引言
此篇文章分析paddlenlp中universal information extraction(UIE)对于事件提取的实现方式。
后续在没有特殊声明的情况下,UIE均代表paddlenlp的实现方式。
在这篇文章产业级信息抽取技术开源,为什么Prompt更有效? 中,作者突出UIE的优势:
- 多任务统一建模
- 零样本抽取和少样本快速迁移能力(基于Prompt的信息抽取)
而上述两点,基本也突出了目前深度学习算法的几个问题:
一、多任务统一建模
- 每个模型的建模方式都不同,希望在decoder(bert外的layers)更有效简单的解决问题。encoder(bert)端更多利用具备更深层次语义表达能力。
- 目前国内外也在研究这种多任务统一建模,在一个模型中输入不同的schema来得到相应的问题解。
二、零样本或者小样本
监督学习的特点,就是希望拥有更多的标注样本,数据是算法的上限,搞算法的希望越多越好。那这里又可以分为几部分来看:
- 目前的预训练模型,还过于单调。比如bert只能做纯文本,即使目前有多模态融合,但做的还远远不够,模型需要知识库!(这个暂时改变不了~)
- 零样本或者小样本微调,这种更符合实际情况,那这种更多考验预训练模型的能力。
扯了这么多,下面进入正文。
模型结构
1 | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. |
是不是非常简单!!!
不过对于ERNIE3的模型结构,如下:
1 | UIE( |
其中token_type_embeddings为4,另外引入了task_type_embeddings。
这地方我在网上也木有看到很多相关介绍,此处以后再补充。
介绍
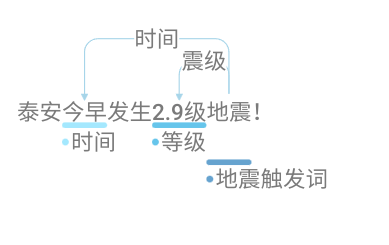
事件提取,是将事件的核心触发词和相关论元进行提取出来,构成结构化的数据。比如:
泰安今早发生2.9级地震!
| key | value |
|---|---|
| 触发词 | 地震 |
| 等级 | 2.9级 |
| 时间 | 今早 |
| … | … |
有了概念后,接下来我们介绍UIE的实现方式。
数据标注
UIE使用了doccano来进行数据标注,相关的使用示例请看开发使用,注意哦,作者这里doccano使用的版本是1.6.2,我一开始使用最新的,很多和文章对应不到一起。
导出后的样例:
 |
 |
|---|---|
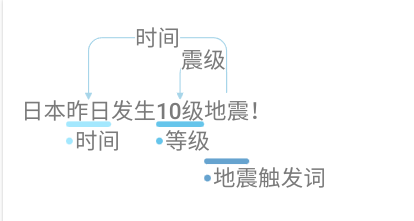
| {“id”: 5, “data”: “泰安今早发生2.9级地震!”, “label”: {“relations”: [{“id”: 12, “from_id”: 41, “to_id”: 39, “type”: “时间”}, {“id”: 13, “from_id”: 41, “to_id”: 40, “type”: “震级”}], “entities”: [{“id”: 39, “start_offset”: 2, “end_offset”: 4, “label”: “时间”}, {“id”: 40, “start_offset”: 6, “end_offset”: 10, “label”: “等级”}, {“id”: 41, “start_offset”: 10, “end_offset”: 12, “label”: “地震触发词”}]}} | {“id”: 6, “data”: “日本昨日发生10级地震!”, “label”: {“relations”: [{“id”: 14, “from_id”: 44, “to_id”: 42, “type”: “时间”}, {“id”: 15, “from_id”: 44, “to_id”: 43, “type”: “震级”}], “entities”: [{“id”: 42, “start_offset”: 2, “end_offset”: 4, “label”: “时间”}, {“id”: 43, “start_offset”: 6, “end_offset”: 9, “label”: “等级”}, {“id”: 44, “start_offset”: 9, “end_offset”: 11, “label”: “地震触发词”}]}} |
接着走数据转换,形成的train.txt和test.txt如下所示。
train.txt
1 | {"content": "泰安今早发生2.9级地震!", "result_list": [{"text": "地震", "start": 10, "end": 12}], "prompt": "地震触发词"} |
test.txt(此处对应的prompt都是有result_list的哦)
1 | {"content": "日本昨日发生10级地震!", "result_list": [{"text": "昨日", "start": 2, "end": 4}], "prompt": "时间"} |
可以看到,转换后的prompt由两部分组成:
- 实体词。比如
时间,等级,地震触发词。 - 由relation形成的prompt。即
实体词+的+relation。比如地震的时间,地震的震级,今早的时间,今早的震级,2.9级的震级,2.9级的时间。
训练
官方微调介绍。
这部分就一个点需要注意,就是数据构造方式,看下面:
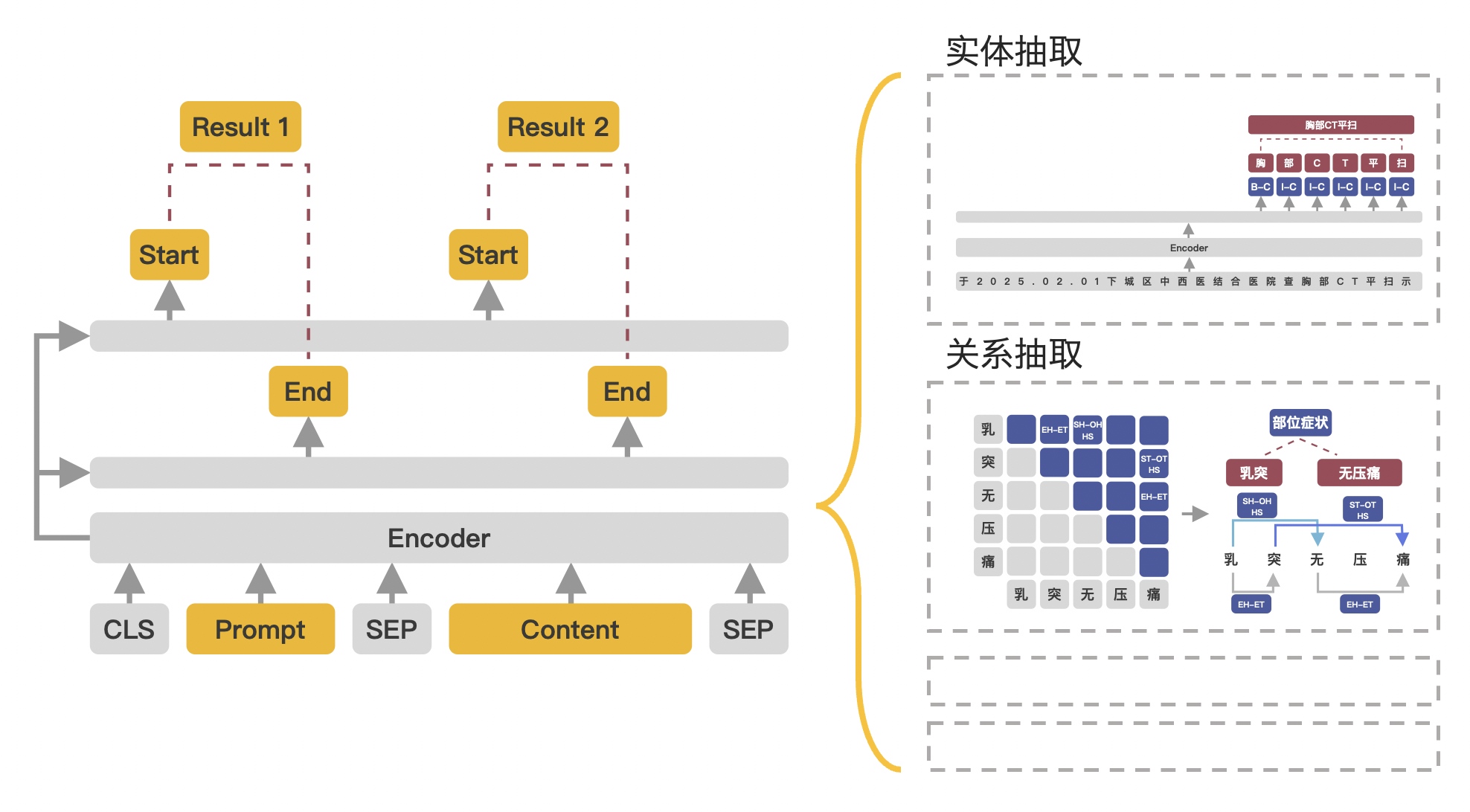
[CLS]prompt[SEP]Content[SEP]
Content对应原句。相关代码可看check和convert example。
到这里整体训练流程就明白了,那有一个问题,就是如何使用呢???
使用
从上面标注图片可以看到,所有的出发点都是来自地震触发词,那么就应该先预测触发词,然后根据这个触发词来找到与之相关的所有的论元,比如地震的震级, 地震的时间。中间通过一个的字来进行连接形成prompt。
那如何找与之相关的所有的论元呢???通过relation,那如何定义relation呢?通过schema!!!
下面看官方示例:
1 |
|
set_schema干了什么事呢?看官方代码SchemaTree,这里对schema形成了一个tree,构造完的示例如下:
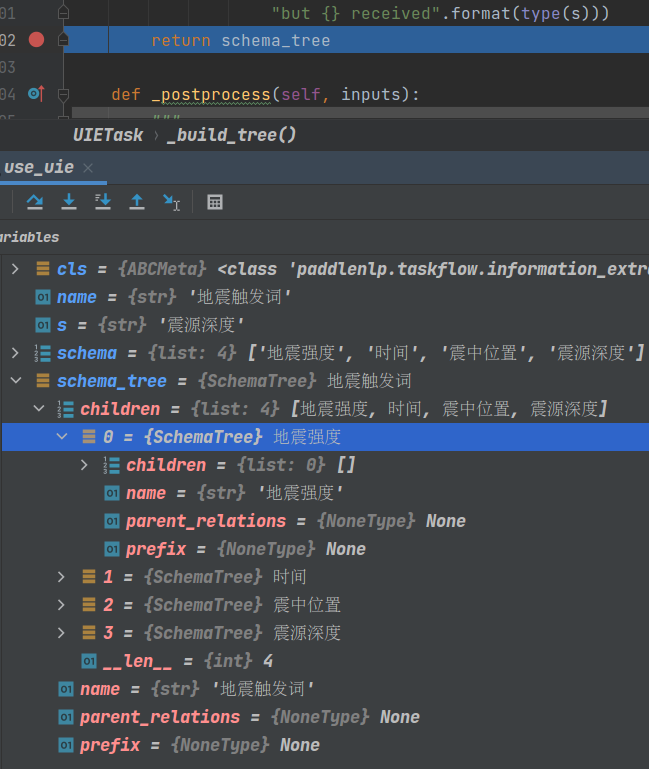
也就是说,通过遍历SchemaTree,预测顺序为:地震触发词,地震强度,时间,震中位置,震源深度。
对应的输入为:
- [CLS]地震触发词[SEP]中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。[SEP]
输出为:
地震
接着以地震作为触发词,构造接下来的prompt,核心哦!!
- [CLS]地震的地震强度[SEP]中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。[SEP]
- [CLS]地震的时间[SEP]中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。[SEP]
- [CLS]地震的震中位置[SEP]中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。[SEP]
- [CLS]地震的震源深度[SEP]中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。[SEP]
整理流程至此就已经非常明白了。
总结
事件提取作者这里使用关系抽取的标注方式来标注的,包括实体和对应关系,但是做了层转换,转换成prompt训练样本。具体做的事情分成两步:
1. 通过的字将触发词和关系做拼接。比如地震的时间
1 | {"content": "泰安今早发生2.9级地震!", "result_list": [{"text": "今早", "start": 2, "end": 4}], "prompt": "地震的时间"} |
2. 实体本身比如时间
1 | {"content": "泰安今早发生2.9级地震!", "result_list": [{"text": "今早", "start": 2, "end": 4}], "prompt": "时间"} |
预测的时候也是先找核心触发词,然后再构成prompt。
思考
语义角色标注任务能否通过这种方式来进行改进或者说能够通过语义角色标注的方式来减少UIE标注的标签数量?
比如:
泰安今早发生2.9级地震!
主体: 泰安
谓语: 发生
客体: 地震
时间: 今早
等级: 2.9级
…
核心论元就三个,主体、客体、触发词。然后围绕这三个,比如时间,地点等构成这个事件。
如果这样的话,流程就变成了如下方式:
- 提取出来一句话中所有的触发词。
- 围绕这个触发词,找到所有相关的论元。
- 根据需要搜索指定的触发词,从而返回与之相关的论元。
问题来了,那如何构造呢?
比如发生,发生什么?如果按照UIE的方式来讲,是地震触发词,简洁明了,不会有任何歧义,以地震作为事件主体来找触发词以及相应的论元。
如果换成发生的话,关系就变成了比如:
- 发生的主体
- 发生的客体
- 发生的时间
- 发生的等级
构造上没有任何问题~~~,只是觉得发生不够直接表达意思,但是形式上的确是可行的,这个需要试下就知道效果了,如果效果好,那对于标签构造的减少非常有帮助。
又比如我吃饭,她吃菜。,一个吃字,怎么根据这个吃字来构造数据呢?
- 吃的主体
- 吃的客体
那么这个吃就会提出两个主体和客体,所以这里我觉得把触发词所在的index也给传进去从而会对训练和预测时的效果有所提升。
而对于UIE呢,他的触发词估计就变成了吃饭触发词,所以就不会有这种歧义性的问题了,除非一个句子有多个吃饭事件。。。这个概率就会极低了。。。
思考总结
对于上述思考,UIE的做法很直接,定义地震触发词,表明了输入一句话那我就是要提取和地震相关的论元,先提取地震触发词(同时也作为prompt输入),然后接着构造prompt提取其他相应的论元。
整个过程直接明了,歧义与理解困难上都非常低。另外对于不同的事件,其实它都是有对应的主体,比如可以定义海啸触发词和泥石流触发词。
即: 触发词即事件!!
而对于语义角色标注呢,触发词更倾向的是动词,它属于格语论。以动词为中心所展开的事件论元。那么它所对应的主体或者客体才是事件。