分享一些平时我用到的常用命令, netstat、ffmpeg、rsync、mysqldump、dig、ip、iptables、
磁盘相关,挂载信息,格式化网络相关设置代理服务器查看网络连接情况, netstat,端口使用 lsof查看域名解析情况, dig nslookupip工具 查看网卡,查看路由表,代替ifconfig 和 routeiptales ip封禁和流量转发mysql 相关语句和命令语句,添加用户,设置权限,表空间mysqldump,备份bash 一些语法条件判断, if循环 while其他工具rsync同步文件,一般系统自带ffmpeg 视频剪辑,裁剪打码字幕倍速合并等,真神,这个需要额外安装进程信息查看, ps, pmap, lsofJAVA 内存分析, jcmd jstat jmap jhat分享一些我平时用到的常见命令都是系统自带命令,其实命令很简单,但是一般也不记,属于要用时也要查一下的也可能是年纪大了,..
更多
使用 Cloudflare Workers自建完全免费Docker镜像服务
使用Cloudflare Workers自建完全免费Docker镜像本方法 不需要服务器 也不需要域名自月初docker镜像被封禁之后,国内的镜像源也同步都停掉了。国内服务器拉取镜像变得完全不方便。目前有几种方法挂代理, 给配置文件增加代理proxy配置;自建转发服务器,配置文件增加registry-mirrors镜像源:自建服务器,给nginx配置反向代理, 如crproxy;蹭Cloudflare Workers免费资源,手动写请求转发代码,如cloudflare-docker-proxy最终我选择了Cloudflare Workers方式,因为这个方法完全不需要服务器,甚至也不需要域名,只需要注册一个cloudflare帐号就能用。我真的服了cloudflare也是太大方了,真的什么都给大家免费用。..
更多
Shadowsocks with v2ray-plugin for Doprax
使用Doprax搭建免费的Shadowsocks服务。有现成的V2ray for Doprax方案。但是我一直是用Shadowsocks的,也不想换客户端。而且一看v2ray,和Shadowsocks相比,真的太复杂了,配置一大堆,看了文档也非常混乱,一比较就完全放弃。于是想研究ss能不能也整一个。先说结论:使用v2ray-plugin插件将shadowsocks流量伪装成http协议,穿透Cloudflare网关,使用隧道转发到服务端。客户端使用安装了对应插件的客户端连接到服务端。并且可以支持v2ray客户端例如V2rayU连接本来想尝试使用simple-obfs,因为ios的免费客户端上基本上内置这个,后来在成功实现v2ray-plugin方式之后,又继续研究了很久,发现由于Cloudflare的影响..
更多Facebook的类ChatGPT大语言模型LLaMA模型下载地址
分享一个 前几天泄露出来的Facebook的AI语言模型,LLaMA,总共220G运行有官方和第三方的运行示例,里面没有模型下载地址,官方途径是需要邮箱申请。官方例子: https://github.com/facebookresearch/llama内存优化版: https://github.com/tloen/llama-int8 据说只要3090可以运行,作者4090测试完成计算优化版: https://github.com/markasoftware/llama-cpu CPU可以运行,但是需要32G内存下载下载的脚本地址来自这里, https://github.com/shawwn/llama-dl下载速度还行,下了一个晚上, 我已经下载好了。下载链接导出来之后,百度云离线下载不了,..
更多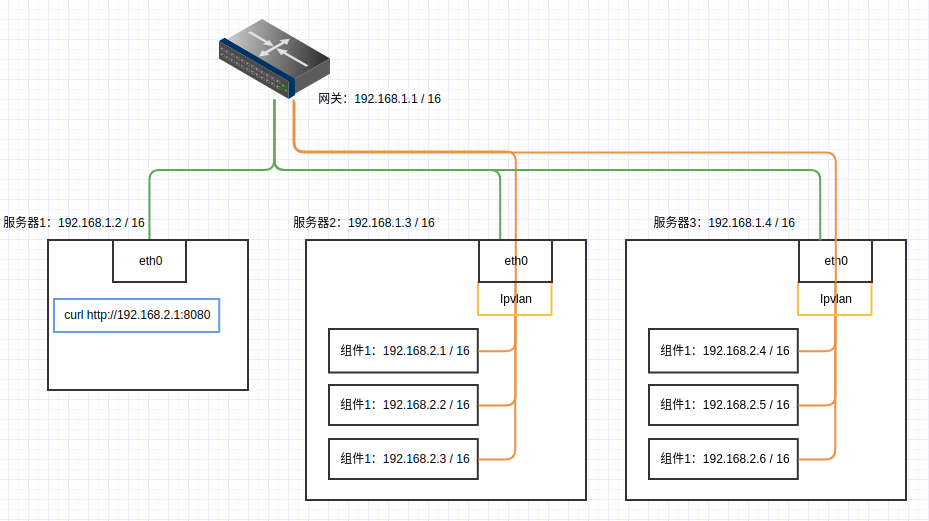
自建大数据分析集群
老项目老项目了这些都是。大部分都是十年前就出现的工具。感叹真是经久不衰。最近服务开发中,为了节约成本,弄了两个服务器,希望搭建一套数据分析平台,验证项目流程。查了很多资料对这些平台的搭建都非常简略,过程也是复杂,对新人很不友好,我也算是整理了一下相关的内容。简化服务搭建流程。得益于Docker的容器化,整个数据平台搭建起来非常方便整个过程里面,包含以下工具的搭建:HDFS,主要是用来存储数据YARN,提供资源调度,实现MR计算Hive on MR,基于MR的SQL引擎, 性能堪忧。也有基于Spark的,但是没有找到版本对应的公共镜像,就放弃了Spark Standalone,分布式计算框架,有基于YARN或者HIVE的版本,为了依赖纯粹,使用了独立集群Kafka on Kraft,为了依赖纯粹,使用了Kr..
更多关于前端播放RTSP直播流画面方案研究
最近参与一个项目,硬件设备从摄像头采集视频直播流程,分析结果,与画面一起展示在前端页面上。环境: 硬件设备是一个集成了显卡的开发板,可以运行ubuntu,算法部分是用python写的,前端设备在同一个局域网。摄像头为海康威视的普通网络摄像头。关于视频画面播放的问题, 查了一下,前端目前不能直接播放rtsp视频流。调研了市面上有几种方案。ffmpeg视频转格式为frag_keyframe的mp4视频流,也就是视频流切片, 使用websocket转发流,前端使用Media Source Extensions渲染普通的mp4格式无法播放,需要转成fragment mp4即分片的mp4, 目前这种格式浏览器支持度差,这个方案也没测试成功。ffmpeg视频转格式为flv视频流, websocket转发流,前端使用f..
更多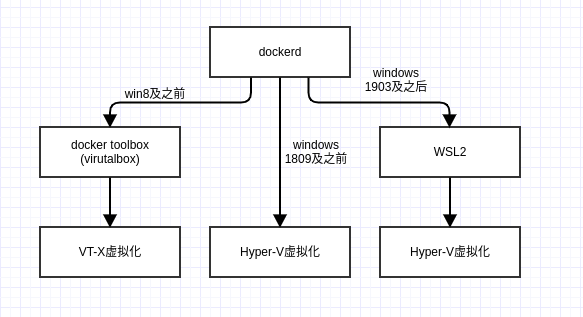
云主机WindowsServer无GUI上如何安装Docker环境
分享一个在云主机上的无桌面环境的Windows Server上,不安装Docker Desktop,运行Docker。系统要求Windows2016及以上即可。起因前段时间,一朋友委托我研究一个技术方案。说他技术这边搞了一个分布式的Windows程序,依赖Docker环境,现在只能在电脑上安装,非常不方便维护,扩容起来也很麻烦。于是我也花了差不多花了一百多块钱,一个周末,买了一个云主机来研究研究。太长不看利用DOCKER_HOST参数将windows的docker客户端通过tcp方式连接到wsl内的dockerd服务参数字段daemon-socket-option说起来是很简单,第一次操作起来还是遇到了很多问题。研究现在因为已经知道结论了,所有写起来理所当然,实际上花了大把时间才得到这个结局。众所周知,W..
更多
基于以太坊却不上链的抽奖服务,是不是有一点可疑。
前言本文是随笔,记录了一次基于以太坊的抽奖服务的方案讨论。从常规的智能合约的实现方案,到最终改用不上链的实现,主要是分享一下思路,包含了一点不看也没事的技术细节,以及一点区块链相关的内容。因为抽奖主题的区块链开发入门文章已经泛滥了,所以文章尽可能避免变成教程。背景之前一位做论坛的同学说他们那个论坛经常会做一些活动,抽奖什么的。如何让用户能感受到公平公正,让大家信任。之前一个的办法是在指定时间录视频,并且边上放个北京时间,表示这个是准时开奖没有作弊。这个和澳门最大线上赌场异曲同工,边上搞台电视放新闻的直播,令人信服。但是总一直这样也不行,我们可是搞技术的,而且这种方式扩展性太弱。于是他们想做一个公正公开可信任,简单易用易理解的抽奖系统,选定的方案是区块链。我听了觉得很有意思,而且公正公开不可变,区块链太合适..
更多使用telegram bot实现的报警工具
个人的程序的报警很多人都用的 server 酱 之前我也是用这个的 个人使用的时候确实非常方便 但是因为 server 酱是基于微信公众号的 所以如果要发送个多人 或者分组发送消息 还是不是很方便 于是自己开始准备用 wepy 来做这个工具 结果发现貌似itchat接口被封掉了 issues 不得不寻求其他的方法最终找到了telegram 不得不说 虽然是聊天工具 但是对开发者还是相当友好的 各种接口都有提供 而且提供了一个非常强大的机器人系统 可以进行各种操作 而且流程非常简单 创建自己的机器人搜索BotFather 这个帐号 然后发送/start开始对话 BotFather是telegram的一个机器人帐号 用来管理所有用户创建的机器人 开始对话之后 会提示你进行各种操作 来创建和管..
更多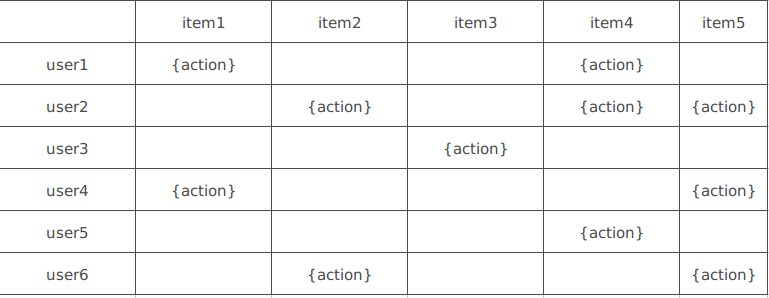
关于协同过滤的推荐算法
这个主题想写已经很久了 自从换了新部门之后 也没有写过前端 因为部门总共6个人 有两个前端 然后后端和算法人员不足 因为我技术比较强 就被安排到了新的任务 老大和我说 做数据和算法比前端有前途 话是这么说的 但是我从大一起开始写前端写了这么多年 突然让我去写其他的 那我前端领域的优势就没了啊 而且就算我继续算法这些写个三年四年 到时候仍然随便一个刚刚毕业的专门研究算法的就能把我干趴下了好吗 毕竟我也没怎么专门研究过这些东西 不过既然部门有任务安排 那只能写了 这段时间经历了 python从入门到精通 hbase从入门到精通 hadoop从入门到精通 什么kafka 什么zookeeper 让我作为一个前端大开眼界 有点偏主题了。。。。我的主要工作有三点..
更多