自建大数据分析集群
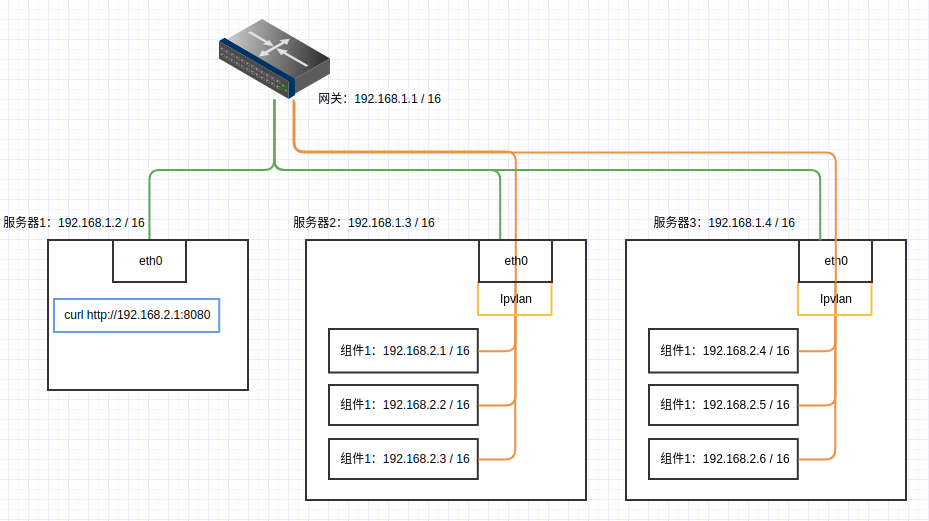
老项目老项目了这些都是。大部分都是十年前就出现的工具。感叹真是经久不衰。最近服务开发中,为了节约成本,弄了两个服务器,希望搭建一套数据分析平台,验证项目流程。查了很多资料对这些平台的搭建都非常简略,过程也是复杂,对新人很不友好,我也算是整理了一下相关的内容。简化服务搭建流程。得益于Docker的容器化,整个数据平台搭建起来非常方便整个过程里面,包含以下工具的搭建:HDFS,主要是用来存储数据YARN,提供资源调度,实现MR计算Hive on MR,基于MR的SQL引擎, 性能堪忧。也有基于Spark的,但是没有找到版本对应的公共镜像,就放弃了Spark Standalone,分布式计算框架,有基于YARN或者HIVE的版本,为了依赖纯粹,使用了独立集群Kafka on Kraft,为了依赖纯粹,使用了Kraft..
更多