一日一技:自动提取任意信息的通用爬虫
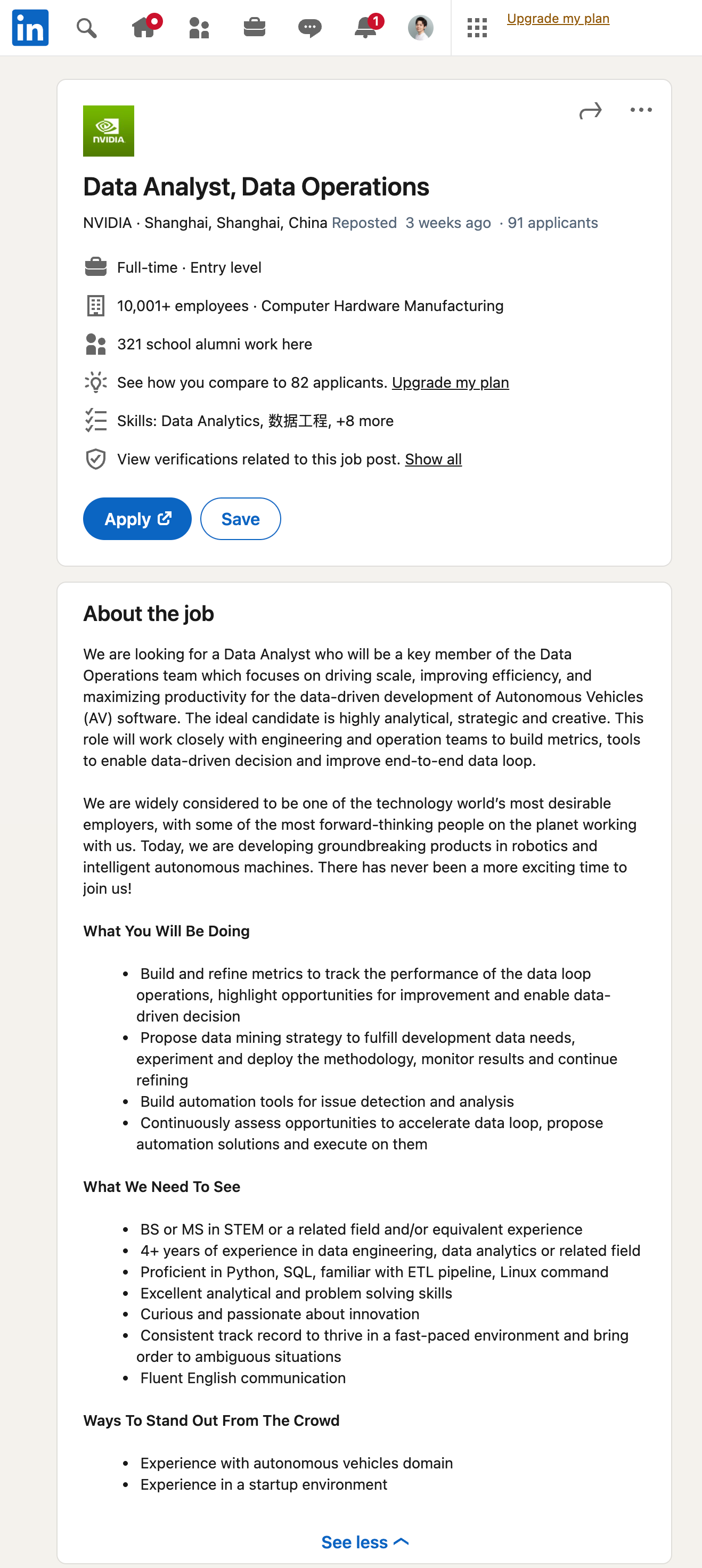
使用过GNE的同学都知道,GNE虽然是通用爬虫,但只是文章类页面的通用爬虫。如果一个页面不是文章页,那么就无能为力了。随着ChatGPT引领的大语言模型时代到来,这个问题基本上已经不是问题了。我们先来看一个效果。首先打开Linkedin,随便找一个招聘的岗位,如下图所示:然后,我们直接使用GPT从这里提取信息:对应的Prompt为:12345你是一个数据提取小助手,能够从一大段招聘相关的文本中提取有用的信息并以JSON格式返回。{经过清洗的网页源代码或者文本}请从上面的文本中,提取招聘相关的信息,返回数据格式如下: {"title": "岗位名称", "full_time": "是否为全职", "employee_num": "雇员数量", "level": "岗位等级", "skill": "岗位需要的..
更多
GnePro:文章类通用爬虫接口
GnePro是开源项目GNE的付费版,能够实现如下功能:输入任意文章页面的URL,返回标题/作者/正文/发布时间/图片/面包屑等一系列信息支持异步加载文章页提取支持上传自定义的HTML代码提取正文支持自动检测网页编码支持自动提取网页全部URL在8个国家13万个新闻类网站进行测试,准确率高达90%提取文章正文12345678910111213141516171819import requestsimport jsonurl = "https://crawler.kingname.info/gne/crawl"body = { "url": "https://www.kingname.info/2023/10/17/rubbish/", "js": False, "charset": "auto"}he..
更多
助力大语言模型训练,无压力爬取六百亿网页
ChatGPT一炮而红,让国内很多公司开始做大语言模型。然后他们很快就遇到了第一个问题,训练数据怎么来。有些公司去买数据,有些公司招聘爬虫工程师。但如果现在才开发爬虫,那恐怕已经来不及了。即使爬虫工程师非常厉害,可以破解任意反爬虫机制,可以让爬虫跑满网络带宽,可是要训练出GPT-3这种规模的大语言模型,这个数据并不是一天两天就能爬完的。并且,有很多老网站的数据,早就被删除了,爬虫想爬也爬不到。如果你看了今天这篇文章,那么恭喜你,你即将知道如何快速获取600亿网站的数据。从2008年开始爬取,这些网站数据横跨40多种语言。截止我写这篇文章的时候,最新的数据积累到了2023年2月。只要是Google现在或者曾经搜索得到的网站,你在这里都能找到。唯一制约你的,就是你的硬盘大小——仅仅2023年1月和2月的网页加..
更多