ShardingSphere-JDBC介绍
ShardingSphere-JDBC是一款可以将JDBC操作进行封装,然后实现数据分片、分布式事务、读写分离、高可用、数据加密和数据脱敏等功能的模块。它的原理是实现JDBC的接口,随后将收到的JDBC操作进行改写和处理,再将操作命中到真正的数据库之上。因为它实现了JDBC接口,因此现有的Java项目都可以100%兼容使用,只需要依赖ShardingSphere-JDBC并提供相关的配置即可。JDBC数据分片的简单使用我们看一个简单的JDBC数据分片的例子,首先我们需要添加相关的maven依赖12345678910 <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId..
更多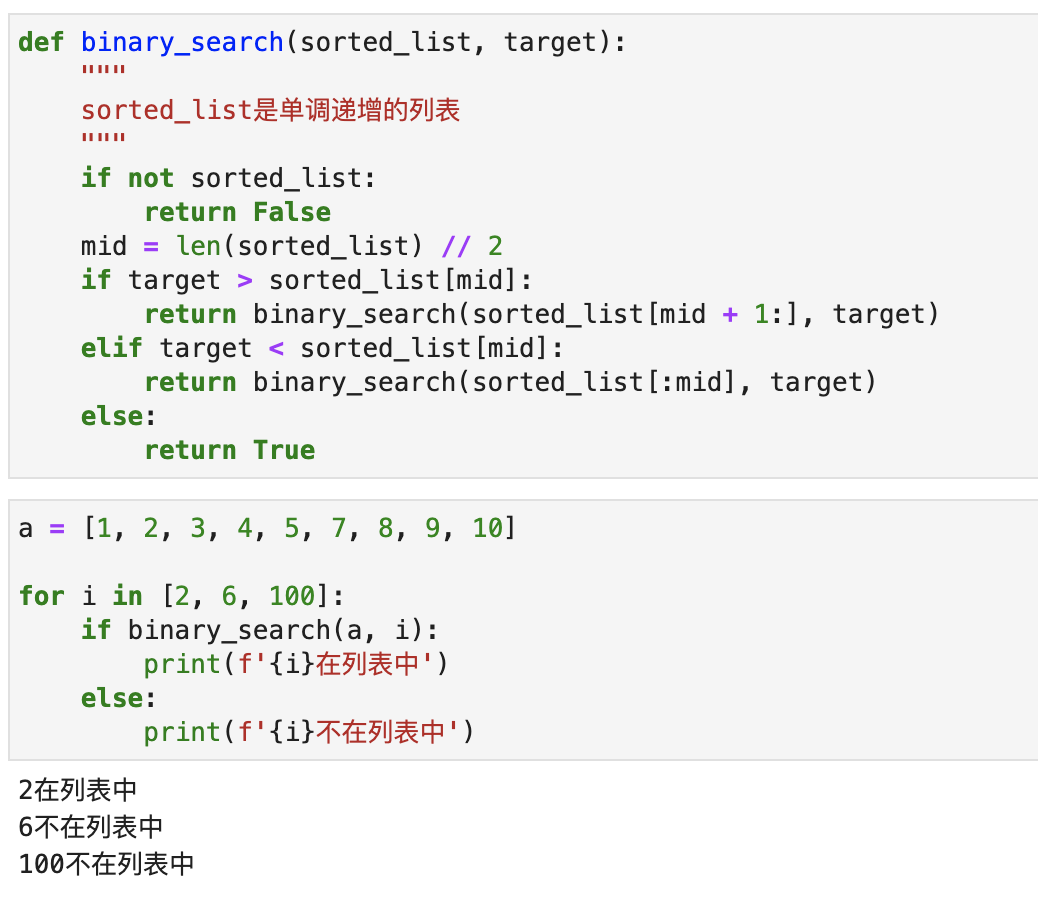
一日一技:二分偏左,二分搜索在分布式系统里面也有用?
相信大家都知道二分搜索,在一个有序的列表中,使用二分搜索,能够以O(logN)的时间复杂度快速确定目标是不是在列表中。二分搜索的代码非常简单,使用递归只需要几行代码就能搞定:12345678910111213def binary_search(sorted_list, target): """ sorted_list是单调递增的列表 """ if not sorted_list: return False mid = len(sorted_list) // 2 if target > sorted_list[mid]: return binary_search(sorted_list[mid + 1:], target) elif..
更多Pulsar的介绍与安装
简介Apache Pulsar是一个分布式消息队列,它主要由以下三部分组成。组件作用Broker负责producer和consumer的请求还有消息的复制与分发,Broker无状态不存储数据Zookeeper存储元数据、集群配置,负责任务协调还有服务发现等Bookkeeper消息数据还有cursors数据的持久化存储,Bookkeeper的每一个存储节点叫做bookieproducer往Pulsar发送数据,consumer从Pulsar接受数据,consumer接收数据的过程叫做subscription(订阅)。Pulsar有四种订阅模式模式名模式独占(exclusive)一个subscription只能有一个consumer,如果多个consumer使用相同的subscription去订阅一个topi..
更多使用Celery实现Python分布式任务处理
Celery是一个任务队列,它可以实现跨进程和机器的分布式任务处理。任务队列的输入端会输入各种任务(task),这些任务会在输出端由worker进行处理,这些任务会由客户端通过发送消息的方式交给broker,随后broker把任务分发给worker。安装组件本文使用到的组件版本组件版本Python2.7.16Celery4.4.7Redis6.2.4redis-py3.2.1首先我们需要安装celery和Redis的依赖包pip install celery==4.4.7pip install redis==3.2.1Celery支持多种类型的broker,在这里我们主要使用Redis作为Celery的broker,关于Redis的安装和使用可以参考我之前的文章Redis failover。构建应用我们首..
更多etcd的简单介绍
etcd是一个开源的分布式一致性键值数据库,其基于Raft一致性算法,用于数据存储、服务发现和调度协调。安装首先我们下载程序包useradd etcdsu - etcdwget https://github.com/etcd-io/etcd/releases/download/v3.5.4/etcd-v3.5.4-linux-amd64.tar.gztar -zxvf etcd-v3.5.4-linux-amd64.tar.gzcd etcd-v3.5.4-linux-amd64之后我们可以查询etcd的版本$ ./etcd --versionetcd Version: 3.5.4Git SHA: 08407ff76Go Version: go1.16.15Go OS/Arch: linux/amd64我..
更多Redis服务的安装和使用
我在文章Redis failover中介绍过如何安装Redis并且通过sentinel(哨兵)实现Redis的高可用。随着Redis的不断更新,现在的Redis(我使用的版本是6.2.6)已经支持了集群功能,本文记录了如何搭建一个Redis集群并使用。我们使用如下的6台机器来构建一个Redis集群172.19.65.196172.19.72.108172.19.72.112172.19.72.203172.19.65.228172.19.65.136下载源码并编译首先在172.19.65.196上下载Redis源代码并进行编译,这里我下载的版本是6.2.6useradd -m redissu - rediswget https://download.redis.io/redis-stable.tar.gz..
更多HBase集群的搭建和使用
HBase是一个分布式的列族数据库,我们可以简单的将其看成一个kv数据库,每个[列 + rowkey + 时间戳]对应了一个单元格。下载HBase的压缩包并解压我们有三台机器,预计它们的角色将会如下Node NameMasterRegionServer172.19.65.196yesno172.19.72.108backupyes172.19.72.112noyes在官网下载HBase的压缩包并分发到三台机器上,然后解压压缩包。设置免密登录学习我们在HDFS的安装和使用中了解到的SSH免密登录的方法,设置196和108两台机器要能够免密访问所有的机器。搭建HDFS和ZooKeeper服务根据文章HDFS的安装和使用和ZooKeeper的简单介绍中所介绍的内容,搭建HDFS和ZooKeeper服务。修改配置..
更多ZooKeeper的简单介绍
用了很久的ZooKeeper了,稍微做个总结。ZooKeeper(以下简称ZK)是一个分布式组件,基于类似Paxos的ZAB一致性算法来实现。ZK保存的数据结构类似于一般的文件系统,只不过在ZK中文件夹也可以拥有数据,整体文件结构为一棵树型。安装ZooKeeper去官网下载压缩包,随后使用rsync同步到三台机器上,我使用如下三台机器172.19.65.196172.19.72.108172.19.72.112解压压缩包,使用cp conf/zoo_sample.cfg conf/zoo.cfg得到配置文件,在三台机器的conf/zoo.cfg中添加如下配置dataDir=/home/zookeeper/apache-zookeeper-3.8.0-bin/dataserver.1=172.19.65.1..
更多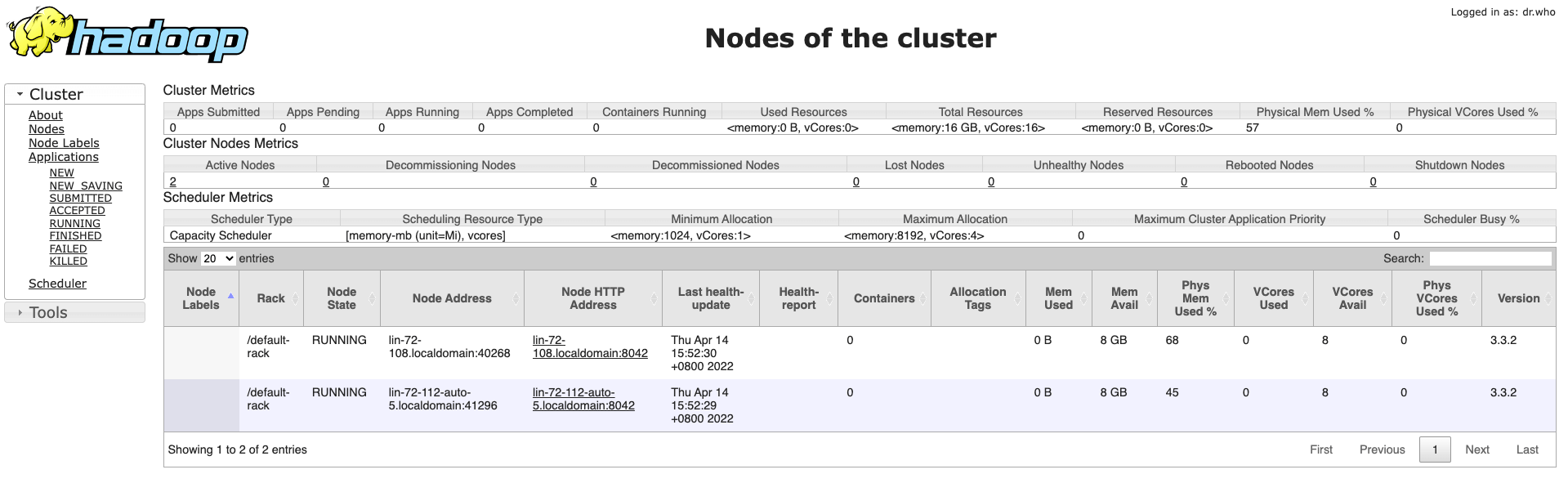
Hadoop中YARN和MapReduce的安装和使用
在上一篇文章中我们已经搭建好了HDFS环境,现在我们在这个环境的基础上继续搭建YARN和MapReduce环境。修改三台机器的etc/hadoop/mapred-site.xml文件,添加如下配置123456<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration>修改三台机器的etc/hadoop/yarn-site.xml文件,添加如下配置1234567891011121314<configurat..
更多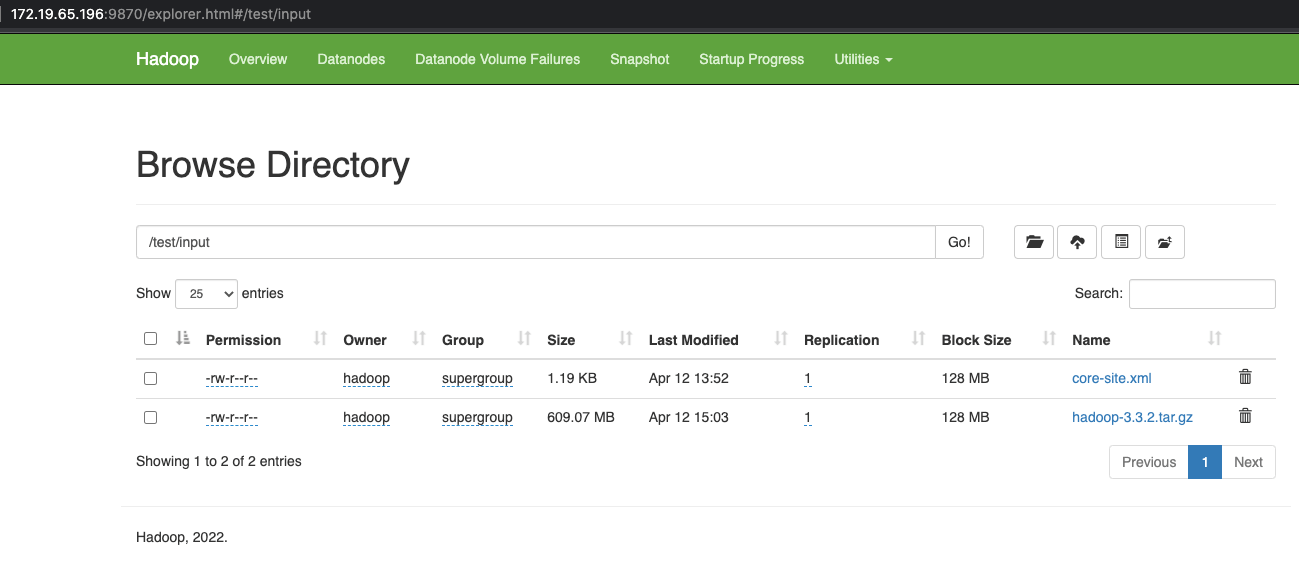
HDFS的安装和使用
正如在Hadoop学习笔记中所介绍的那样,我们已经安装好了Java环境并且设置好了JAVA_HOME环境变量,并且下载解压了Hadoop的压缩包。我们准备三台机器,并且预计将它们的职责设置如下机器角色172.19.65.196NameNode172.19.72.108DataNode172.19.72.112DataNode实现ssh免密访问在三台机器上面创建hadoop用户并且进入用户的根目录,在三台机器上执行命令创建ssh公私钥ssh-keygen -t rsa之后在NameNode上面执行cat ~/.ssh/id_rsa.pub获取到master节点的公钥,之后在三台机器(包括master节点自己)上面执行vi ~/.ssh/authorized_keys把获取到的master节点的公钥复制进去并..
更多