一日一技:怎么中文也属于字母?
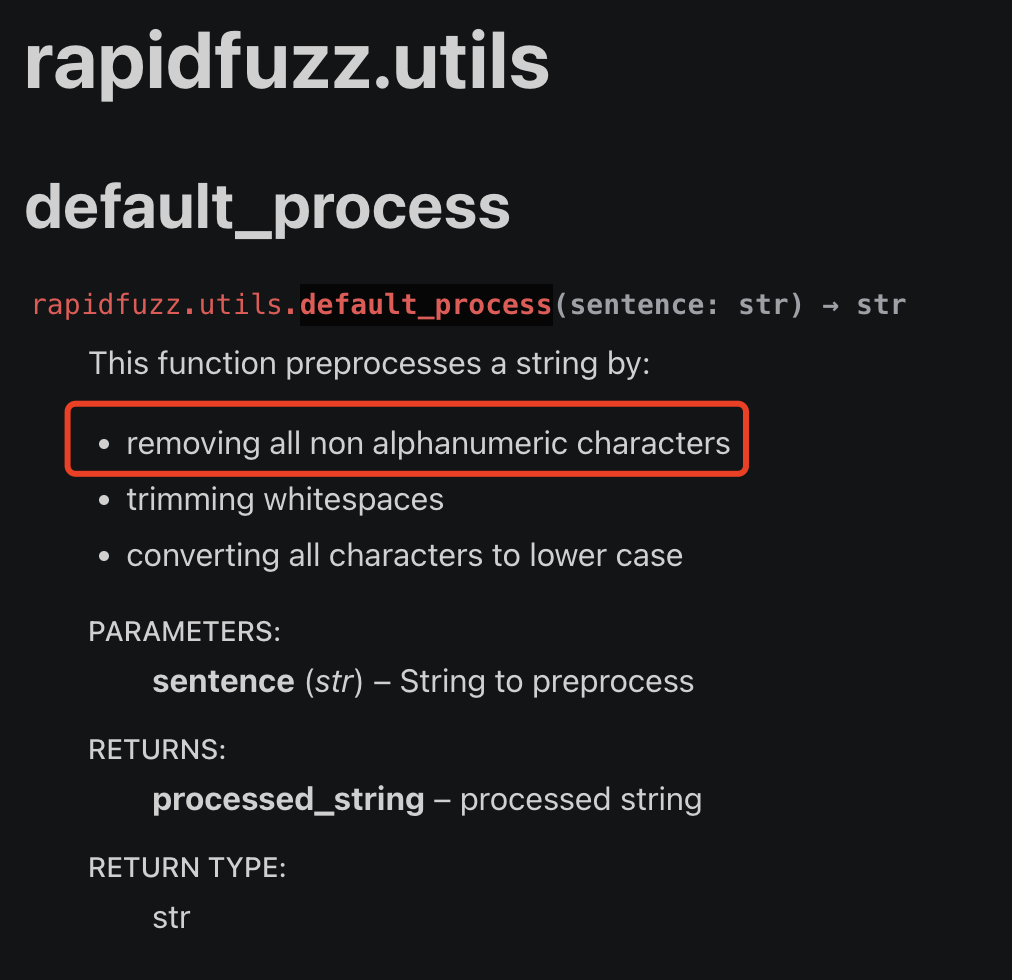
我最近在使用一个第三方库,叫做RapidFuzz。它有一个工具函数,叫做utils.default_process,在官方文档里面,是这样介绍的:红色方框里面说,这个函数可以移除所有的非alphanumeric字符。如果我们使用翻译软件,会发现alphanumeric的意思是字母和数字。如下图所示:因此,我想当然的觉得,这个功能函数,只会保留26个英文字母的大小写加上10个数字,一共62个字符。把除此之外的所有其他字符都移除掉。但我经过测试,它竟然没有办法过滤掉中文字符,如下图所示。难道终于也属于字母?于是我到Github上面去给这个项目提Issue。但作者却说这个函数没有问题,并且使用Python的.isalnum()来做测试,发现Python也会认为中文也是alphanumeric。如下图所示:这就非常奇怪..
更多一种 IPv6 地址编码方案
又搞了一些骚操作:把一个 IPv6 地址压缩成一个短字符串。 背景 线上某张表有一个 VARCHAR 字段,用于存储 IP 地址。之前只存储 IPv4 地址,而 IPv4 地址的最大长度为 15(如 255.255.255.255),因此字段宽度只设置了 20。 当我们要存储 IPv6 地址时,却发现 IPv6 地址的最大长度是 39(如 1111:2222:3333:4444:5555:6666:7777:8888),而变更字段类型的尝试也以失败告终,因此我们需要找到一种方法来将 v6 IP 塞进长度为 20 的 VARCHAR 字段中。 一些简单的尝试 随便找一个 v6 IP,如 240e:17:ce8:fd00:52a8:6001:6e05:96f6,然后尝试将它缩短。 去掉冒号是否可行? 去掉冒..
更多