使用Elasticsearch分析腾讯云EO日志
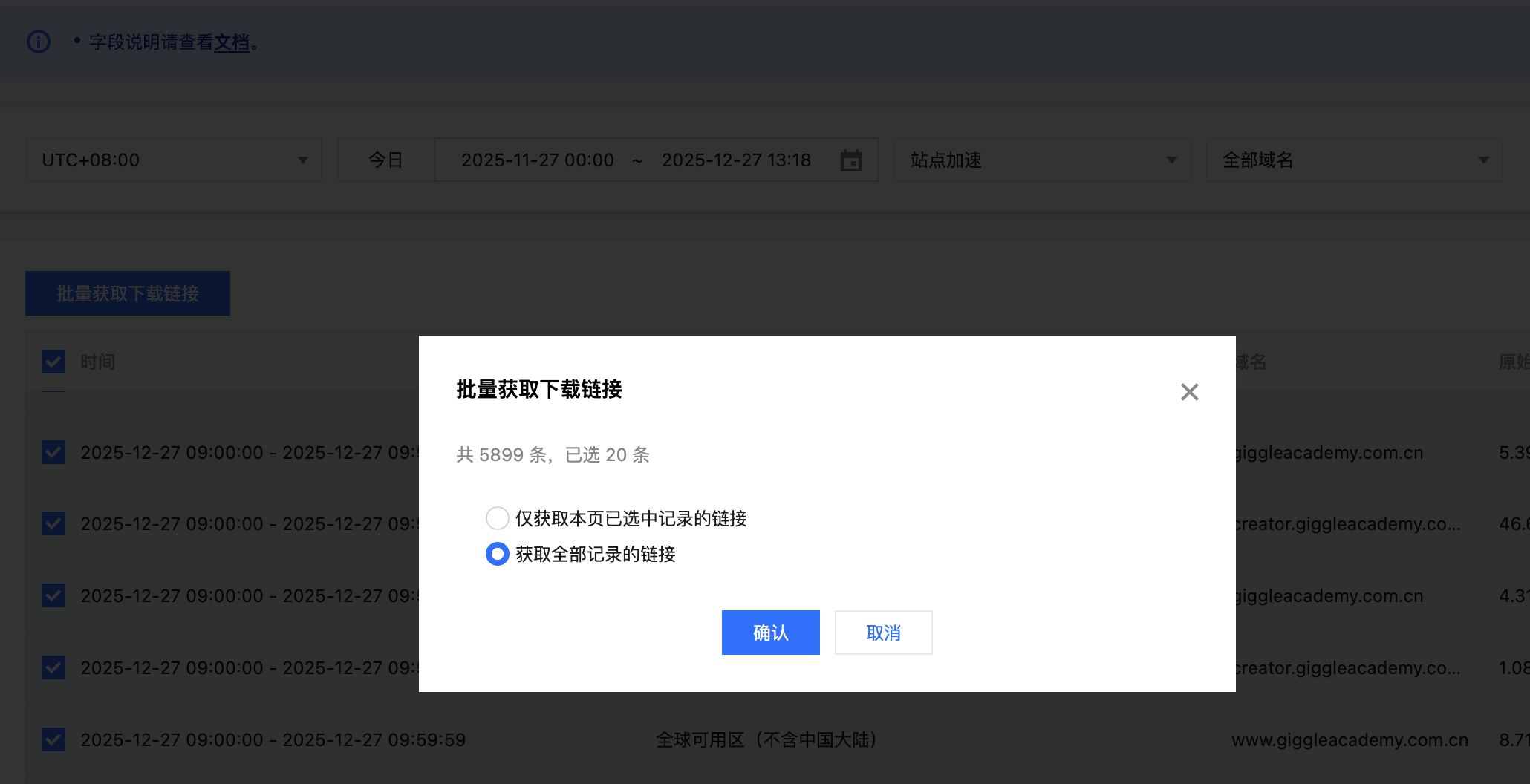
腾讯云EO可以查看一些指标信息,但是更加详细的信息需要我们下载离线日志自行分析。获取日志下载链接腾讯云会将日志打包为.gz格式,解压后文件会包含多行,每一行都是一个JSON格式的数据,对应一条EO的请求日志,日志格式可以参考腾讯云文档。我们可以批量获取最近一个月的日志下载链接之后复制所有链接并保存到urls.txt文件中。启动Elasticsearch集群我们参考官方文档使用docker来启动集群,首先下载.env和docker-compose.yml,之后在.env文件中设置es和kibana的密码都是123456,然后设置STACK_VERSION=9.2.3。考虑到数据量比较大,可以提高容器的内存大小,我这里设置了一台8G。12345678910111213141516171819202122232425..
更多
一日一技:写XPath也并不总是这么简单
摄影:产品经理烤乳鸽初级爬虫工程师有时候又叫做XPath编写员,他们的工作非常简单也非常繁琐,就是拿到网页的HTML以后,写XPath。并且他们觉得使用模拟浏览器可以解决一切爬虫问题。很多人都看不起这个工作,觉得写XPath没有任何技术含量,随便找个实习生就能做。这种看法大部分情况下是正确的,但偶尔也有例外,例如今天我要讲的这个Case,可能实习生还搞不定。下面我们来看一下这个视频。点击查看视频在这个视频中,你首先点击Linkedin的信息流中,帖子右上角的三个点,想使用模拟浏览器点击Copy link to post链接,从而把帖子的链接复制到剪贴板。但现在出现了一个问题,你无法看到这个弹出框对应的HTML代码。因为这个弹出框是在你点击了三个点以后动态生成的,它会动态修改HTML,从而出现这个下拉框。但当你想..
更多
一日一技:如何正确渲染大模型返回的Markdown?
摄影:产品经理简单做个家宴我们经常让大模型返回Markdown格式的文本,然后通过Python的markdown库把文本渲染成HTML。但不知道大家有没有发现,大模型返回的Markdown并不是标准的Markdown。特别是当返回的内容包含列表时,大模型返回的内容有问题。例如下面这段文本:1234**关于这个问题,我有以下看法*** 第一点* 第二点* 第三点你粗看起来没有问题,但当你使用markdown模块去把它渲染成HTML时,你会发现渲染出来的结果不符合你的预期,如下图所示:这是因为标准的Markdown对换行非常敏感,列表项与它上面的文本之间,必须有一个空行,才能正确解析,如下图所示:不仅是空行,还有多级列表的缩进问题。标准Markdown的子列表项缩进应该是4个空格,但大模型返回的子列表缩进经常只有3..
更多
一日一技:Scrapy如何发起假请求?
摄影:产品经理韩国章肥虾。在使用Scrapy的时候,我们可以通过在pipelines.py里面定义一些数据处理流程,让爬虫在爬到数据以后,先处理数据再储存。这本来是一个很好的功能,但容易被一些垃圾程序员拿来乱用。我看到过一些Scrapy爬虫项目,它的代码是这样写的:1234567891011...def start_requests(self): yield scrapy.Request('https://baidu.com')def parse(self, response): import pymongo handler = pymongo.MongoClient().xxdb.yycol rows = handler.find() for row in rows: ..
更多
一日一技:如何正确解析超大JSON列表
摄影:产品经理回锅肉当我们采购数据集时,有时候供应商会以JSON Lines的形式交付给我们。这种格式,本质上是文本格式,它每一行是一个JSON。例如,供应商给我们了一个文件小红书全量笔记.json文件,我们可以使用如下Python代码来一行一行读取:123456import jsonwith open('小红书全量笔记.json') as f: for line in f: info = json.loads(line) note = info['note'] print('笔记内容为:', note)这个格式的好处在于,每一次只需要把少量内容读取到内存中。即便这个文件有1TB,我们也可以使用一个4GB内存的电脑来处理。今天出了一个乌龙事件,某数据供应商在给我数..
更多
一日一技:如何使用大模型提取结构化数据
经常有同学在微信群里面咨询,如何使用大模型从非结构化的信息里面提取出结构化的内容。最常见的就是从网页源代码或者长报告中提取各种字段和数据。最直接,最常规的方法,肯定就是直接写Prompt,然后把非结构化的长文本放到Prompt里面,类似于下面这段代码:1234567891011121314151617from zhipuai import ZhipuAIclient = ZhipuAI(api_key="") # 填写您自己的APIKeyresponse = client.chat.completions.create( model="glm-4-air-0111", messages=[ {"role": "system", "content": '''你是一个数据提取专家,非常善于..
更多
一日一技:如何正确对Python第三方库做二次开发
今天,有同学在知识星球上给我提了一个问题:如何在Simplemind中接入Azure的GPT接口。如下图所示。在使用Python时经常会出现这样的情况,某一个第三方库,满足我们99%的需求,但碰巧有一个小需求不满足。遇到这种情况,有些同学会忍痛割爱,换一个库;还有一些同学,会继续使用这个第三方库,但是缺的那个功能,他就完全自己单独写;剩下的同学,可能是把这个第三方库下载下来,放到自己项目的根目录中,然后当做项目的一部分来修改并导入使用。今天我们就来讲一下这个问题。前两个方法不需要多说什么。第三个方法从功能上来说没什么问题,但会给自己的项目引入大量其他代码,导致项目在做安全性检查、静态类型检查、Code Review时变得很麻烦。而且这个第三方库必须放到项目的根目录,否则在导入时,它的导入语句就跟正常pip安装的..
更多
一日一技:为什么我很讨厌LangChain
一说到RAG或者Agent,很多人就会想到LangChan或者LlamaIndex,他们似乎觉得这两个东西是大模型应用开发的标配。但对我来说,我特别讨厌这两个东西。因为这两个东西就是过度封装的典型代表。特别是里面大量使用依赖注入,让人使用起来非常难受。什么是依赖注入假设我们要在Python里面模拟出各种动物的声音,那么使用依赖注入可以这样写:12345678910111213141516171819202122def make_sound(animal): sound = animal.bark() print(f'这个动物在{sound}')class Duck: def bark(self): return '嘎嘎叫'class Dog: def bark(self):..
更多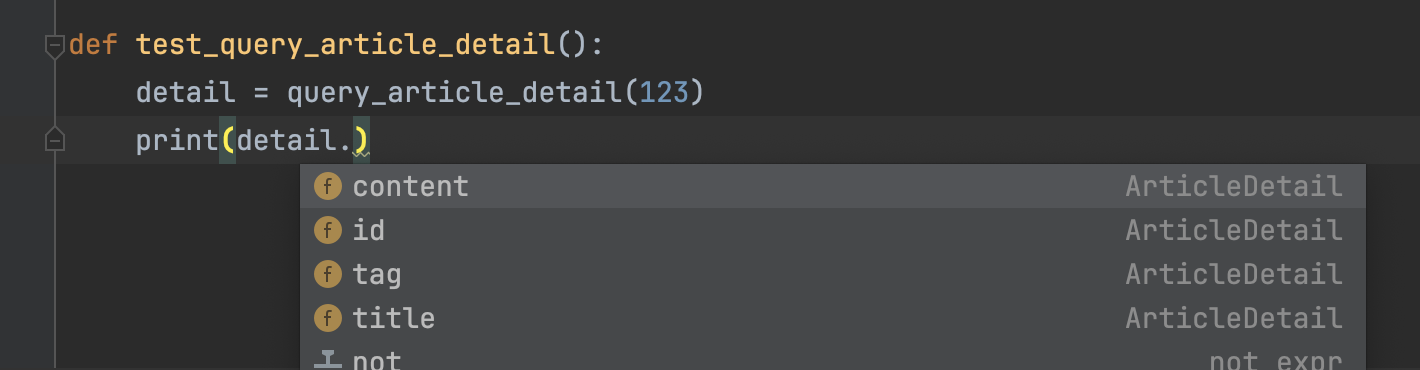
一日一技:Python类型标注的高级用法
假设你正在写后端代码,其中一个函数的功能是传入文章id,返回文章详情。因为项目比较大,因此在定义函数时,把类型标注加上,标明了参数的类型和返回的类型。例如:1234567891011121314151617181920212223242526from typing import Listfrom dataclasses import dataclass@dataclassclass ArticleDetail: id: int title: str content: str tag: List[str]def query_article_detail(article_id: int) -> ArticleDetail: detail = ArticleDetail( ..
更多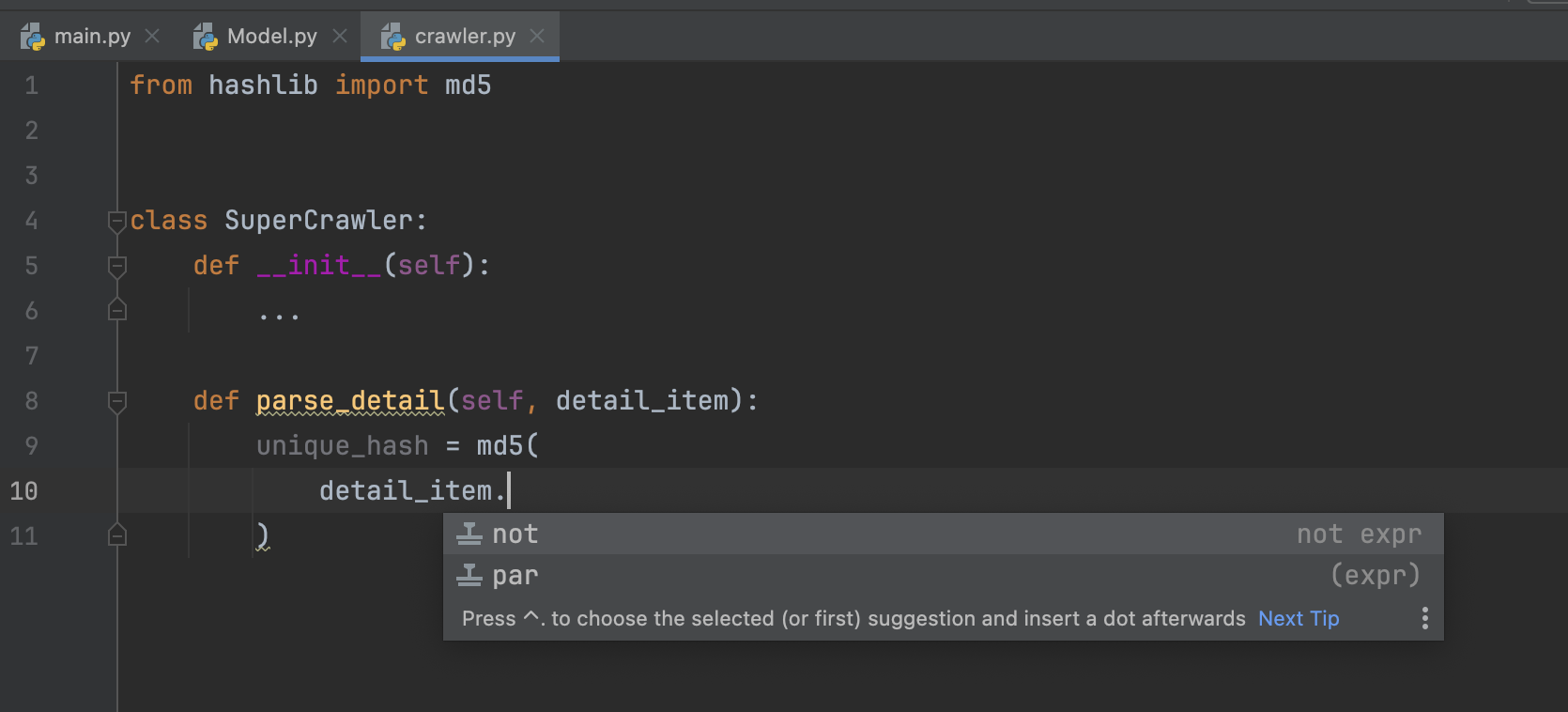
一日一技:如何实现高性能自动补全?
我们知道,在写Python时,使用IDE的自动补全功能,可以大大提高代码的开发效率。使用类型标注功能,可以让IDE知道应该怎么做自动补全。当我们没有类型标注时,IDE并不知道函数的某个参数是什么东西,没有办法做补全,如下图所示。但当我们把类型标注加上以后,IDE就能正常补全了,如下图所示:这样做,需要从另一个文件中,把这个参数对应的类导入到当前文件里面,然后把类作为类型填写到函数参数后面。咋看起来没有什么问题,并且我,还有很多看文章的同学,应该经常这样写类型标注的代码,从而提高代码的开发效率。但如果你的项目规模大起来以后,你就会遇到几个比较麻烦的问题:导入链过长:例如上面截图中的代码,我从model.py中导入了Detail这个类。如果我在model.py文件的开头,还有from aaa import bbb,..
更多