一日一技:如何使用大模型提取结构化数据
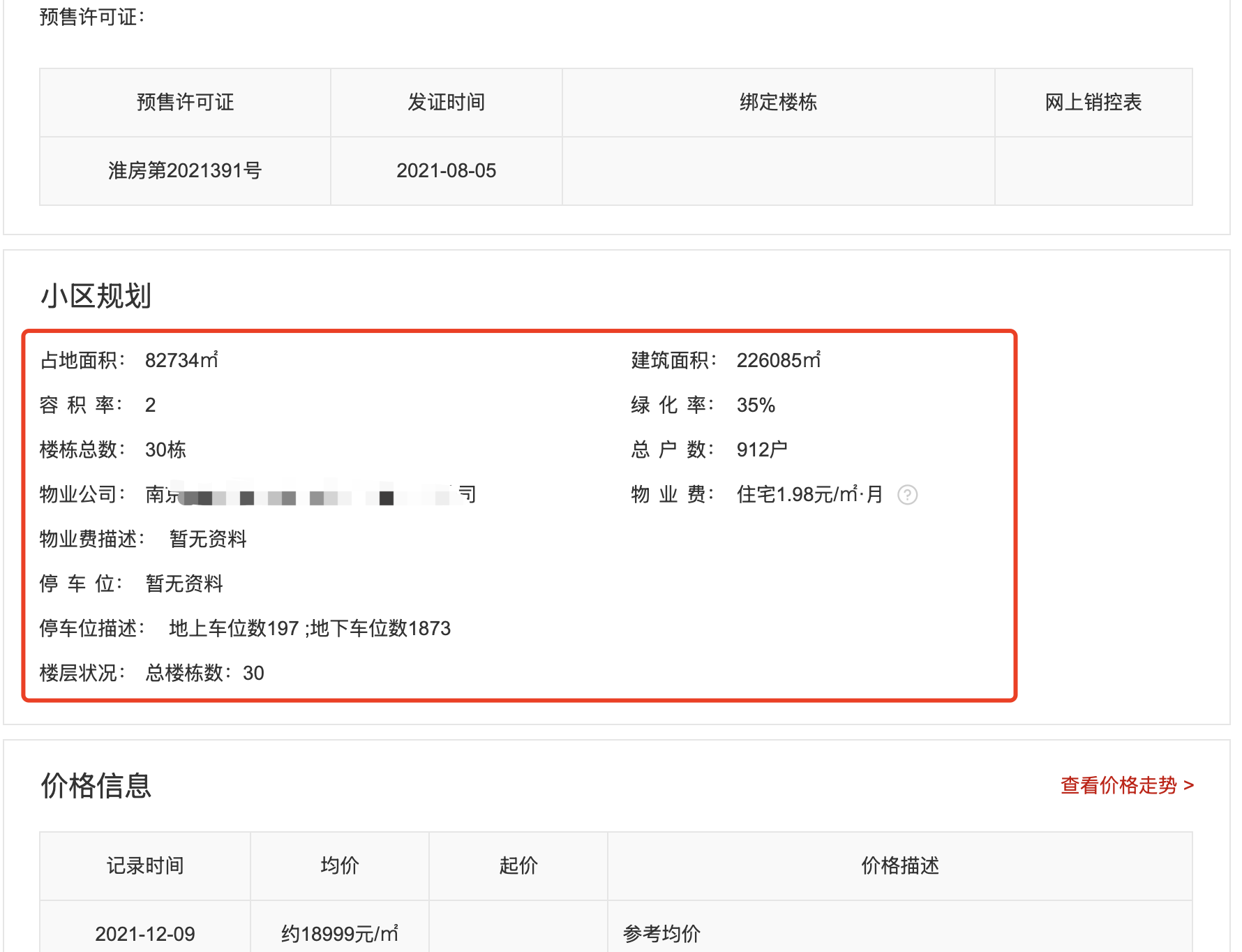
经常有同学在微信群里面咨询,如何使用大模型从非结构化的信息里面提取出结构化的内容。最常见的就是从网页源代码或者长报告中提取各种字段和数据。最直接,最常规的方法,肯定就是直接写Prompt,然后把非结构化的长文本放到Prompt里面,类似于下面这段代码:1234567891011121314151617from zhipuai import ZhipuAIclient = ZhipuAI(api_key="") # 填写您自己的APIKeyresponse = client.chat.completions.create( model="glm-4-air-0111", messages=[ {"role": "system", "content": '''你是一个数据提取专家,非..
更多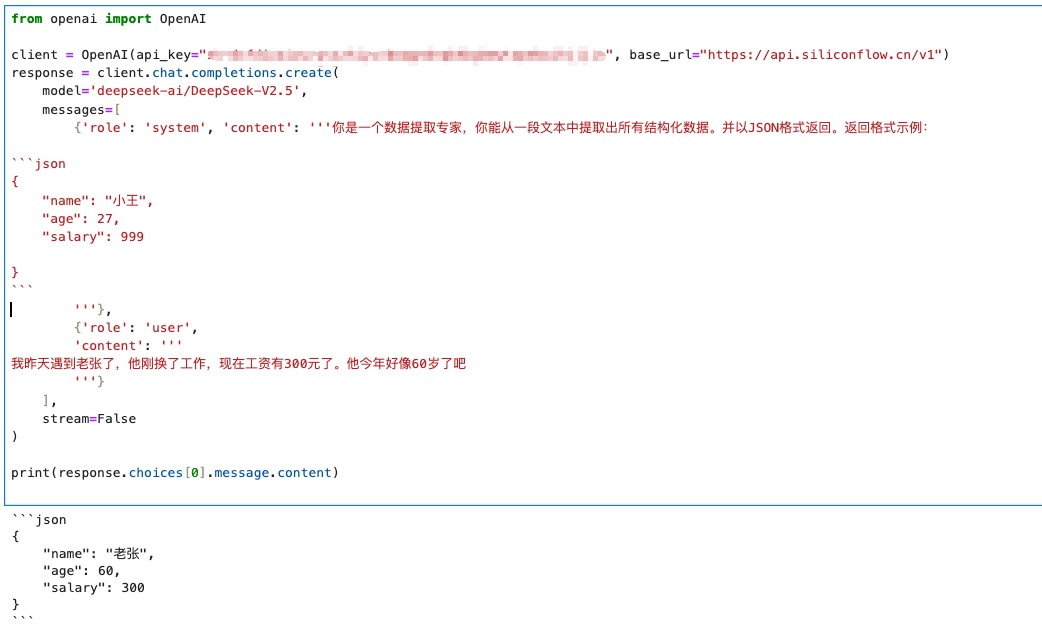
一日一技:超简单方法显著提高大模型答案质量
很多人都知道Prompt大神李继刚,他使用Lisp语法来写Prompt,把大模型指挥得服服帖帖。但我们很多时候没有办法把自己业务场景的Prompt改造成伪代码的形式。相信不少人跟我一样,会使用Markdown格式来写Prompt,大部分时候没什么问题,但偶尔总会发现大模型返回的结果跟我们想要的不一样。Markdown的弊端例如下图所示:让大模型给我返回一个JSON,它返回的时候会用Markdown的多行代码格式来包装这个JSON。我后续要解析数据时,还得使用字符串切分功能把开头结尾的三个反引号去掉。即便我把system prompt里面的反引号去掉,改成:1234567你是一个数据提取专家,你能从一段文本中提取出所有结构化数据。并以J50N格式返回。返回格式示例:{"name": "小王","age": ..
更多
一日一技:为什么我很讨厌LangChain
一说到RAG或者Agent,很多人就会想到LangChan或者LlamaIndex,他们似乎觉得这两个东西是大模型应用开发的标配。但对我来说,我特别讨厌这两个东西。因为这两个东西就是过度封装的典型代表。特别是里面大量使用依赖注入,让人使用起来非常难受。什么是依赖注入假设我们要在Python里面模拟出各种动物的声音,那么使用依赖注入可以这样写:12345678910111213141516171819202122def make_sound(animal): sound = animal.bark() print(f'这个动物在{sound}')class Duck: def bark(self): return '嘎嘎叫'class Dog: def bark(sel..
更多
一日一技:使用大模型实现全自动爬虫(一)
在文章一日一技:图文结合,大模型自动抓取列表页中,我提到可以使用大模型实现一个全自动爬虫。只需要输入起始URL加上需求,就可以借助模拟浏览器自动完成所有的抓取任务。在实现的过程中,我发现涉及到的知识点可能一篇文章讲不完,因此拆分成了多篇文章。爬虫演示今天是第一部分,我们暂时不依赖模拟浏览器,而是使用httpx(你也可以使用requests)实现全自动爬虫,传入我博客文章列表页,爬虫会自动抓取前三页所有博客文章的标题、正文、作者、发布时间。爬取结果如下图所示:运行过程如下图所示:爬虫首先会进入起始列表页,抓取上面的所有文章。然后进入列表页第二页,再抓取所有文章,最后进入第三页,再抓取所有文章。整个过程都是全自动的。不需要写任何XPath,也不需要告诉爬虫哪里是翻页按钮,文章的标题在哪里,发布时间在哪里,正文..
更多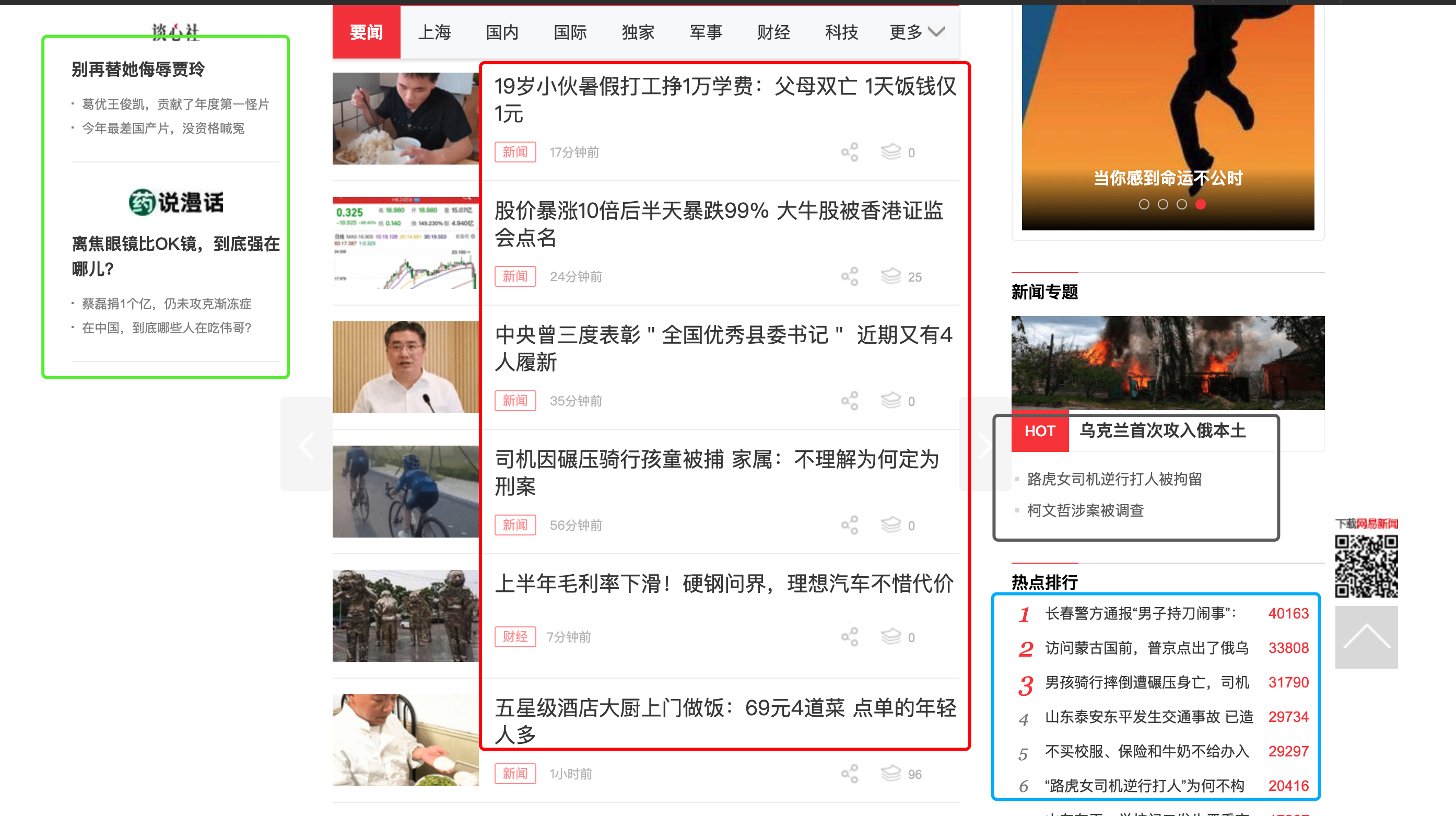
一日一技:图文结合,大模型自动抓取列表页
熟悉我的同学都知道,GNE可以自动化提取任意文章页面的正文,专业版GnePro的准确率更是在13万个网站中达到了90%。但GNE一直不支持列表页的自动抓取。这是因为列表页的列表位置很难定义。例如下面这张图片:对人来说,要找到文章列表很简单,红色方框框住的部分就是我们需要的文章列表。但如果让程序自动根据HTML格式相似的规律来寻找列表页,它可能会提取出蓝色方框的位置、绿色方框的位置、灰色方框的位置,甚至导航栏。之前我也试过使用ChatGPT来提取文章列表,但效果并不理想。因为传给大模型HTML以后,他也不能知道这里面某个元素在浏览器打开以后,会出现什么位置。因此它本质上还是通过HTML找元素相似的规律来提取列表项目。那么其实没有解决我的根本问题,上图中的蓝色、绿色、灰色位置还是经常会提取到。前两天使用GLM..
更多
一日一技:如何使用大模型提高开发效率
前两天,有同学在微信群里面问怎么识别下图所示的验证码:一般爬虫验证码我会使用ddddocr来解析,在大模型出来之前,这个工具基本上是Python下面效果最好的免费验证码识别工具了。但是这次它翻车了。这个提问的同学也试过了很多个大模型,发现都提取不出来。甚至连GPT-4o也失败了:GPT-4o都失败了,还能怎么办呢?难道要使用付费的商业方案了?这个时候,突然有个同学发出来了一张截图:ChatGLM,也就是智谱AI,竟然识别对了!这个同学接着又发了一张图,另一个验证码识别又对了!甚至连四则运算验证码都能识别:这下整个群里面做爬虫的人都热闹了起来:于是就有了今天这篇文章。上面的截图是使用智谱AI网页版识别的,但是我们写代码时肯定需要使用API。智谱AI的大模型叫做GLM,也提供开放API服务。于是我到智谱AI ..
更多
一日一技:效率翻倍,国产大模型App的正确应用
利益不相关声明,今天介绍的所有工具,都跟我没有任何软文合作,也没有金钱往来。我在这篇文章里面对他们做介绍仅仅是因为他们对我确实非常有用。最近几个月,国产大模型相继推出了自己的 App,这些 App 不仅可进行 AI 对话,还能提供各种智能工具。谈论AI对话功能的文章太多了,我就不赘述了。今天聊聊他们的其他功能。不可否认,国产大模型比国外的大模型差了不少,但我一向秉持重器轻用的观点,我不管这些App提供了多少功能,我只看它里面有没有功能适合我,即便它提供了100个功能,我可能只会使用它其中一个适合我的功能。第一个介绍的工具是豆包中的语音识别功能。虽然字节跳动的大模型做得很一般,在国内都排不上前三名。但我发现豆包的语音识别做的非常好——速度极快,准确率也很高。而且可以让他们的模型对转录出来的文本做一些修饰,移..
更多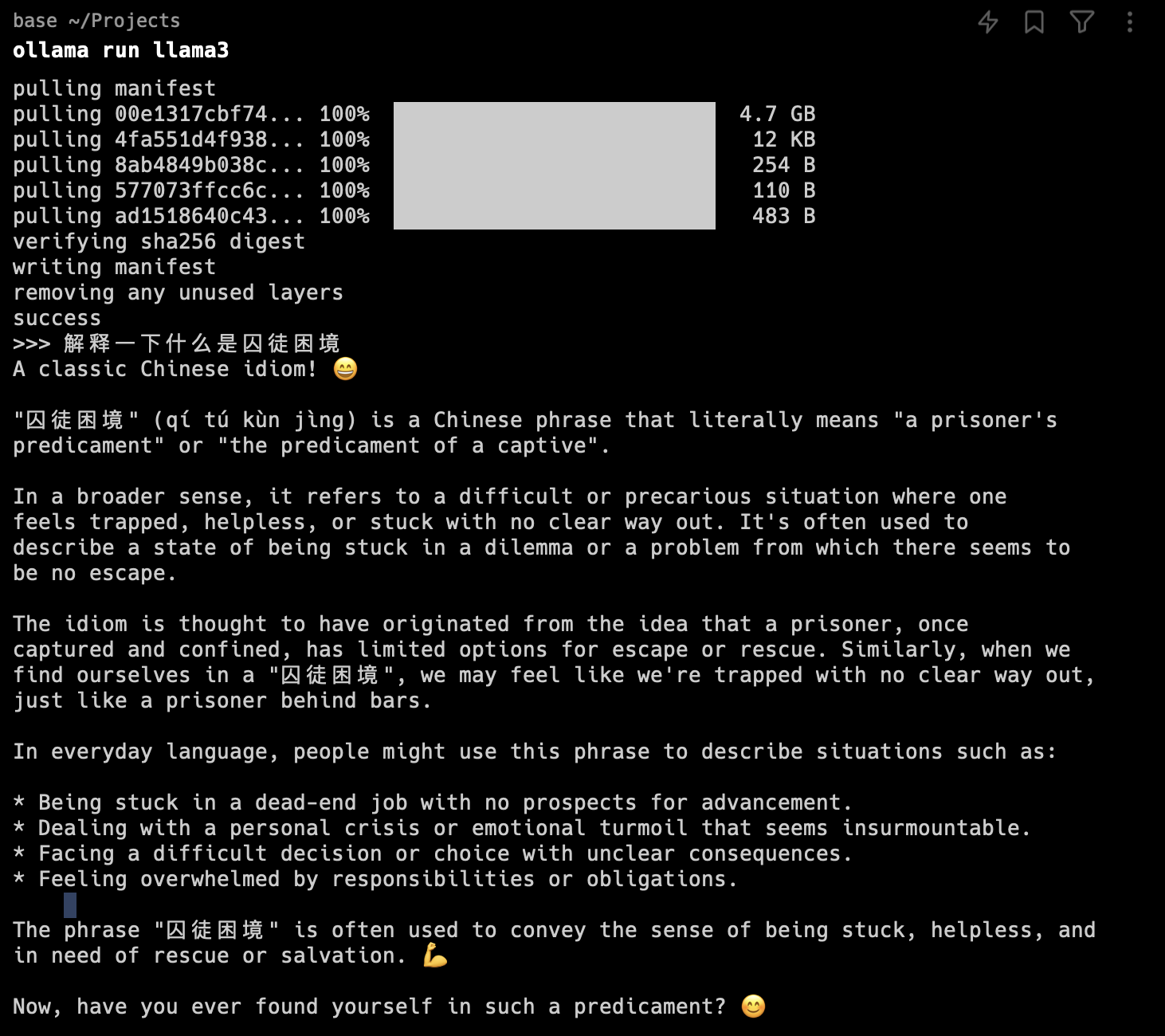
一日一技:如何强迫LLama3用中文回复?
最近大家都在说LLama3如何如何强大,追赶Claude3,超过GPT 4。但如果大家真的使用过,就会发现它连基本的中文都回答不好。如下图所示:LLama3总是尽可能回复英文,并且还会加很多表情符号。今天网上出现了一个中文微调版的LLama3:shenzhi-wang/Llama3-8B-Chinese-Chat,我也下载下来使用了,发现确实回复都是中文了,但回复的都是车轱辘话,一句话反复说。如下图所示:那么有没有什么办法,能够让LLama3既能回复中文,又能回复得聪明一些呢?网上有一段“生气的老奶奶”Prompt,可以尽可能让LLama3满足要求:123456问题Rules:- Be precise, do not reply emoji.- Always response in Simplified ..
更多
一日一技:2秒抓取网页并转换为markdown
在《一日一技:自动提取任意信息的通用爬虫》这篇文章中,我提到可以通过大模型从网页内容里面提取结构化信息。为了节省Token,文章里面我直接提取了页面上的所有文本。这种方式需要自己写代码来过滤HTML中的垃圾标签。并且提取出来的文本可能会混在一起。虽然大模型在很大程度上不会受到标点符号的影响。但如果有办法把网页直接转换为Markdown的话,大模型在解析时就能更加准确。现在,你不需要写任何代码就可以实现这个目标!假设我们需要抓取我的这篇知乎专栏文章:小问题,大隐患:如何正确设置 Python 项目的入口文件?。我们知道知乎是有反爬虫的,直接抓取并不容易。怎么样在2秒内抓取这篇文章,并转换为Markdown呢?非常简单,你只需要在url前面加上https://r.jina.ai/并回车就可以了。完整的URL变..
更多