
一日一技:Scrapy如何发起假请求?
摄影:产品经理韩国章肥虾。在使用Scrapy的时候,我们可以通过在pipelines.py里面定义一些数据处理流程,让爬虫在爬到数据以后,先处理数据再储存。这本来是一个很好的功能,但容易被一些垃圾程序员拿来乱用。我看到过一些Scrapy爬虫项目,它的代码是这样写的:1234567891011...def start_requests(self): yield scrapy.Request('https://baidu.com')def parse(self, response): import pymongo handler = pymongo.MongoClient().xxdb.yycol rows = handler.find() for row in rows: ..
更多一日一技:在Scrapy中如何拼接URL Query参数?
我们知道,在使用Requests发起GET请求时,可以通过params参数来传递URL参数,让Requests在背后帮你把URL拼接完整。例如下面这段代码:12345678910111213# 实际需要请求的url参数为:# https://www.kingname.info/article?id=1&doc=2&xx=3import requestsparams = {'id': '1','doc': '2','xx': '3'}requests.get('https://www.kingname.info/article', params=params)那么在Scrapy中,发起GET请求时,应该怎么写才能实现这种效果呢?我知道很多同学是通过字符串的format操作来拼接URL的:12345..
更多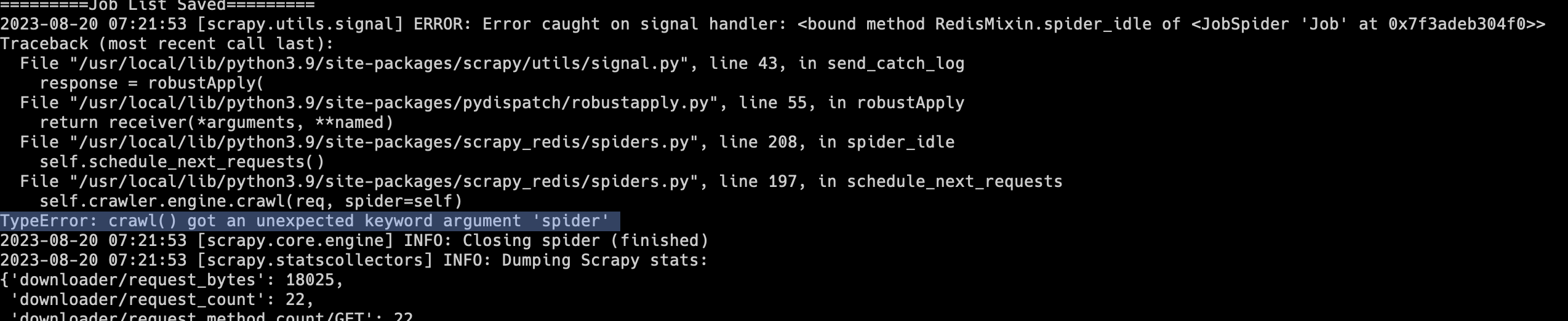
一日一技:Scrapy最新版不兼容scrapy_redis的问题
有不少同学在写爬虫时,会使用Scrapy + scrapy_redis实现分布式爬虫。不过scrapy_redis最近几年更新已经越来越少,有一种廉颇老矣的感觉。Scrapy的很多更新,scrapy_redis已经跟不上了。大家在安装Scrapy时,如果没有指定具体的版本,那么就会默认安装最新版。这两天如果有同学安装了最新版的Scrapy和scrapy_redis,运行以后就会出现下面的报错:1TypeError: crawl() got an unexpected keyword argument 'spider'如下图所示:遇到这种情况,解决方法非常简单,不要安装Scrapy最新版就可以了。在使用pip安装时,绑定Scrapy版本:1python3 -m pip install scrapy==2.9.0
更多