使用Elasticsearch分析腾讯云EO日志
腾讯云EO可以查看一些指标信息,但是更加详细的信息需要我们下载离线日志自行分析。获取日志下载链接腾讯云会将日志打包为.gz格式,解压后文件会包含多行,每一行都是一个JSON格式的数据,对应一条EO的请求日志,日志格式可以参考腾讯云文档。我们可以批量获取最近一个月的日志下载链接之后复制所有链接并保存到urls.txt文件中。启动Elasticsearch集群我们参考官方文档使用docker来启动集群,首先下载.env和docker-compose.yml,之后在.env文件中设置es和kibana的密码都是123456,然后设置STACK_VERSION=9.2.3。考虑到数据量比较大,可以提高容器的内存大小,我这里设置了一台8G。12345678910111213141516171819202122232425..
更多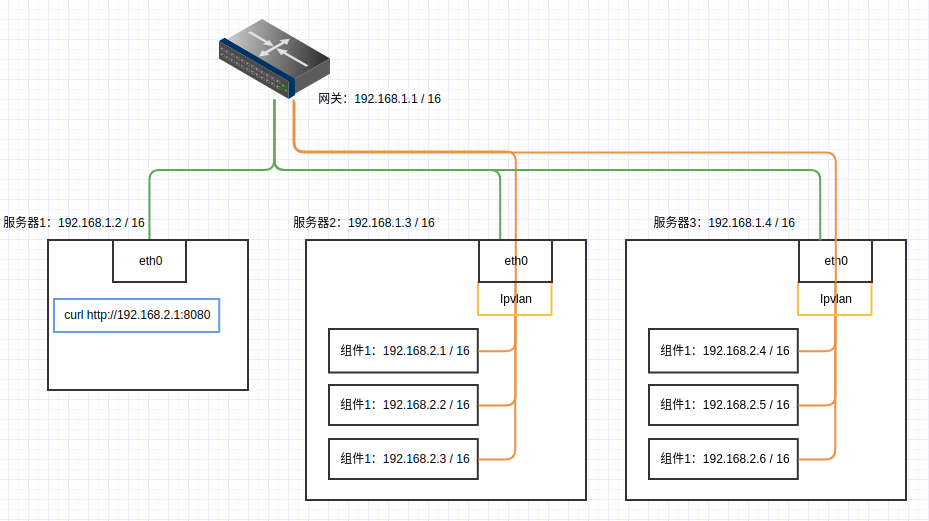
自建大数据分析集群
老项目老项目了这些都是。大部分都是十年前就出现的工具。感叹真是经久不衰。最近服务开发中,为了节约成本,弄了两个服务器,希望搭建一套数据分析平台,验证项目流程。查了很多资料对这些平台的搭建都非常简略,过程也是复杂,对新人很不友好,我也算是整理了一下相关的内容。简化服务搭建流程。得益于Docker的容器化,整个数据平台搭建起来非常方便整个过程里面,包含以下工具的搭建:HDFS,主要是用来存储数据YARN,提供资源调度,实现MR计算Hive on MR,基于MR的SQL引擎, 性能堪忧。也有基于Spark的,但是没有找到版本对应的公共镜像,就放弃了Spark Standalone,分布式计算框架,有基于YARN或者HIVE的版本,为了依赖纯粹,使用了独立集群Kafka on Kraft,为了依赖纯粹,使用了Kraft..
更多