介绍
文本匹配是研究两段文本之间的关系。
此处介绍两种,分别是point-wise和pair-wise语义匹配模型。
point-wise是ptm+二分类,判断句子相似度。
pair-wise是ptm+score,判断两个句子相似度得分,可用于排序。最近实现了一个,可参考pairwise-match。
粗排方面有sentence transformer以及SimBERT,再比如DSSM。
这些先记下,等后面有时间了再实现总结。
更新
关于双塔模型中的sentence transformer,网络结构如下:
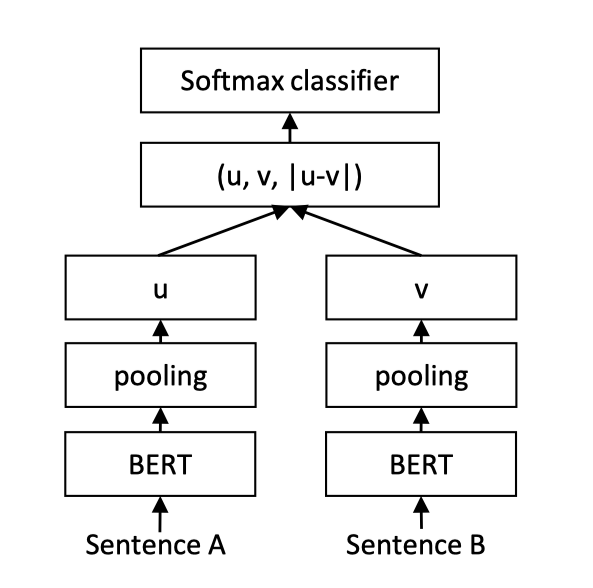
其中pooling为比如Sentence的维度为(1,7,768),那么就对7那一维做mean操作。
由于共用同一个pretrained model,将向量提前保存到数据库。当用户搜索query时,只需计算query的sequence_output特征与保存在数据库中的title sequence_output特征,通过一个简单的mean_pooling和全连接层进行二分类即可。从而大幅提升预测效率,同时也保障了模型性能。