
一日一技:写XPath也并不总是这么简单
摄影:产品经理烤乳鸽初级爬虫工程师有时候又叫做XPath编写员,他们的工作非常简单也非常繁琐,就是拿到网页的HTML以后,写XPath。并且他们觉得使用模拟浏览器可以解决一切爬虫问题。很多人都看不起这个工作,觉得写XPath没有任何技术含量,随便找个实习生就能做。这种看法大部分情况下是正确的,但偶尔也有例外,例如今天我要讲的这个Case,可能实习生还搞不定。下面我们来看一下这个视频。点击查看视频在这个视频中,你首先点击Linkedin的信息流中,帖子右上角的三个点,想使用模拟浏览器点击Copy link to post链接,从而把帖子的链接复制到剪贴板。但现在出现了一个问题,你无法看到这个弹出框对应的HTML代码。因为这个弹出框是在你点击了三个点以后动态生成的,它会动态修改HTML,从而出现这个下拉框。但..
更多
一日一技:Scrapy如何发起假请求?
摄影:产品经理韩国章肥虾。在使用Scrapy的时候,我们可以通过在pipelines.py里面定义一些数据处理流程,让爬虫在爬到数据以后,先处理数据再储存。这本来是一个很好的功能,但容易被一些垃圾程序员拿来乱用。我看到过一些Scrapy爬虫项目,它的代码是这样写的:1234567891011...def start_requests(self): yield scrapy.Request('https://baidu.com')def parse(self, response): import pymongo handler = pymongo.MongoClient().xxdb.yycol rows = handler.find() for row in rows: ..
更多一日一技:315晚会曝光的获客软件是什么原理
今年315晚会曝光了几个获客软件,号称可以拦截任何人的网络浏览记录,并根据对方在直播软件的留言、打过的电话、浏览过的网址,获取对方的手机号和微信号。还有在地图上随便画一个圈,就能找到圈里面130万人的联系方式。作为一个软件工程师,我来说说我对他们背后原理的猜测。晚会里面笼统的说到他们使用了爬虫技术。其实这种说法并不准确。爬虫做不到这种程度。爬虫只能爬取到人眼能看到的各种公开数据。例如有人在直播软件下面回复了评论,爬虫能爬到评论人的用户昵称、评论的内容。但是因为评论人的真名、手机号码和微信号并没有显示在直播软件上,所以爬虫是不能爬到的。它后续还需要使用撞库、社工库、社会工程学等等一系列操作,才能定位到用户的手机号。以它直播软件获客这个例子,我觉得它背后的原理是这样的:获客公司有大量的爬虫,他会在各种社交网站..
更多
一日一技:使用大模型实现全自动爬虫(一)
在文章一日一技:图文结合,大模型自动抓取列表页中,我提到可以使用大模型实现一个全自动爬虫。只需要输入起始URL加上需求,就可以借助模拟浏览器自动完成所有的抓取任务。在实现的过程中,我发现涉及到的知识点可能一篇文章讲不完,因此拆分成了多篇文章。爬虫演示今天是第一部分,我们暂时不依赖模拟浏览器,而是使用httpx(你也可以使用requests)实现全自动爬虫,传入我博客文章列表页,爬虫会自动抓取前三页所有博客文章的标题、正文、作者、发布时间。爬取结果如下图所示:运行过程如下图所示:爬虫首先会进入起始列表页,抓取上面的所有文章。然后进入列表页第二页,再抓取所有文章,最后进入第三页,再抓取所有文章。整个过程都是全自动的。不需要写任何XPath,也不需要告诉爬虫哪里是翻页按钮,文章的标题在哪里,发布时间在哪里,正文..
更多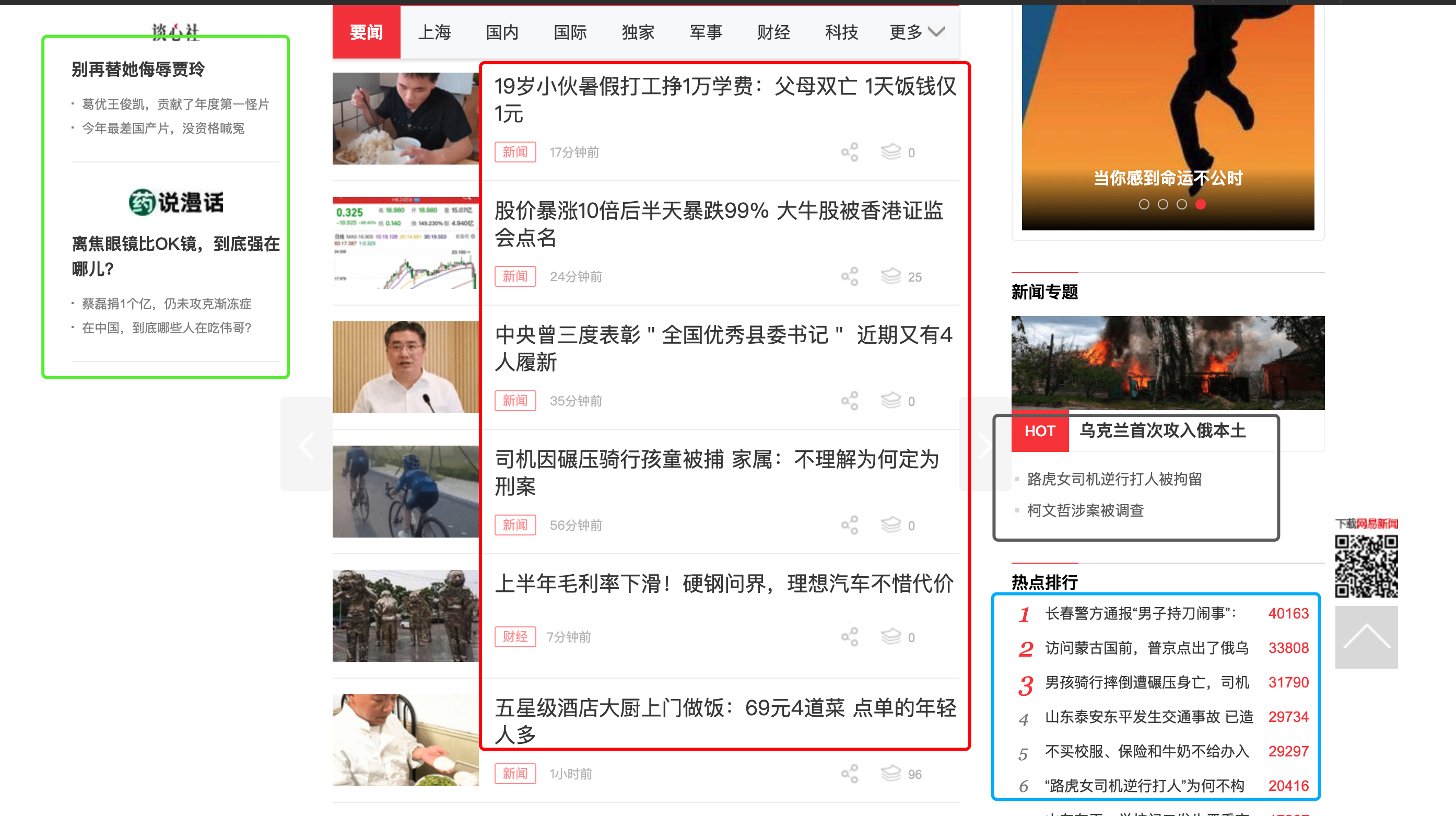
一日一技:图文结合,大模型自动抓取列表页
熟悉我的同学都知道,GNE可以自动化提取任意文章页面的正文,专业版GnePro的准确率更是在13万个网站中达到了90%。但GNE一直不支持列表页的自动抓取。这是因为列表页的列表位置很难定义。例如下面这张图片:对人来说,要找到文章列表很简单,红色方框框住的部分就是我们需要的文章列表。但如果让程序自动根据HTML格式相似的规律来寻找列表页,它可能会提取出蓝色方框的位置、绿色方框的位置、灰色方框的位置,甚至导航栏。之前我也试过使用ChatGPT来提取文章列表,但效果并不理想。因为传给大模型HTML以后,他也不能知道这里面某个元素在浏览器打开以后,会出现什么位置。因此它本质上还是通过HTML找元素相似的规律来提取列表项目。那么其实没有解决我的根本问题,上图中的蓝色、绿色、灰色位置还是经常会提取到。前两天使用GLM..
更多
一日一技:如何使用大模型提高开发效率
前两天,有同学在微信群里面问怎么识别下图所示的验证码:一般爬虫验证码我会使用ddddocr来解析,在大模型出来之前,这个工具基本上是Python下面效果最好的免费验证码识别工具了。但是这次它翻车了。这个提问的同学也试过了很多个大模型,发现都提取不出来。甚至连GPT-4o也失败了:GPT-4o都失败了,还能怎么办呢?难道要使用付费的商业方案了?这个时候,突然有个同学发出来了一张截图:ChatGLM,也就是智谱AI,竟然识别对了!这个同学接着又发了一张图,另一个验证码识别又对了!甚至连四则运算验证码都能识别:这下整个群里面做爬虫的人都热闹了起来:于是就有了今天这篇文章。上面的截图是使用智谱AI网页版识别的,但是我们写代码时肯定需要使用API。智谱AI的大模型叫做GLM,也提供开放API服务。于是我到智谱AI ..
更多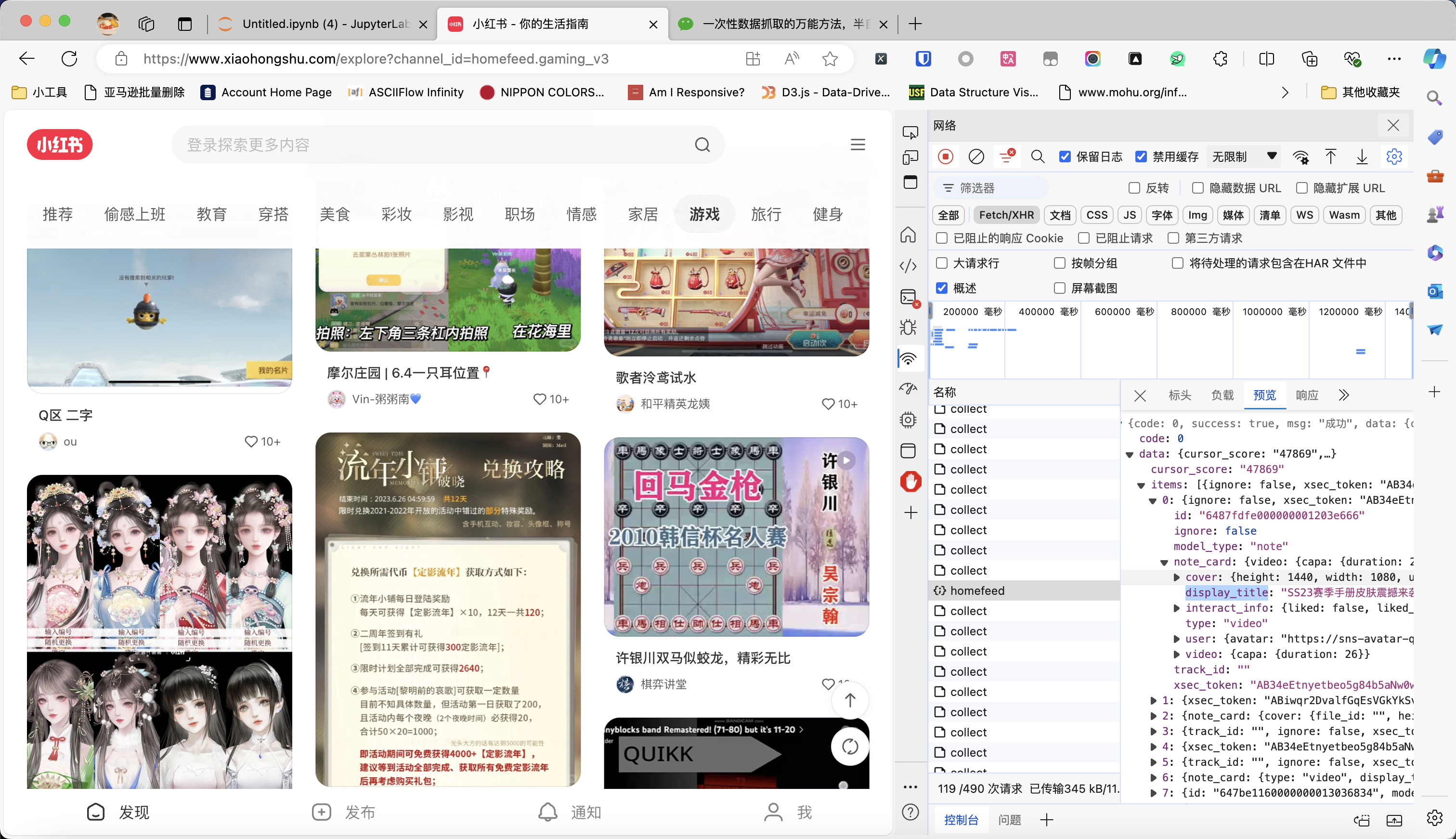
一日一技:真正的自然语言编程
在之前的文章《一次性数据抓取的万能方法,半自动抓取任意异步加载网站》中,我讲到一个万能的爬虫开发方法。从浏览器保存HAR文件,然后写Python代码解析HAR文件来抓取数据。但可能有同学连Python代码都不想写,他觉得还要学习haralyzer太累了,有没有什么办法,只需要说自然语言,就能解析HAR文件?最近我在测试open-interpreter,发现借助它,基本上已经可以实现自然语言编程的效果了。今天我们用小红书为例来介绍这个方法。如下图所示,我现在要抓取小红书首页游戏频道的帖子。通过不停往下滑动页面,我已经抓到了不少数据包。现在,把所有数据包保存为xiaohongshu.har文件(方法看我上一篇文章)。接下来,我们来安装open-interpreter,使用pip进行安装就可以了:pip ins..
更多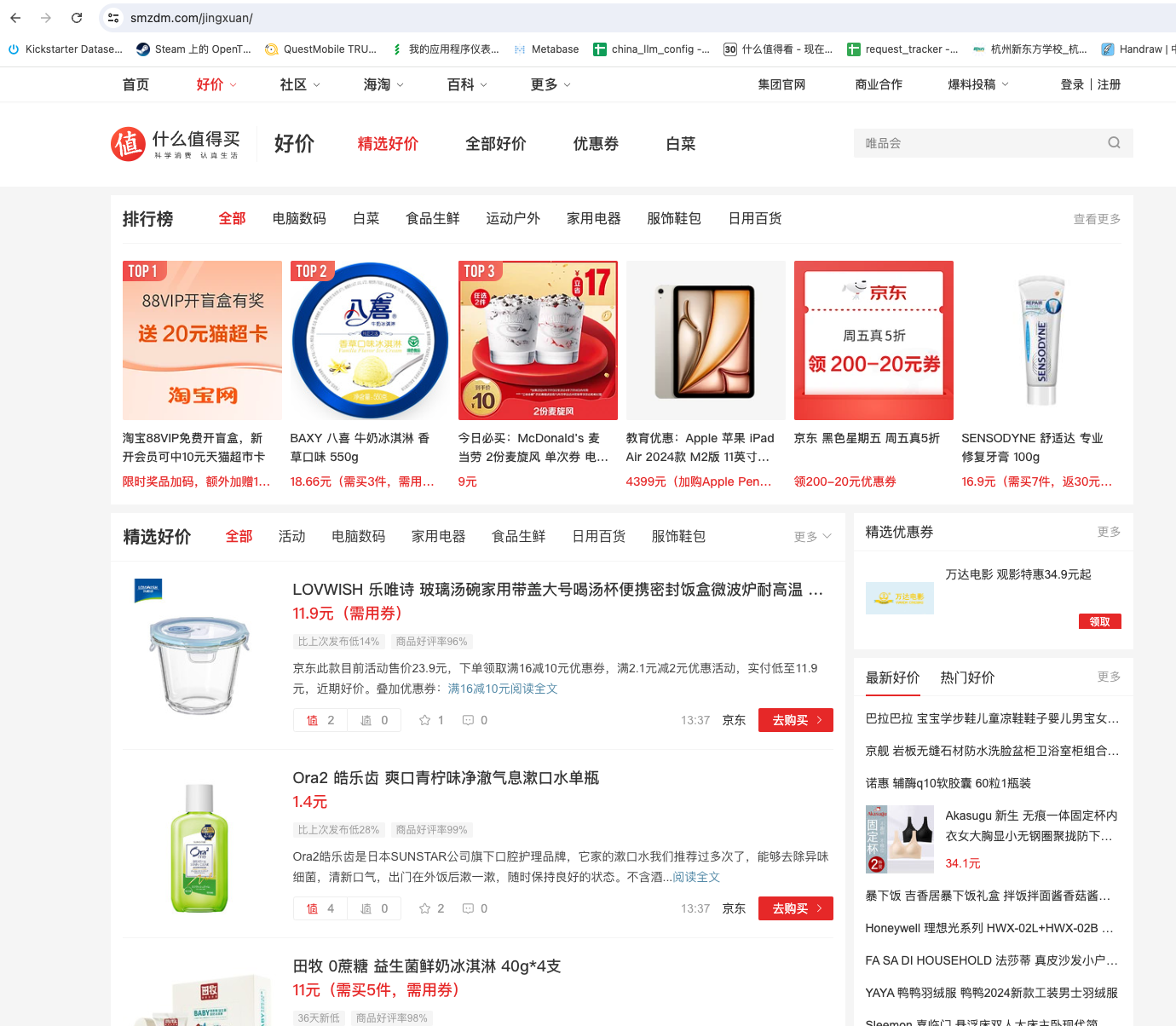
一次性数据抓取的万能方法,半自动抓取任意异步加载网站
我们有时候临时需要抓取一批数据,数据不多,可能就几页,几百条数据。手动复制粘贴太麻烦,但目标网站又有比较强的反爬虫,请求有防重放的验证,写代码抓取也不方便。用模拟浏览器又觉得没必要,只用一次的爬虫,写起来很麻烦。例如,我经常逛色魔张大妈的精选好价页面。这个页面会列出各种折扣的信息。但它只能按大类筛选,无法用关键词搜索。如下图所示我打算只看前 10 页内容就好了。但一页一页看太麻烦了。有没有什么快速爬虫,把这个列表页的内容抓取下来呢?其实这种需求,使用半自动爬虫是最简单的。不需要考虑网站反爬虫的问题,因为你使用的就是真实的浏览器,不会通过代码来发起请求。而且这个列表页的内容都是异步加载的,直接在开发者工具可以看到数据包,数据包里面就有当前页面的全部内容。如下图所示:有没有什么办法,快速把这些数据包弄下来处理..
更多
一日一技:2秒抓取网页并转换为markdown
在《一日一技:自动提取任意信息的通用爬虫》这篇文章中,我提到可以通过大模型从网页内容里面提取结构化信息。为了节省Token,文章里面我直接提取了页面上的所有文本。这种方式需要自己写代码来过滤HTML中的垃圾标签。并且提取出来的文本可能会混在一起。虽然大模型在很大程度上不会受到标点符号的影响。但如果有办法把网页直接转换为Markdown的话,大模型在解析时就能更加准确。现在,你不需要写任何代码就可以实现这个目标!假设我们需要抓取我的这篇知乎专栏文章:小问题,大隐患:如何正确设置 Python 项目的入口文件?。我们知道知乎是有反爬虫的,直接抓取并不容易。怎么样在2秒内抓取这篇文章,并转换为Markdown呢?非常简单,你只需要在url前面加上https://r.jina.ai/并回车就可以了。完整的URL变..
更多
一日一测:Bright Data的海外代理测试
上周的公众号文章提到了Bright Data提供的代理服务。没想到他们的运营同学竟然找上了门,问我能不能帮他们做一个评测。我之前使用Bright Data的代理,是因为突然有一天我的HuggingFace爬虫挂了。比较奇怪的是,这个爬虫在我电脑上始终正常运行,但一放到服务器上就请求失败。联想到HuggingFace被封了,而这个爬虫之前一直使用的国内代理供应商,那么原因就很明显了。因为我的电脑是24小时挂着梯子的,所以能够正常访问HuggineFace,但爬虫部署到服务器上面以后,他会自动使用配置好的国内代理。由于国内代理也受到GFW的影响,因此也会出问题。首先看一下Bright Data他们代理的基本功能,基于数据中心的隧道代理和基于住宅IP的隧道代理还有基于Sim卡的隧道代理。海外代理都是按流量收费的..
更多