ChatGPT Free账号没有GPT-5的选项
8月初已经收到GPT5推出的消息。打开ChatGPT一看左上角的选项里没有GPT5的选项。但是询问GPT,它会回答现在就是GPT51我这边已经是 GPT-5 Thinking,可以直接继续帮你。目前用的是free账号,推测OpenAI给限额的GPT-5使用。看了YouTube的视频,Plus或者Pro账号就能直接切换到GPT-5再等等,等GPT-5普及到free账号
更多
ChatGPT学习模式(study mode)介绍和体验
ChatGPT学习模式(study mode)介绍和体验近期,ChatGPT推出了学习模式(study mode)。不管是iOS、安卓、web或者桌面端都可以使用。免费版本、Plus、Pro版本都可以使用。这个模式也支持中文。你可以把学习模式当做是一个在线的全科老师,此模式具备交互功能,可以一问一答。或者把ChatGPT当做是“私人学习助手”,家教老师,题库练习机,学习规划师,英语对话伙伴,地理百科全书等等。这个模式重点在于交互、问答和引导。如果要ChatGPT一次性出一份练习题,可以用普通模式。下面我们来试一下学习模式(网络不好的情况下请全局开🪜)先打开ChatGPT的学习模式,本文以网页版为例,工具 - 研究与学习做题练习模式先告诉ChatGPT自己的情况,然后要求出对应科目的题目。例如作为一个小学2年级..
更多2025年AI聊天工具推荐与对比:ChatGPT/Gemini/DeepSeek/豆包
本文对比2025年主流AI聊天工具(ChatGPT、Gemini、DeepSeek和豆包)的核心功能、使用体验、价格方案及适用场景,帮助读者选择最适合的人工智能助手。以下各工具要能和用户进行自然的交流互动,能理解用户的问题、回应用户的需求,不管是聊天、解答疑问还是提供帮助,都可以通过对话来实现。本文持续更新中1. ChatGPT各种对话,解答问题,提供建议,以及协助创意工作。我能处理文本、分析信息,还能生成图像或帮助你修改图像可使用Google、Microsoft、Apple账号登录。可用免费账号进行体验,使用GPT-4o mini。Plus版本$20每月,深度研究、多个推理模型(o4-mini、o4-mini-high 和 o3)以及 GPT-4.5 研究预览版。Pro版本$200每月,访问 GPT-4.5 ..
更多
ChatGPT-Mirror部署和体验
Foreword cws一直有问题,而且只支持access token,经常要换很麻烦。之前有关注到dairoot的mirror,这次刚好试一下,发现体验还行 ChatGPT-Mirror https://github.com/dairoot/ChatGPT-Mirror 项目很简单 https://chatgpt.dairoot.cn/ 官方体验站,也可以使用免费账号测试,基本都差不多 部署 脚本内是docker,所以机器需要提前安好docker git clone https://github.com/dairoot/ChatGPT-Mirror.git cd ChatGPT-Mirror/ # 修改管理后台账号密码 cp .env.example .env &..
更多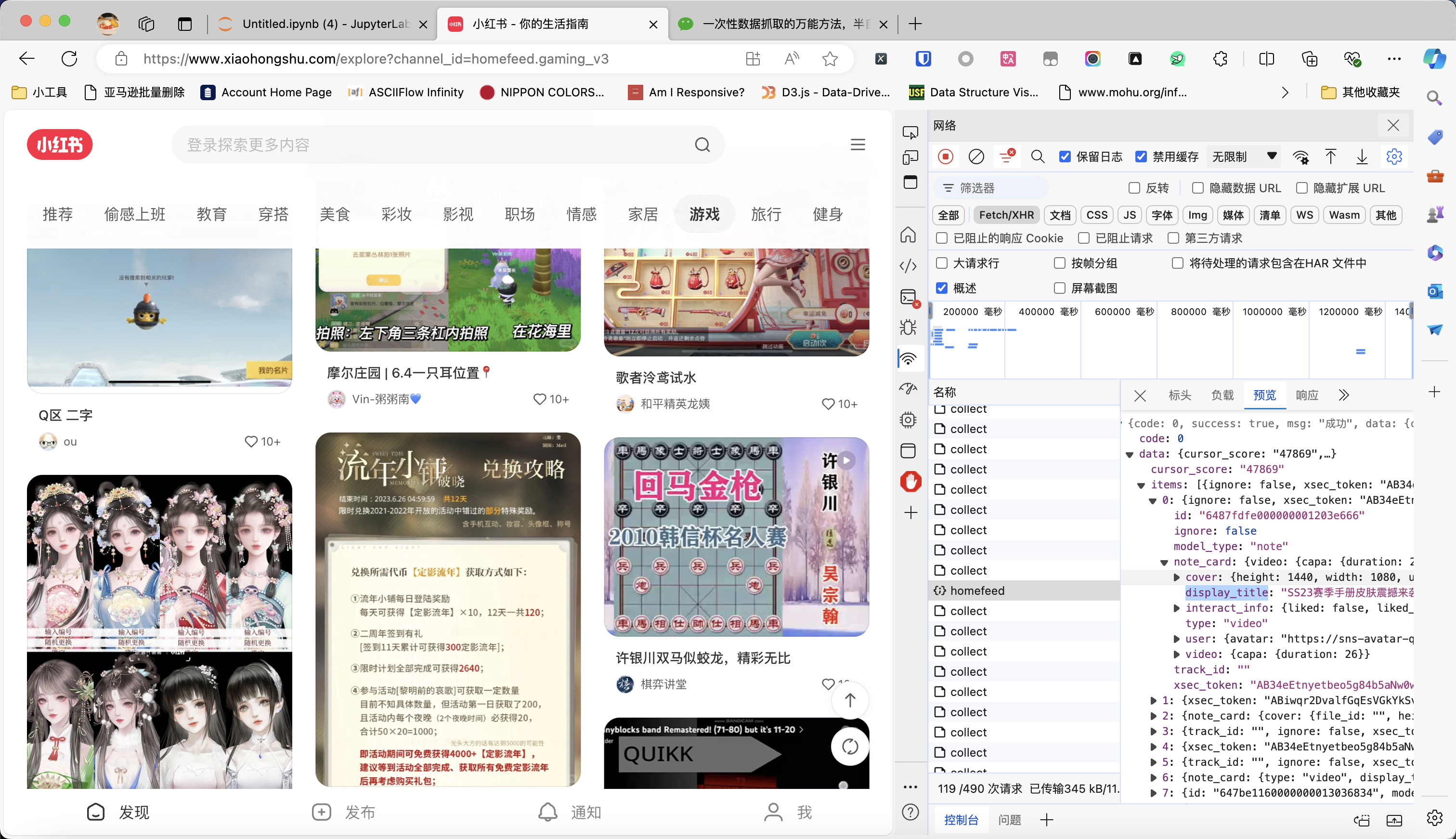
一日一技:真正的自然语言编程
在之前的文章《一次性数据抓取的万能方法,半自动抓取任意异步加载网站》中,我讲到一个万能的爬虫开发方法。从浏览器保存HAR文件,然后写Python代码解析HAR文件来抓取数据。但可能有同学连Python代码都不想写,他觉得还要学习haralyzer太累了,有没有什么办法,只需要说自然语言,就能解析HAR文件?最近我在测试open-interpreter,发现借助它,基本上已经可以实现自然语言编程的效果了。今天我们用小红书为例来介绍这个方法。如下图所示,我现在要抓取小红书首页游戏频道的帖子。通过不停往下滑动页面,我已经抓到了不少数据包。现在,把所有数据包保存为xiaohongshu.har文件(方法看我上一篇文章)。接下来,我们来安装open-interpreter,使用pip进行安装就可以了:pip instal..
更多
一日一技:三分钟离线运行开源大模型
经过一年多的发展,各种开源大模型现在已经相当不错了。国产的Qwen 1.5的生成效果已经能满足一些日常使用。有一些同学可能之前一直在用网页版的ChatGPT、Kimi Chat、文心一言或者通义千问,那么你可能会遇到如下一些问题:网络问题。例如ChatGPT需要特殊的网络才能访问。审查问题。国产大模型会大量屏蔽关键字,有一些你觉得完全没有任何问题的回答,它会告诉你不符合法律规范,不能回答。不能自定义模型,网页版的这些大模型,你没有办法做微调,难以自定义内容。当你花了大量时间设计了一个高级Prompt,把模型洗脑成了猫娘,结果第二天它又不能用了。隐私泄漏问题,担心大模型的开发商把你问的问题和上传的信息挪作他用。当你被这些问题困扰,那么你可以考虑离线运行开源大模型。完全不需要网络,因此不存在隐私泄漏的问题。你可以随..
更多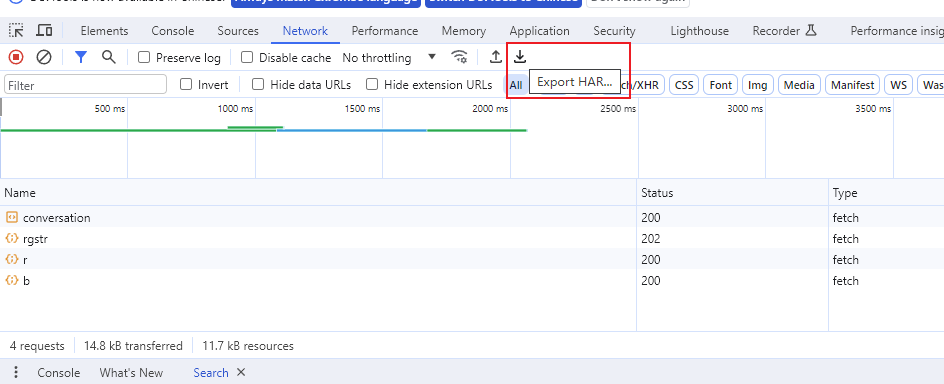
ChatGPT Plus 单账号共享合租服务
Foreword 单个ChatGPT Plus 账号共享合租,各自会话独立分割,就好像一个人使用一样,方便给一个组织或者多人使用。 CWS 源于chatgpt-web-share项目,适用于个人、组织或团队的 ChatGPT 共享方案。共享一个 ChatGPT Plus 账号给多人使用,提供完善的管理和限制功能。 https://github.com/chatpire/chatgpt-web-share 部署 新建目录 cd ~ mkdir cws && cd cws mkdir -p data/config 配置初始密码 export MONGODB_PASSWORD=password # MongoDB 密码 export INITIAL_ADMIN_PASSW..
更多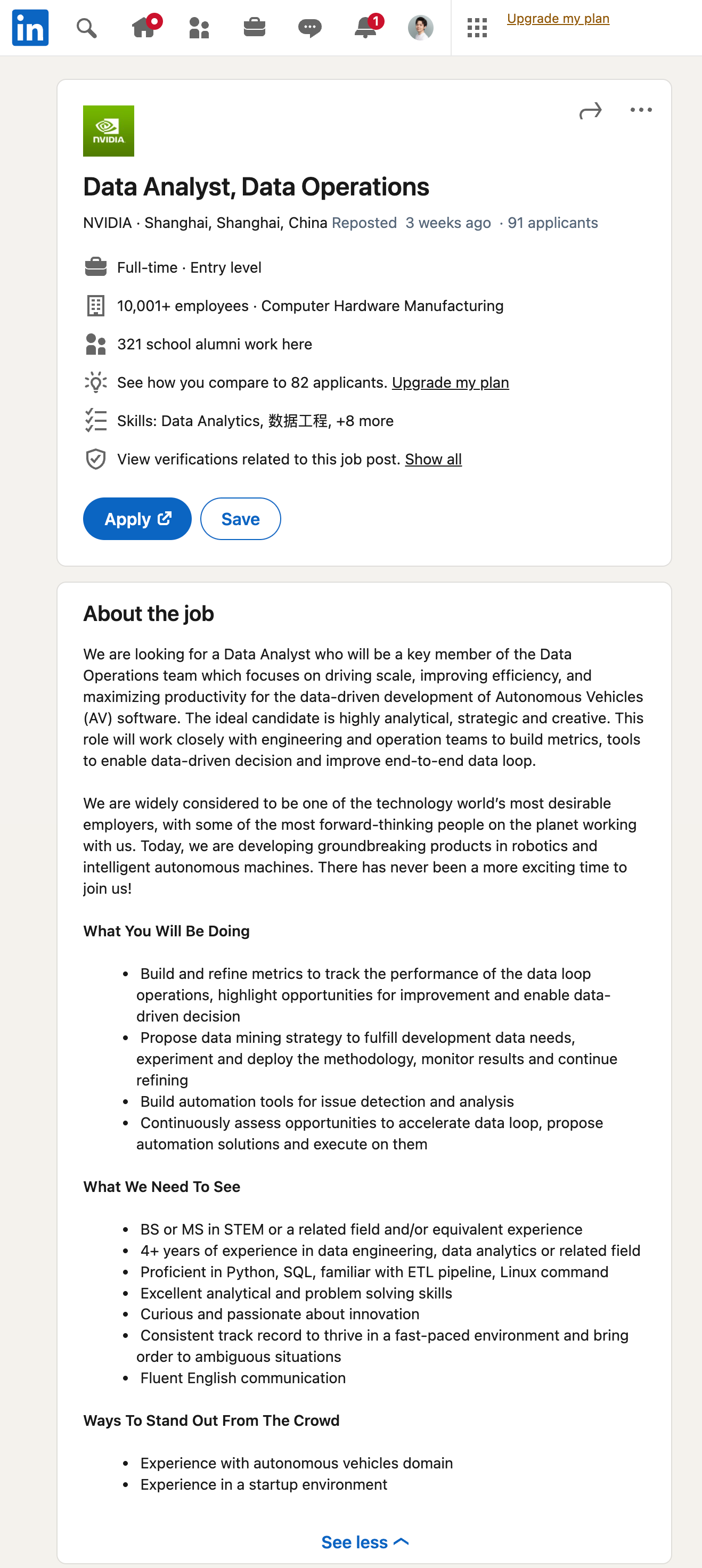
一日一技:自动提取任意信息的通用爬虫
使用过GNE的同学都知道,GNE虽然是通用爬虫,但只是文章类页面的通用爬虫。如果一个页面不是文章页,那么就无能为力了。随着ChatGPT引领的大语言模型时代到来,这个问题基本上已经不是问题了。我们先来看一个效果。首先打开Linkedin,随便找一个招聘的岗位,如下图所示:然后,我们直接使用GPT从这里提取信息:对应的Prompt为:12345你是一个数据提取小助手,能够从一大段招聘相关的文本中提取有用的信息并以JSON格式返回。{经过清洗的网页源代码或者文本}请从上面的文本中,提取招聘相关的信息,返回数据格式如下: {"title": "岗位名称", "full_time": "是否为全职", "employee_num": "雇员数量", "level": "岗位等级", "skill": "岗位需要的技能"..
更多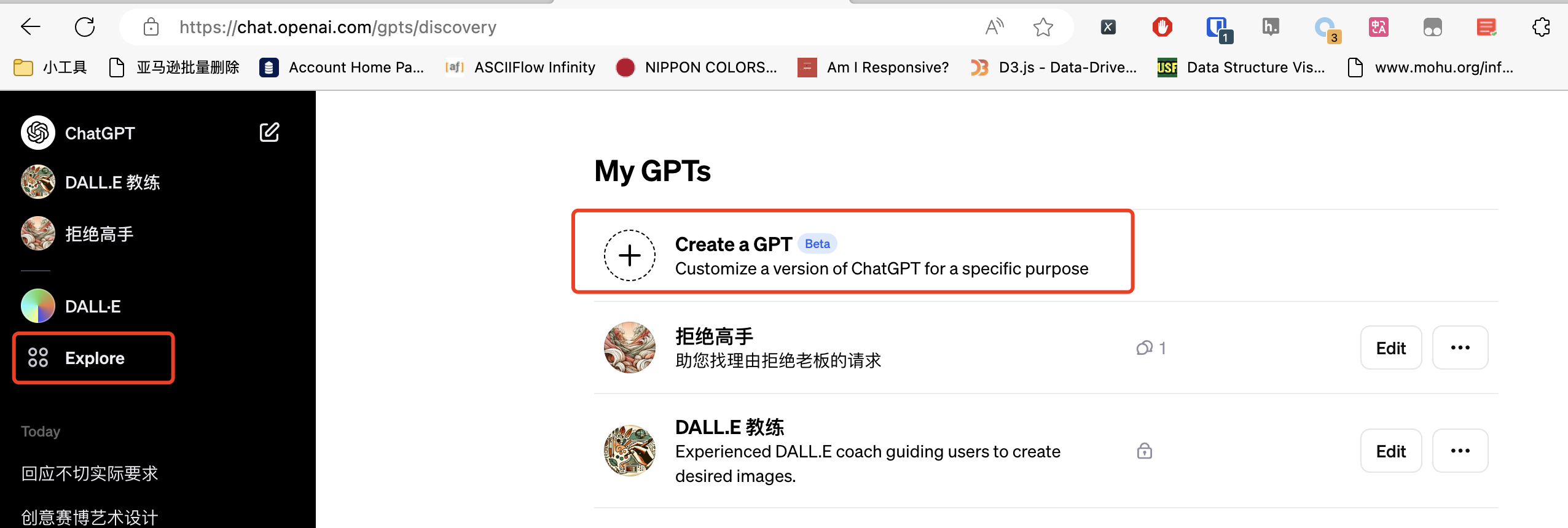
老板让我加班怎么办?GPTs创建机器人实战
前两天的OpenAI发布会,相信很多同学看完以后都热血沸腾。我之前一直使用的是ChatGPT的免费版本,看完这个发布会以后,立刻就充值了ChatGPT Plus,来试一试这些高级功能。这两天GPTs功能上线了,短短三天时间,全球网友创建了几千个GPT机器人。我今天也来搞一个玩玩。使用GPTs创建机器人非常简单,不需要懂任何编程知识,甚至不需要懂Prompt工程,你只需要跟着他的向导,一步一步描述你的想法就可以了。当我们成为了ChatGPT Plus会员以后,在ChatGPT页面会看到一个Explore的栏目,如下图所示。进入这个栏目,点击Create a GPT就可以开始创建自己的机器人了。在左侧,是机器人创建向导,它会首先让你描述一下,你想实现什么功能。这个地方不需要懂Prompt工程,你只需要像平时说话一样..
更多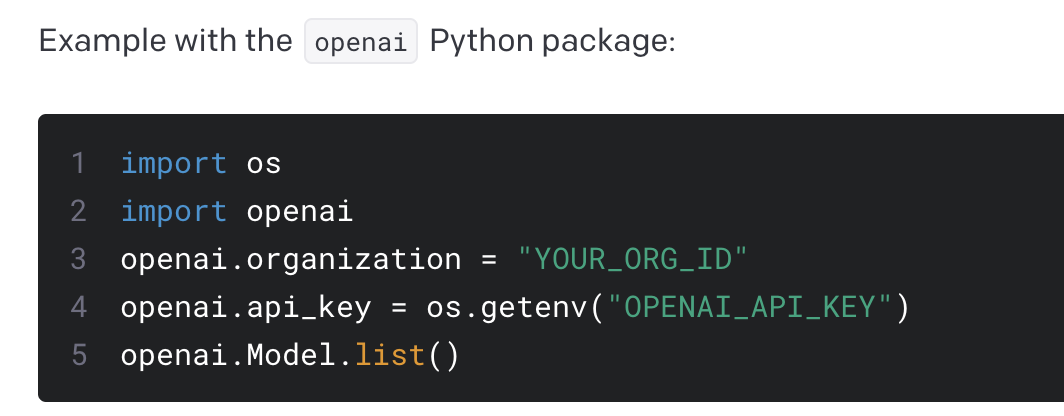
一日一技:如何同时使用多个GPT的API Key?
相信很多同学或多或少都在Python中使用过GPT API,通过Python安装openai库,来调用GPT模型。OpenAI官方文档中给出了一个示例,如下图所示:如果你只有一个API账号,那么你可能不觉得这样写有什么问题。但如果你想同时使用两个账号怎么办?有些同学可能知道,微软的Azure也提供GPT接口,在Python中也需要通过openai库来调用,它的调用示例为:当你全局设置了openai.api_type = 'azure'以后,你怎么同时使用OpenAI的GPT接口?这两个文档中给出的示例写法,都是全局写法,一但设定以后,在整个运行时中,所有调用GPT接口的地方,都会使用这里设置的参数:123import openaiopenai.xx = yy有些同学不知道怎么在Python SDK中同时使用多个..
更多