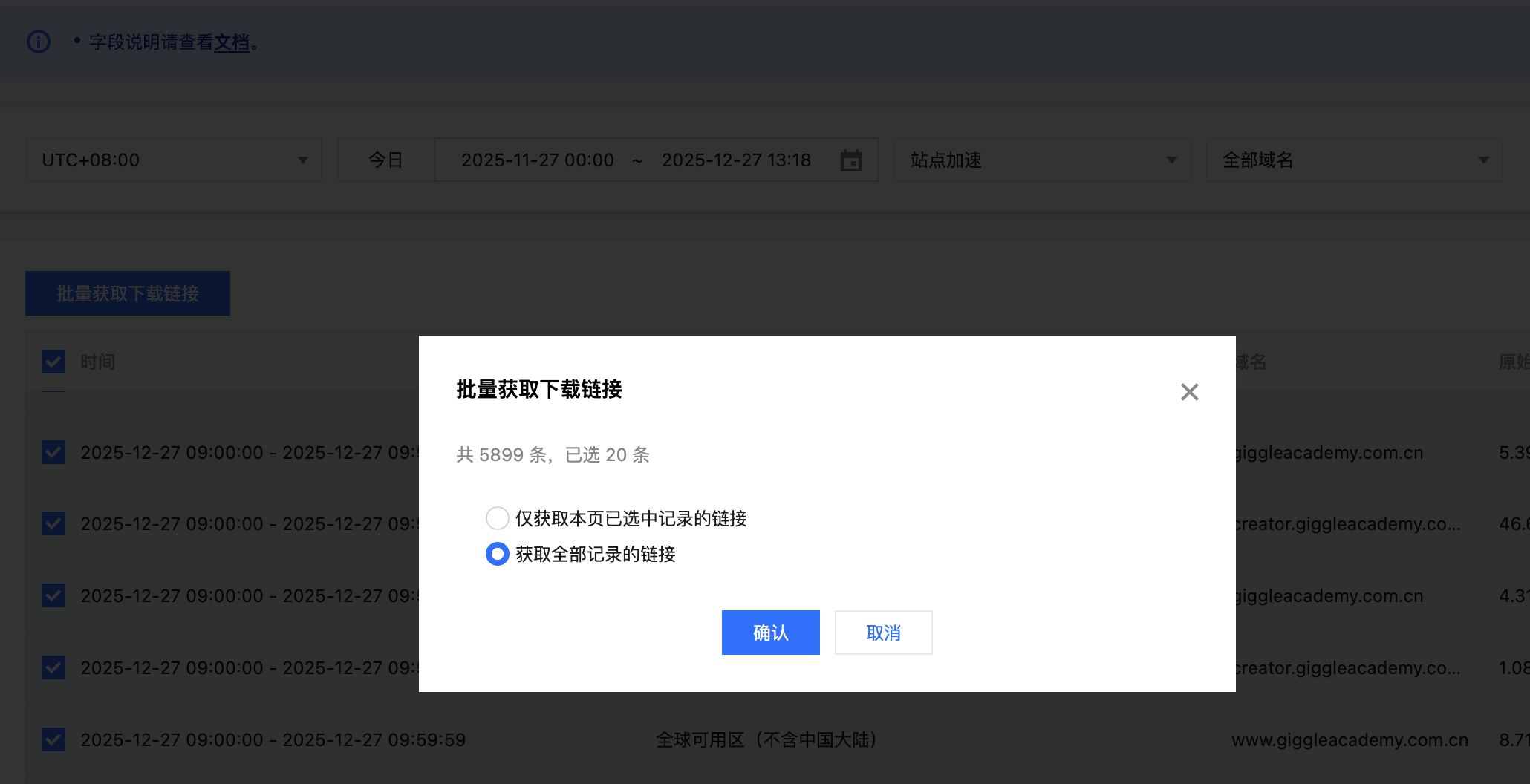
使用Elasticsearch分析腾讯云EO日志
腾讯云EO可以查看一些指标信息,但是更加详细的信息需要我们下载离线日志自行分析。获取日志下载链接腾讯云会将日志打包为.gz格式,解压后文件会包含多行,每一行都是一个JSON格式的数据,对应一条EO的请求日志,日志格式可以参考腾讯云文档。我们可以批量获取最近一个月的日志下载链接之后复制所有链接并保存到urls.txt文件中。启动Elasticsearch集群我们参考官方文档使用docker来启动集群,首先下载.env和docker-compose.yml,之后在.env文件中设置es和kibana的密码都是123456,然后设置STACK_VERSION=9.2.3。考虑到数据量比较大,可以提高容器的内存大小,我这里设置了一台8G。12345678910111213141516171819202122232..
更多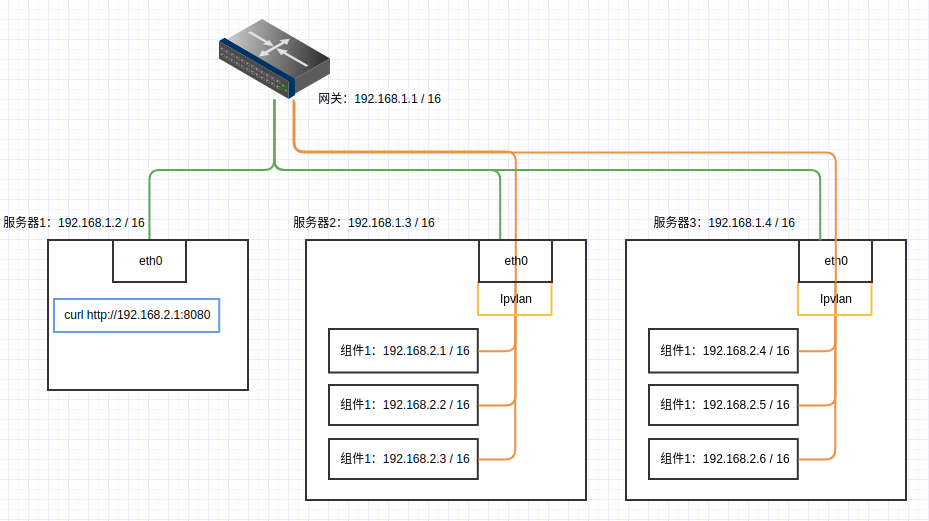
自建大数据分析集群
老项目老项目了这些都是。大部分都是十年前就出现的工具。感叹真是经久不衰。最近服务开发中,为了节约成本,弄了两个服务器,希望搭建一套数据分析平台,验证项目流程。查了很多资料对这些平台的搭建都非常简略,过程也是复杂,对新人很不友好,我也算是整理了一下相关的内容。简化服务搭建流程。得益于Docker的容器化,整个数据平台搭建起来非常方便整个过程里面,包含以下工具的搭建:HDFS,主要是用来存储数据YARN,提供资源调度,实现MR计算Hive on MR,基于MR的SQL引擎, 性能堪忧。也有基于Spark的,但是没有找到版本对应的公共镜像,就放弃了Spark Standalone,分布式计算框架,有基于YARN或者HIVE的版本,为了依赖纯粹,使用了独立集群Kafka on Kraft,为了依赖纯粹,使用了Kr..
更多DataX的简单使用
DataX是阿里巴巴开发的用于离线数据同步的工具,它支持在MySQL、Oracle、SqlServer、HDFS、HBase等多个数据库之间进行数据的离线同步。安装DataX我们可以直接下载已经打包好的文件wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz当然,我们也可以选择从源码编译安装DataX。由于上面的包已经比较旧了,推荐从源码进行安装。git clone https://github.com/alibaba/DataX.git因为我们只需要针对一些指定的数据库,所以可以删除pom.xml文件中我们不需要使用的数据库子模块。我保留的子模块如下12345678910111213<module>mys..
更多canal简单使用
在使用大数据进行数据计算的时候,首先我们需要获取到数据。如果是从MySQL获取数据的话,可以选择阿里的开源组件canal,它将自己伪装成MySQL的slave来接收数据。开启MySQL的binlog设置首先我们查看MySQL是否打开了binlog复制的功能mysql> show variables like 'log_bin';+---------------+-------+| Variable_name | Value |+---------------+-------+| log_bin | OFF |+---------------+-------+1 row in set (0.00 sec)如果没有打开,就编辑MySQL的配置文件/etc/my.cnf,添加如下配置# b..
更多HBase集群的搭建和使用
HBase是一个分布式的列族数据库,我们可以简单的将其看成一个kv数据库,每个[列 + rowkey + 时间戳]对应了一个单元格。下载HBase的压缩包并解压我们有三台机器,预计它们的角色将会如下Node NameMasterRegionServer172.19.65.196yesno172.19.72.108backupyes172.19.72.112noyes在官网下载HBase的压缩包并分发到三台机器上,然后解压压缩包。设置免密登录学习我们在HDFS的安装和使用中了解到的SSH免密登录的方法,设置196和108两台机器要能够免密访问所有的机器。搭建HDFS和ZooKeeper服务根据文章HDFS的安装和使用和ZooKeeper的简单介绍中所介绍的内容,搭建HDFS和ZooKeeper服务。修改配置..
更多ZooKeeper的简单介绍
用了很久的ZooKeeper了,稍微做个总结。ZooKeeper(以下简称ZK)是一个分布式组件,基于类似Paxos的ZAB一致性算法来实现。ZK保存的数据结构类似于一般的文件系统,只不过在ZK中文件夹也可以拥有数据,整体文件结构为一棵树型。安装ZooKeeper去官网下载压缩包,随后使用rsync同步到三台机器上,我使用如下三台机器172.19.65.196172.19.72.108172.19.72.112解压压缩包,使用cp conf/zoo_sample.cfg conf/zoo.cfg得到配置文件,在三台机器的conf/zoo.cfg中添加如下配置dataDir=/home/zookeeper/apache-zookeeper-3.8.0-bin/dataserver.1=172.19.65.1..
更多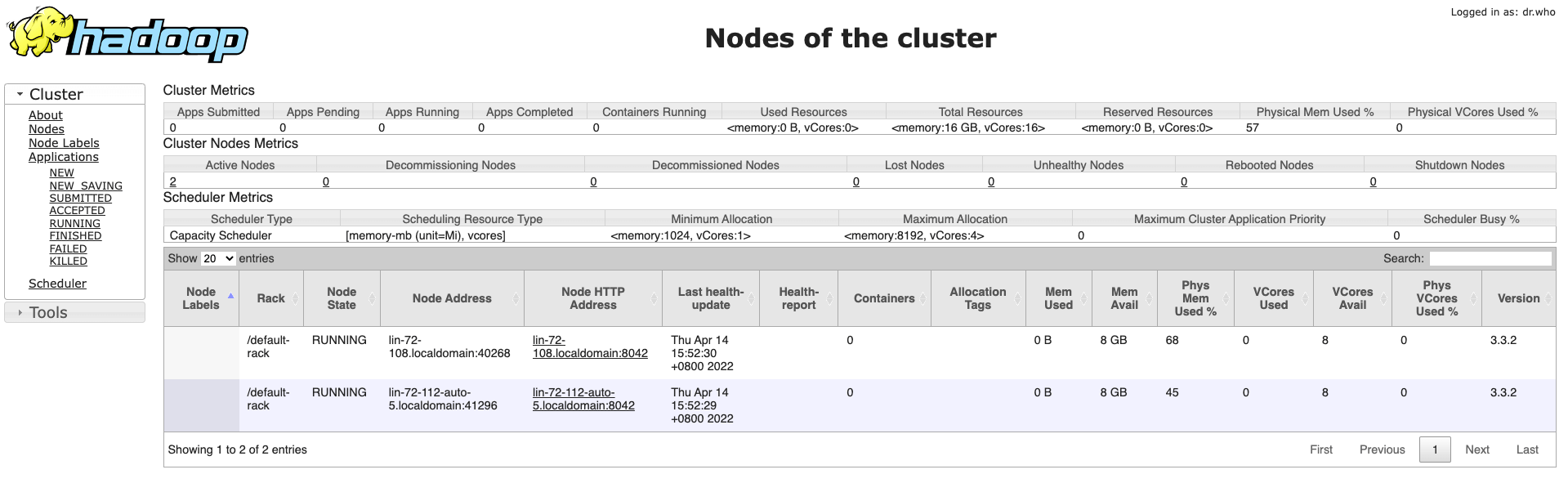
Hadoop中YARN和MapReduce的安装和使用
在上一篇文章中我们已经搭建好了HDFS环境,现在我们在这个环境的基础上继续搭建YARN和MapReduce环境。修改三台机器的etc/hadoop/mapred-site.xml文件,添加如下配置123456<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration>修改三台机器的etc/hadoop/yarn-site.xml文件,添加如下配置1234567891011121314<configurat..
更多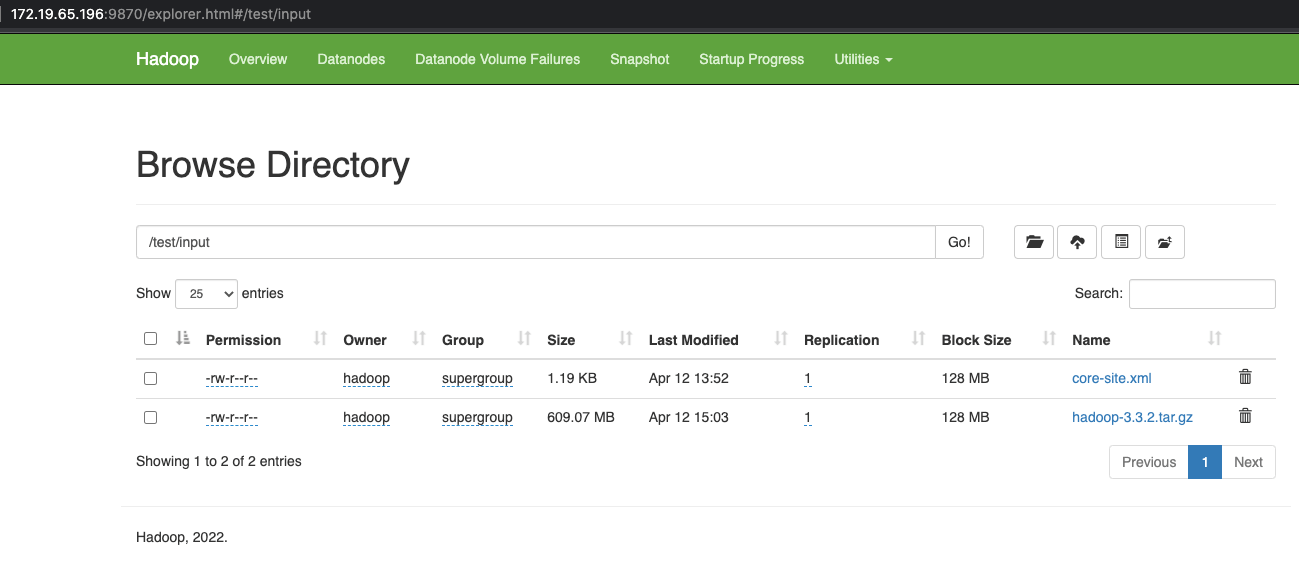
HDFS的安装和使用
正如在Hadoop学习笔记中所介绍的那样,我们已经安装好了Java环境并且设置好了JAVA_HOME环境变量,并且下载解压了Hadoop的压缩包。我们准备三台机器,并且预计将它们的职责设置如下机器角色172.19.65.196NameNode172.19.72.108DataNode172.19.72.112DataNode实现ssh免密访问在三台机器上面创建hadoop用户并且进入用户的根目录,在三台机器上执行命令创建ssh公私钥ssh-keygen -t rsa之后在NameNode上面执行cat ~/.ssh/id_rsa.pub获取到master节点的公钥,之后在三台机器(包括master节点自己)上面执行vi ~/.ssh/authorized_keys把获取到的master节点的公钥复制进去并..
更多Hadoop学习笔记
Hadoop用于提供可信赖的弹性分布式计算,hadoop使得我们可以把计算逻辑分布到海量的机器上面去以提升计算性能并且实现高可用。Hadoop分为以下四个模块模块功能通用模块用于支撑Hadoop的工具模块Hadoop Distributed File System (HDFS)分布式的文件系统YARN用于任务调度和集群资源管理的框架MapReduce基于YARN的海量数据并行处理系统HDFS模块HDFS模块用于存储数据,它的核心思想是Google的GFS,即把数据分成块(block)存储在多个机器上,同时每个块可能还会有多个备份以保证数据的高可用。HDFS运行在多个节点之上,不同的节点可能有不同的身份。节点类型节点介绍命名节点(NameNode)命名节点用于管理其它存储节点,是“管理员”节点并且只有一个,..
更多