
谈谈 Kubernetes 的问题和局限性
2014 年发布的 Kubernetes 在今天俨然已成为容器编排领域的事实标准,相信谈到 Kubernetes 的开发者都会一再复述上述现象。如下图所示,今天的大多数个人或者团队都会选择 Kubernetes 管理容器,而也有 75% 的人会在生产环境中使用 Kubernetes。图 1 - Kubernetes 容器编排1在这种全民学习和使用 Kubernetes 的大背景下,我们也应该非常清晰地知道 Kubernetes 有哪些局限性。虽然 Kubernetes 能够解决容器编排领域的大多数问题,但是仍然有一些场景是它很难处理、甚至无法处理的,只有对这些潜在的风险有清晰的认识,才能更好地驾驭这项技术,这篇文章将从集群管理和应用场景两个部分谈谈 Kubernetes 社区目前的发展和一些局限性。集群管..
更多
CPU 和 GPU - 异构计算的演进与发展
世界上大多数事物的发展规律是相似的,在最开始往往都会出现相对通用的方案解决绝大多数的问题,随后会出现为某一场景专门设计的解决方案,这些解决方案不能解决通用的问题,但是在某些具体的领域会有极其出色的表现。而在计算领域中,CPU(Central Processing Unit)和 GPU(Graphics Processing Unit)分别是通用的和特定的方案,前者可以提供最基本的计算能力解决几乎所有问题,而后者在图形计算和机器学习等领域内表现优异。图 1 - CPU 和 GPU异构计算是指系统同时使用多种处理器或者核心,这些系统通过增加不同的协处理器(Coprocessors)提高整体的性能或者资源的利用率1,这些协处理器可以负责处理系统中特定的任务,例如用来渲染图形的 GPU 以及用来挖矿的 ASIC ..
更多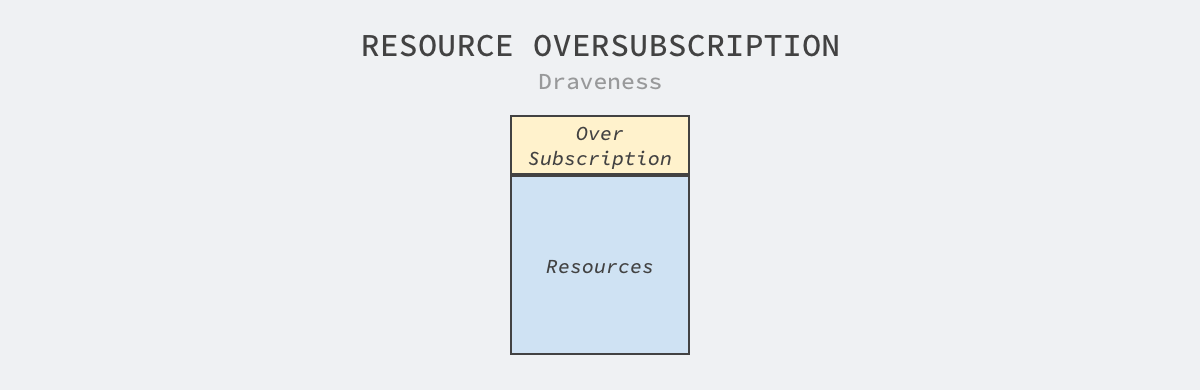
数据中心的电力超售 · OSDI '20
『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。本文要介绍的是 2020 年 OSDI 期刊中的论文 —— Thunderbolt: Throughput-Optimized, Quality-of-Service-Aware Power Capping at Scale1,该论文实现的 Thunderbolt 可以在数据中心实现电力资源的超售,电子资源的超售可以使同一个数据中心运行更多的服务器,从而提高数据中心的整体性能并减少日常的维护开销、降低成本。超售系统的目的都是降低成本并提高利用率,但是也都..
更多
Facebook 集群调度管理系统 · OSDI '20
『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。本文要介绍的是 2020 年 OSDI 期刊中的论文 —— Twine: A Unified Cluster Management System for Shared Infrastructure1,该论文实现的 Twine 是 Facebook 过去十年生产环境中的集群管理系统。在该系统出现之前,Facebook 的集群由为业务定制的独立资源池组成,因为这些资源池中的机器可能有独立的版本或者配置,所以无法与其他业务共享。Twine 的出现解决了不同资源..
更多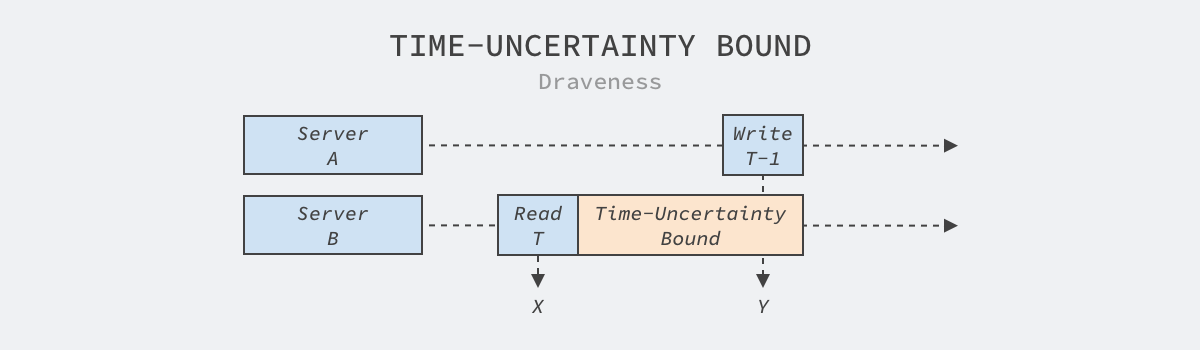
数据中心的容错时钟对时 · OSDI '20
『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。本文要介绍的是 2020 年 OSDI 期刊中的论文 —— Sundial: Fault-tolerant Clock Synchronization for Datacenters1,该论文实现的 Sundial 可以在数据中心提供高精度的、容错的对时机制。在数据中心发生故障时,它也能够保证不同服务器的绝对时间差小于 ~100ns,比行业内的其他的系统好一到两个数量级,这里的 ~100ns 也被称为时间不确定性上限(Time-uncertainty B..
更多