
让YOLOv11秒懂口罩/手套/防护服:CPPE5数据集实战指南
目标检测的事儿,咱们不绕弯子了。这篇文章就是教你一件事: 3分钟教你用YOLOv11检测口罩、手套、防护服,工业、医疗、安防一网打尽。 这篇文章不会深究模型原理,而是手把手带你跑通全流程训练与推理,使用的数据是HuggingFace上经典的CPPE-5数据集,涵盖多种个人防护装备(PPE)目标检测任务。 ✳️什么是 CPPE-5?这里采用rishitdagli/cppe-5公开数据集,含以下5类标签: 类别英文 中文含义 Coverall 防护服 / 连体衣 Face_Shield 面罩 / 防护面屏 Gloves 手套 Goggles 护目镜 Mask 口罩 共1000张图片,真实复杂场景,适合目标检测实战测试。 🚀 快速开始(带你跑通) 1. 下载数据集123wg..
更多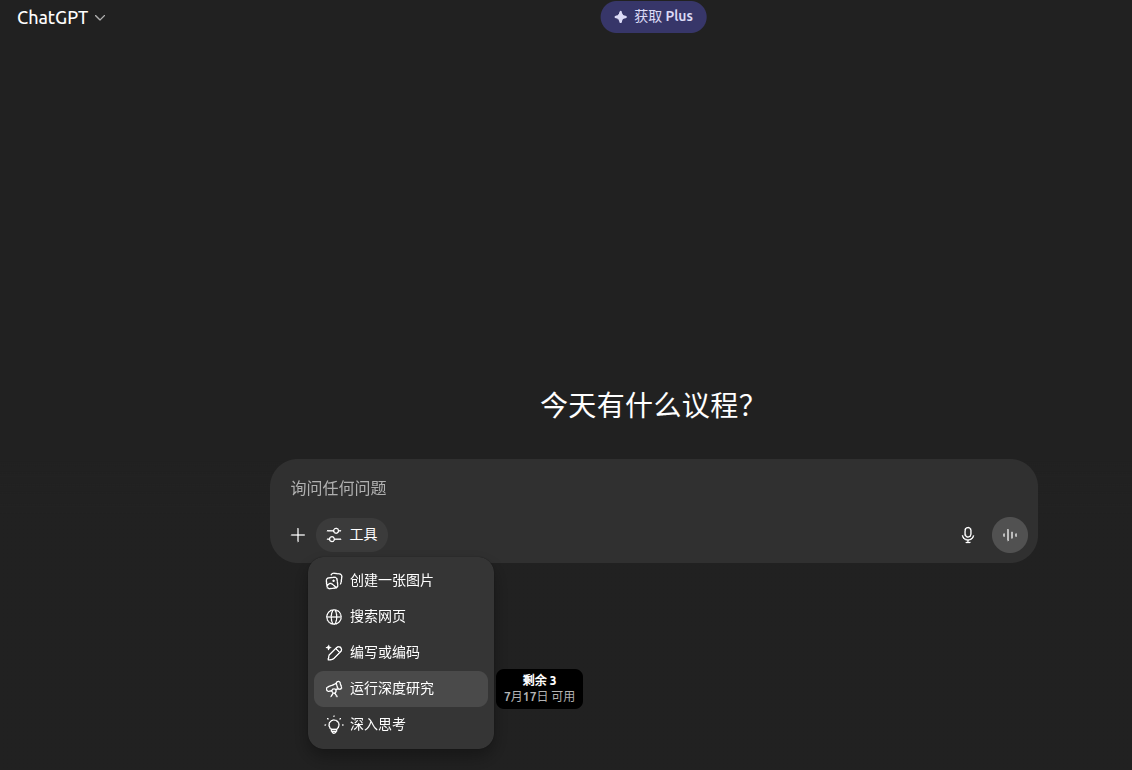
从LLM自主探索到LangGraph流程驱动:深度研究的两种范式
1. 什么是Deep Research?为什么它值得关注Deep Research是一种面向“深度研究”任务的新型AI Agent能力。它不再只是被动地回答提问,而是具备主动探索、综合整合信息、产出可信且可追溯答案的“研究员式”智能。 简而言之:它让AI真正参与“调研”而非“聊天”。 下图展示了ChatGPT与Grok所提供的深度研究功能界面: ChatGPT运行深度思考 Grok DeepSearch 2. Gemini+LangGraph:一个全流程深度研究的范例gemini-fullstack-langgraph-quickstart是Google Gemini官方推出的开源示例,展示了如何基于 LangGraph+Gemini API构建一个具备“多轮推理”能力的AI Agen..
更多
使用langgraph打造AI服务编排
LangGraph是什么?LangGraph是LangChain团队推出的流程编排工具,它基于状态机的思想,结合LangChain的Agent与Tool架构,允许我们以图的形式组织多个AI组件、服务调用、条件判断与上下文流转。 为什么只是给大模型Tools还不够?我们真正需要的是“编排”在大模型Agent系统中,一些入门教程或框架(包括LangChain早期版本)会鼓励用户把各种工具注册给模型,然后说: “你可以调用这些tools,自己决定该怎么完成任务。” 这听起来像是Agent的“智能体现”,但实际上它把复杂性全推给了语言模型本身,代价非常高。 低参数量模型在自主决策上效果不好。 流程逻辑是隐式的,决策都放到了prompt和模型权重中,而我们需要的是可靠、可复现、可维护的系统。从完全黑盒变成工程..
更多《推荐系统实践》
从某种意义上说,推荐系统和搜索引擎对于用户来说是两个互补的工具。搜索引擎满足了用户有明确目的时的主动查找需求,而推荐系统能够在用户没有明确目的的时候帮助他们发现感兴趣的新内容。基于用户行为分析的推荐算法是个性化推荐系统的重要算法,学术界一般将这种类型的算法称为协同过滤(Collaborative filtering)算法。顾名思义,协同过滤就是指用户可以齐心协力,通过不断地和网站互动,使自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。用户行为分类用户行为在个性化推荐系统中一般分两种——显性反馈行为(explicit feedback)和隐性反馈行为(implicit feedback)。显示反馈行为是用户主动做的,比如给视频点赞、给书籍打分等等;隐式反馈行为的代表就是用户浏览页面..
更多
一日一技:如何实现临时密码?
我买的房子今天交房了。开发商配的门锁是某品牌的智能门锁,它可以使用指纹开锁,也可以使用密码开锁。在使用手机跟门锁配对以后,可以远程在手机上生成临时密码。临时密码只能使用1次,并且在生成的30分钟内有效。这个功能可以方便装修人员进出又不用担心泄露密码。因为新房子还没有通网,所以门锁肯定是无法连接互联网的。而装修人员给我打电话要临时密码时,我在公司,离家几十公里外,门锁也不可能跟手机通信。那么问题来了,门锁是怎么验证这个临时密码合法的?今天我一直在想这个问题,目前有一些思路,但无法确定。所以发出来跟大家一起讨论一下它的实现方法。已知:手机App只有第一次跟门锁配对时,会通信,之后就完全不会有任何通信门锁无法连接外网无论我在任何地方,手机上都能生成临时密码。门锁输入临时密码就能解锁临时密码只能使用一次,之后就会..
更多
aha-moment根源之高质量推理数据
前言过年期间,deepseek-R1火出了圈,各家媒体都在狂轰乱炸宣传deepseek,以及技术圈各种文章来介绍其实现原理。那这里仅从“高质量数据”角度作为入口来阐述对其的理解。 为什么需要高质量数据集?这不废话吗,没有高质量数据集怎么训练高质量模型。对的,这个回答完全没有问题,从目前大模型能力角度来讲,其回答已经持平或者某些方面已经高于绝大多数人的认知,这是其一。其二是在垂直领域或者具体业务,更多、更贴和的真实数据会给模型带来更好的效果以及降低一个量级的参数量,这也是下游能够应用大模型的主要原因。 那其三呢,我们无法构建一个真实环境,来给大模型进行交互,让其不断试错和学习,所以我们需要将人类对于各种问题的理解以及自然规律等等,用其简单明了直接的方式告诉大模型,这个就是答案,所以出现了SFT。其他文章在介..
更多
Llava简述
介绍Llava是一个多模态大模型,本文以如下代码大致介绍下。 1234567891011121314151617181920212223242526import osos.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # noqaimport requestsfrom PIL import Imagefrom transformers import AutoProcessor, LlavaForConditionalGeneration, LlavaConfigconfig = LlavaConfig.from_pretrained("llava-hf/llava-1.5-7b-hf")model = LlavaForConditionalGenera..
更多
多模态-繁体不同排版
前言最近有个需求,能够对不同排版格式的繁体信息进行抽取,所以从传统的版面分析+文字检测、识别+阅读顺序+NLP到现在发展的多模态大模型综合调研。 此处以文字区域检测+识别做个demo,来直观感受多模态大模型的结果。 总结 LVLM(large vision language model)相比LLM至少落后一代。 LVLM相比LLM更具有挑战性。1)多模态信息融合。2)从结果上看,训练时长与loss下降速度。3)高清图片,针对不同尺寸的图片,原来例如CLIP使用固长224*224像素来patch,Qwen-VL-Chat使用448,MiniCPM-V-2_6采用动态计算切分方式,来更好贴近原始SigLIP的输入尺寸,减少缩放后图片质量的损失。以及引入query embed来减少高清图片输入长度过长问题,看P..
更多graphviz-networkx-画图
1. graphviz docker12345678910FROM ubuntu:18.04ENV LANG C.UTF-8WORKDIR /codeCOPY . .RUN sed -i s@/deb.debian.org/@/mirrors.aliyun.com/@g /etc/apt/sources.list && \ sed -i s@/security.debian.org/@/mirrors.aliyun.com/@g /etc/apt/sources.list && \ apt-get clean && apt-get update && apt-get install -y python3-pip python3-dev bui..
更多
多模态-ViLT
最近面试了一北京候选者,之前使用电子病例以及CT图像两种模态信息,训练ViLT多模态预测模型,提高肺结节良恶性预测准确率。正好我对多模态如何对齐也比较感兴趣,以Transformers-Tutorials提供的代码为例,来看下其内部是如何实现的。数据集我没有从VQA下载,太大了,这里也强烈安利huggingface提供的lmms-lab/VQAv2 dataset。 剩下就改下VQADataset部分,其他保持不变。 这里记录比较有趣的几个点。 1. text和image如何对齐?答案:在第二维对齐。 具体来说,text部分使用的是BertTokenizer,max_position为40(所以如果有长文本,这里就坑了),假设batch_size为4,text embedding出来后就是(4, 40, ..
更多