我们知道,Python里面,json.dumps是序列化操作,json.loads是反序列化操作。当我使用json.dumps把一个字典转换为字符串以后,也可以使用json.loads把这个字符串转换为字典。
那么,有没有可能出现这样的情况:某个字典,使用json.dumps转换成了字符串s。但是当我使用json.loads(s)时,却会报错?
你别不信,我们来做一个实验。执行下面这段代码,打印出一段JSON字符串:
1 | import json |
运行效果如下图所示:

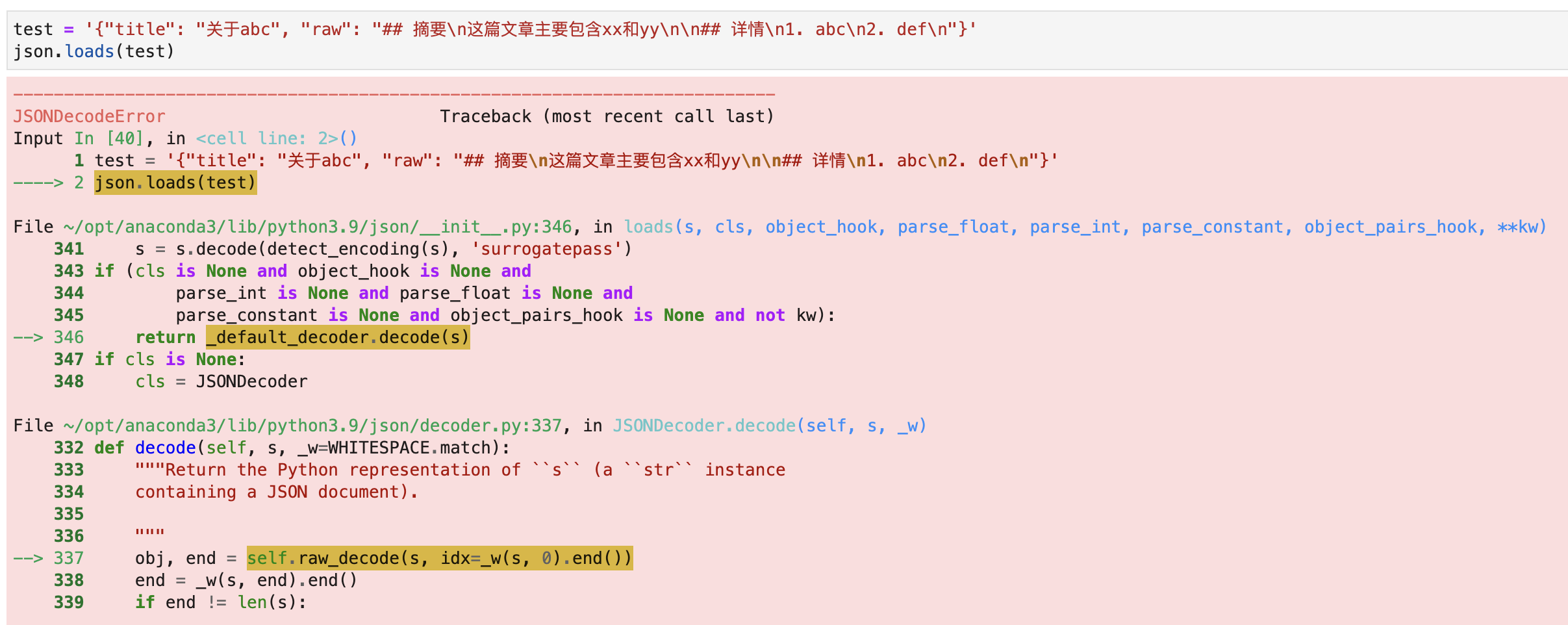
接下来,你把下面这个字符串复制到Python里面并使用json.loads解析:
1 | {"title": "关于abc", "raw": "## 摘要\n这篇文章主要包含xx和yy\n\n## 详情\n1. abc\n2. def\n"} |
运行效果如下图所示:
但如果你不是复制JSON字符串后赋值,而是直接把output反序列化,它又是正常的,如下图所示:

你以为这就很奇怪了?更奇怪的事情还在后面。现在把这段有问题的JSON复制到一个文件里面,使用Python来读取这个文本,如下图所示:
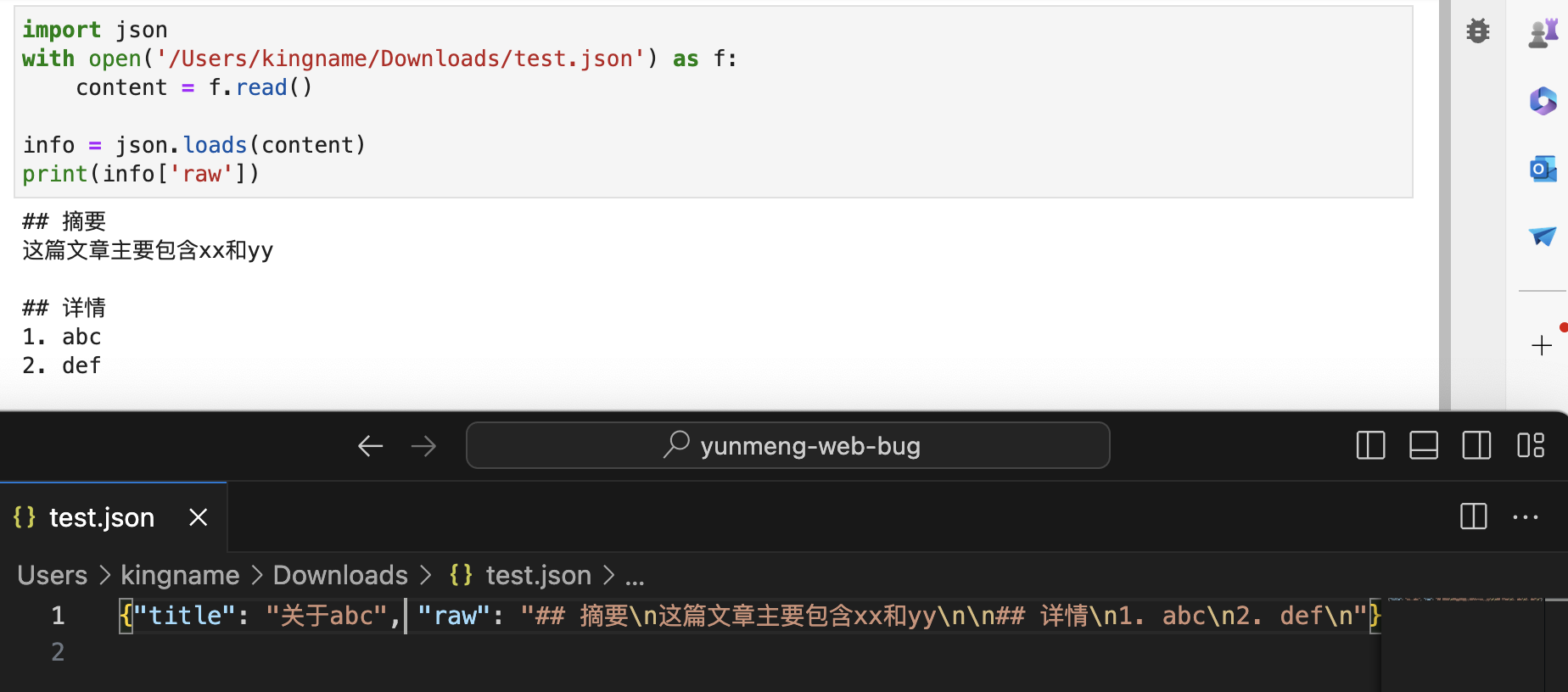
为什么现在又正常了?
如果你看过这篇文章:# 一日一技:怎么你的字符串跟我不一样,那么你可以试一试使用repr来检查一下他们有什么不同。在Jupyter里面,可以通过直接输入变量名的方式来检查。大家注意下图两个字符串的区别:

当我从文件里面读取JSON字符串时,字符串中的\n变成了是\\n,所以解析正常。但是当我直接把字符串赋值给变量时,换行符是\n,于是解析失败。
真正的关键,就是这个反斜杠。从文本文件里面读取的时候,所有反斜杠都是普通的字符串。读取文件以后使用repr查看,换行符就会变成\\n。但直接使用变量赋值的时候,\n就会变成真正的换行符号,这里的\是转义字符,不是普通字符串。
如果变量赋值时,手动使用双反斜杠,或者在字符串前面加个r,让反斜杠变成普通字符,那么这个JSON字符串又可以正常解析了。如下图所示:
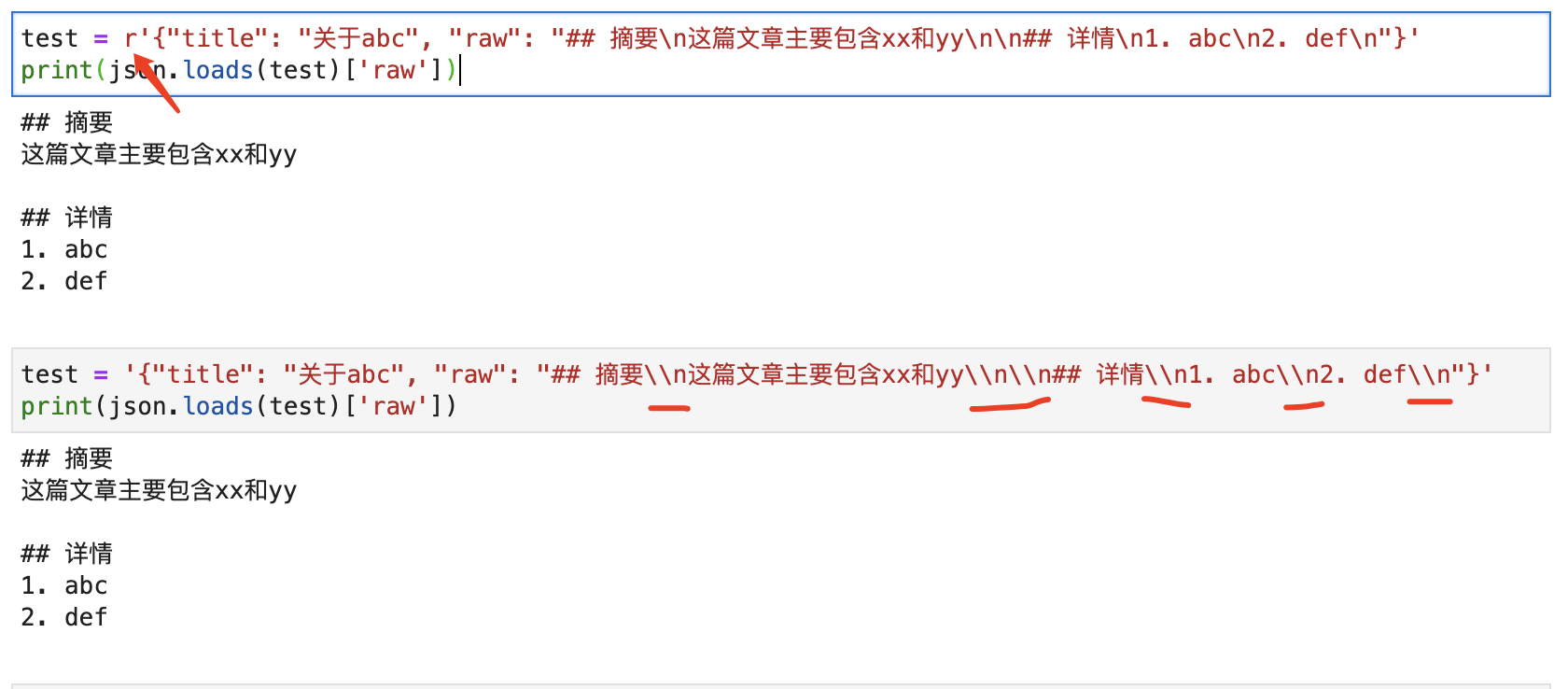
不仅是\n,任何一个JSON字符串里面包含了反斜杠,都会有这个问题。如下图所示:
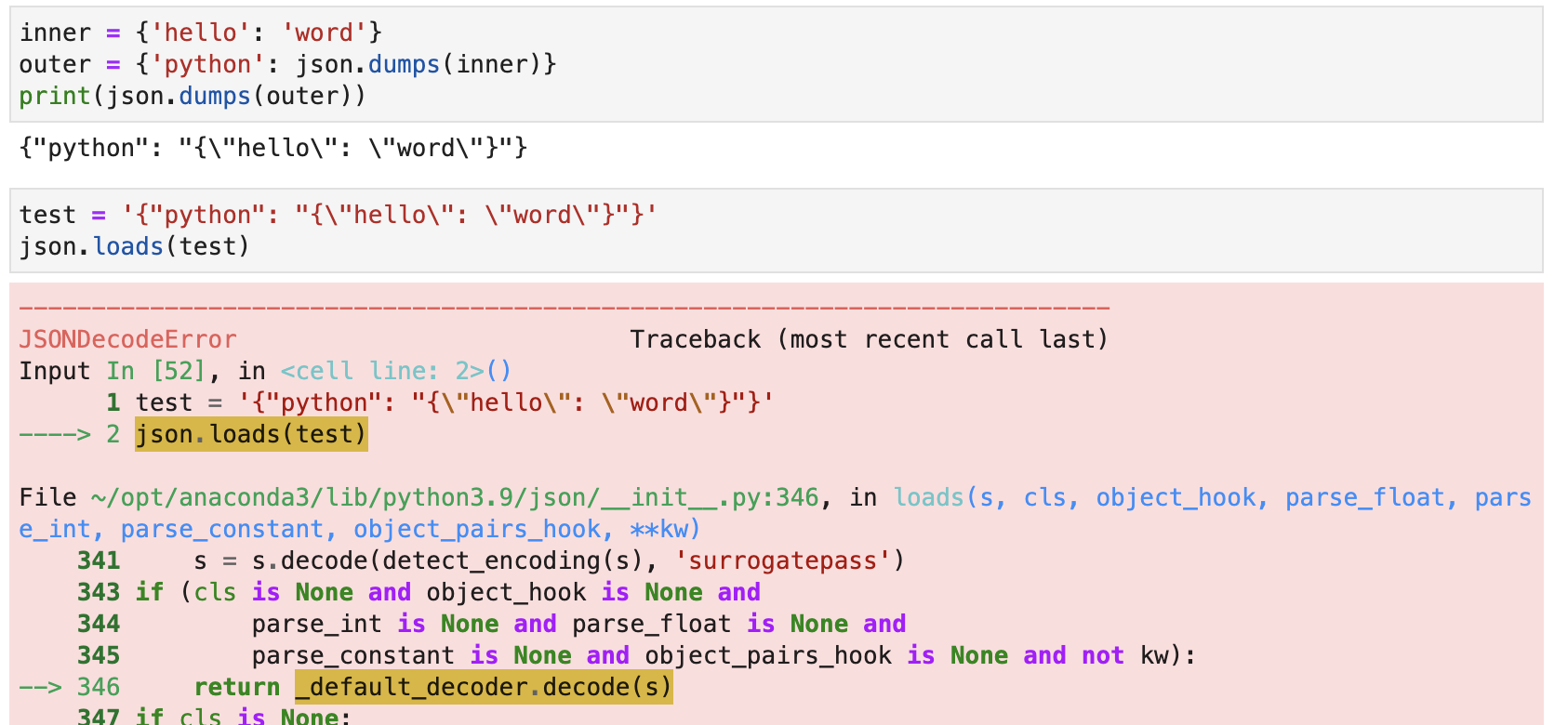
还是使用repr就能发现他们的差异:

所以,这个问题的本质原因,就在于当我们使用print()函数打印一个字符串时,打印出来的样子跟这个字符串实际的样子并不一样。所以当我们鼠标选中这个打印出来的字符串并hardcode写到代码里面,变量赋值时,这个字符串已经不是原来的字符串了。所以当有反斜杠时,就会出现报错的情况。
我知道有不少同学写代码时喜欢使用print大法来调试,那么一定要小心这个问题。当你定义一个字符串变量时,如果有字符串需要直接写死到代码里面,那么你需要注意反斜杠的问题。当字符串有反斜杠时,要不你就在定义的前面加上r。写成变量 = r'hardcode的字符串',要不你就把字符串先写到文件里面,然后用Python来读文件,获得这个字符串,从而规避掉反斜杠的问题。