,表示在生成代码的时候在代码头部生成我们所需要的内容,如上就是在代码头部放上了类的package声明。
我们还在每个语法后面使用井号#设置了一个标记名称,这个名称在生成Visitor代码的时候会生成相应名称的方法。此外我们还给表达式的参数设置了名称,例如sign、num和op,这样当生成代码的时候,我们就可以用参数num取到NUMBER或者PERCENT_NUMBER的值。
我们在Calc.g4文件上右击并选择Configure ANTLR选项
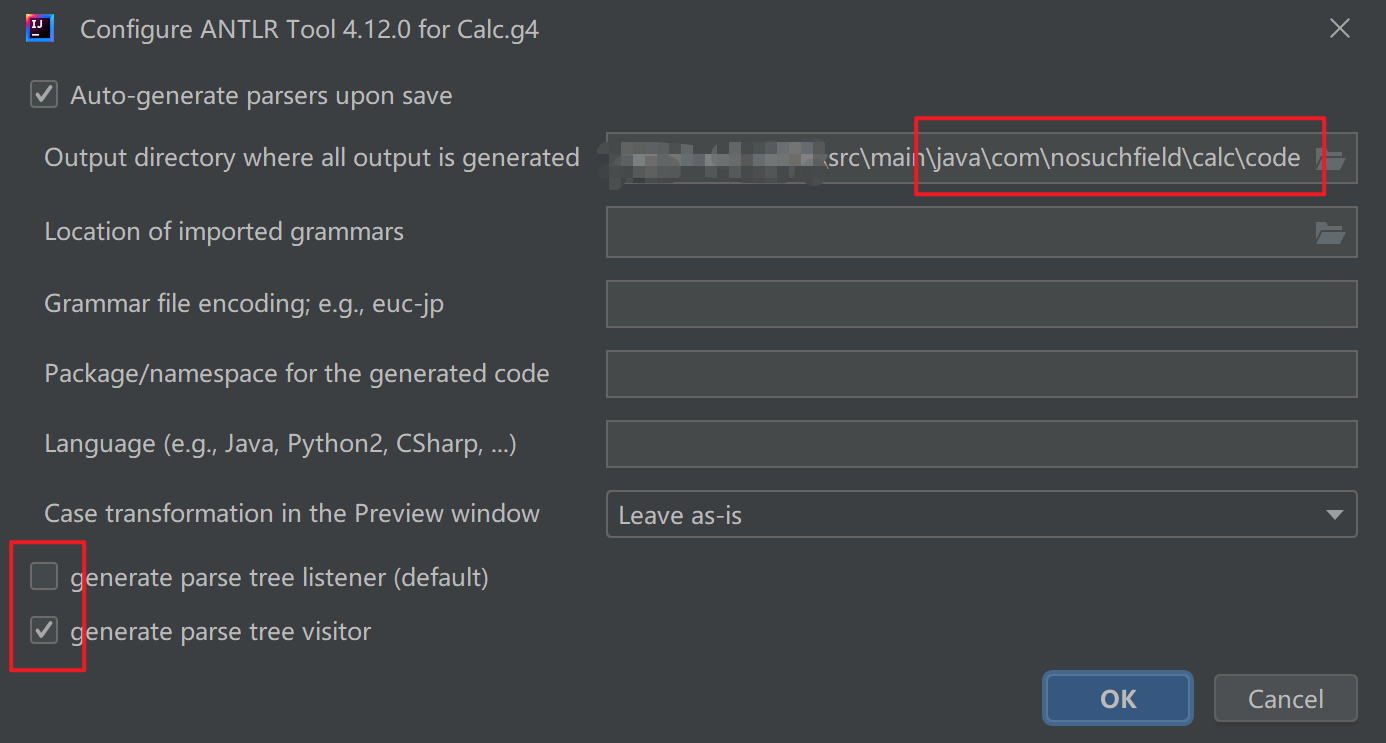
之后设置代码的生成目录为src/main/java/com/nosuchfield/antlr4,并且去掉生成listener的选项,同时选择生成visitor的选项
设置好了之后我们右击Calc.g4文件并右击选择Generate ANTLR Recognizer选项,即可在com/nosuchfield/antlr4文件夹下生成相关的代码
接下来我们自定义一个继承自CalcBaseVisitor类的CalculateVisitor,具体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 package com.nosuchfield;import com.nosuchfield.antlr4.CalcBaseVisitor;import com.nosuchfield.antlr4.CalcLexer;import com.nosuchfield.antlr4.CalcParser;import org.antlr.v4.runtime.Token;import java.math.BigDecimal;import java.math.MathContext;import java.util.Objects;public class CalculateVisitor extends CalcBaseVisitor <BigDecimal> { private static final MathContext MATH_CONTEXT = MathContext.DECIMAL128; @Override public BigDecimal visitCalculationBlock (CalcParser.CalculationBlockContext ctx) { BigDecimal calcResult = null ; for (CalcParser.ExprContext expr : ctx.expr()) { calcResult = visit(expr); } return calcResult; } @Override public BigDecimal visitExpressionWithBr (CalcParser.ExpressionWithBrContext ctx) { return visit(ctx.expr()); } @Override public BigDecimal visitExpressionMulOrDiv (CalcParser.ExpressionMulOrDivContext ctx) { BigDecimal left = visit(ctx.expr(0 )); BigDecimal right = visit(ctx.expr(1 )); switch (ctx.op.getType()) { case CalcParser.MUL: return left.multiply(right, MATH_CONTEXT); case CalcParser.DIV: return left.divide(right, MATH_CONTEXT); default : throw new RuntimeException ("unsupported operator type" ); } } @Override public BigDecimal visitExpressionAddOrSub (CalcParser.ExpressionAddOrSubContext ctx) { BigDecimal left = visit(ctx.expr(0 )); BigDecimal right = visit(ctx.expr(1 )); switch (ctx.op.getType()) { case CalcParser.ADD: return left.add(right, MATH_CONTEXT); case CalcParser.SUB: return left.subtract(right, MATH_CONTEXT); default : throw new RuntimeException ("unsupported operator type" ); } } @Override public BigDecimal visitExpressionNumeric (CalcParser.ExpressionNumericContext ctx) { BigDecimal numeric = numberOrPercent(ctx.num); if (Objects.nonNull(ctx.sign) && ctx.sign.getType() == CalcLexer.SUB) { return numeric.negate(); } return numeric; } private BigDecimal numberOrPercent (Token num) { String numberStr = num.getText(); switch (num.getType()) { case CalcLexer.NUMBER: return new BigDecimal (numberStr); case CalcLexer.PERCENT_NUMBER: return new BigDecimal (numberStr.substring(0 , numberStr.length() - 1 ).trim()) .divide(BigDecimal.valueOf(100 ), MATH_CONTEXT); default : throw new RuntimeException ("unsupported number type" ); } } }
在自定义的Visitor中我们实现了计算逻辑,可以看到,这里重写了类CalcBaseVisitor的5个方法,分别对应了语法文件中的5个标记以及它们定义的名称,而属性的定义如num则对应了方法中入参的属性。以expressionNumeric语法为例,它对应的了方法visitExpressionNumeric,我们可以通过方法入参ExpressionNumericContext取到sign和num属性,之后通过这两个属性来定义数字的值。而expressionMulOrDiv语法就是通过op取到运算符,之后对两边的数字根据运算符来进行相应的计算。
有了visitor之后,我们用一个测试类来测试计算结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.nosuchfield;import com.nosuchfield.antlr4.CalcLexer;import com.nosuchfield.antlr4.CalcParser;import org.antlr.v4.runtime.CharStream;import org.antlr.v4.runtime.CharStreams;import org.antlr.v4.runtime.CommonTokenStream;import org.junit.Test;import java.math.BigDecimal;import static junit.framework.TestCase.assertEquals;public class TestCalculate { @Test public void testFact () { String[][] sources = new String [][]{ {"1 + 2" , "3" }, {"3 - 2" , "1" }, {"2 * 3" , "6" }, {"6 / 3" , "2" }, {"6 / (1 + 2)" , "2" }, {"50%" , "0.5" }, {"100 * 30%" , "30.0" }, {"1 + 2 * (3 - 4) / 5" , "0.6" }, {"-8 + 8 * 2 - 8" , "0" } }; for (String[] source : sources) { String input = source[0 ].trim(); BigDecimal result = new BigDecimal (source[1 ].trim()); assertEquals(calculate(input), result); } } private BigDecimal calculate (String expression) { CharStream cs = CharStreams.fromString(expression); CalcLexer lexer = new CalcLexer (cs); CommonTokenStream tokens = new CommonTokenStream (lexer); CalcParser parser = new CalcParser (tokens); CalcParser.CalcContext context = parser.calc(); CalculateVisitor visitor = new CalculateVisitor (); return visitor.visit(context); } }
完整的代码位于https://github.com/RitterHou/test-antlr4
参考 ANTLR 4权威指南 语法解析器ANTLR4从入门到实践 从一个小例子理解Antlr4 Antlr4系列(二):实现一个计算器 ANTLR 使用——以表达式语法为例 Antlr4教程