LoRA
peft
https://mp.weixin.qq.com/s/kEGwA_7qAKhIuoxPJyfNuw
https://aistudio.baidu.com/aistudio/projectdetail/5567217
介绍
自从chatGPT出来后,好多人/机构开始尝试使用chatGPT来生成训练数据,简单省事方便。比如google bard,对,就是你,也有在偷偷使用。本文介绍一个项目BELLE,来看看大佬们是怎么做的。注意:此文重点在于如何生成数据。
利用chatGPT生成训练数据
最开始BELLE的思想可以说来自stanford_alpaca,不过在我写本文时,发现BELLE代码仓库更新了蛮多,所以此处忽略其他,仅介绍数据生成。
代码入口:generate_instruction_following_data。
1. 加载zh_seed_tasks.json
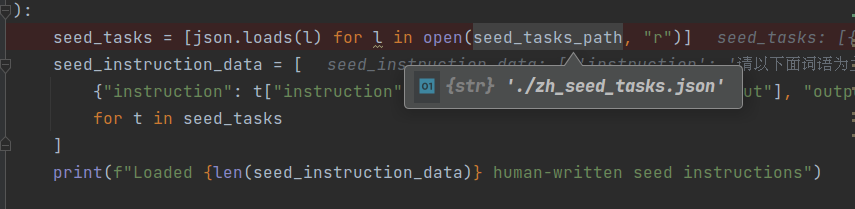
默认提供了175个种子任务,样例如下图

2. encode_prompt
注意此处,看看如何构造chatGPT的输入以及chatGPT的输出。
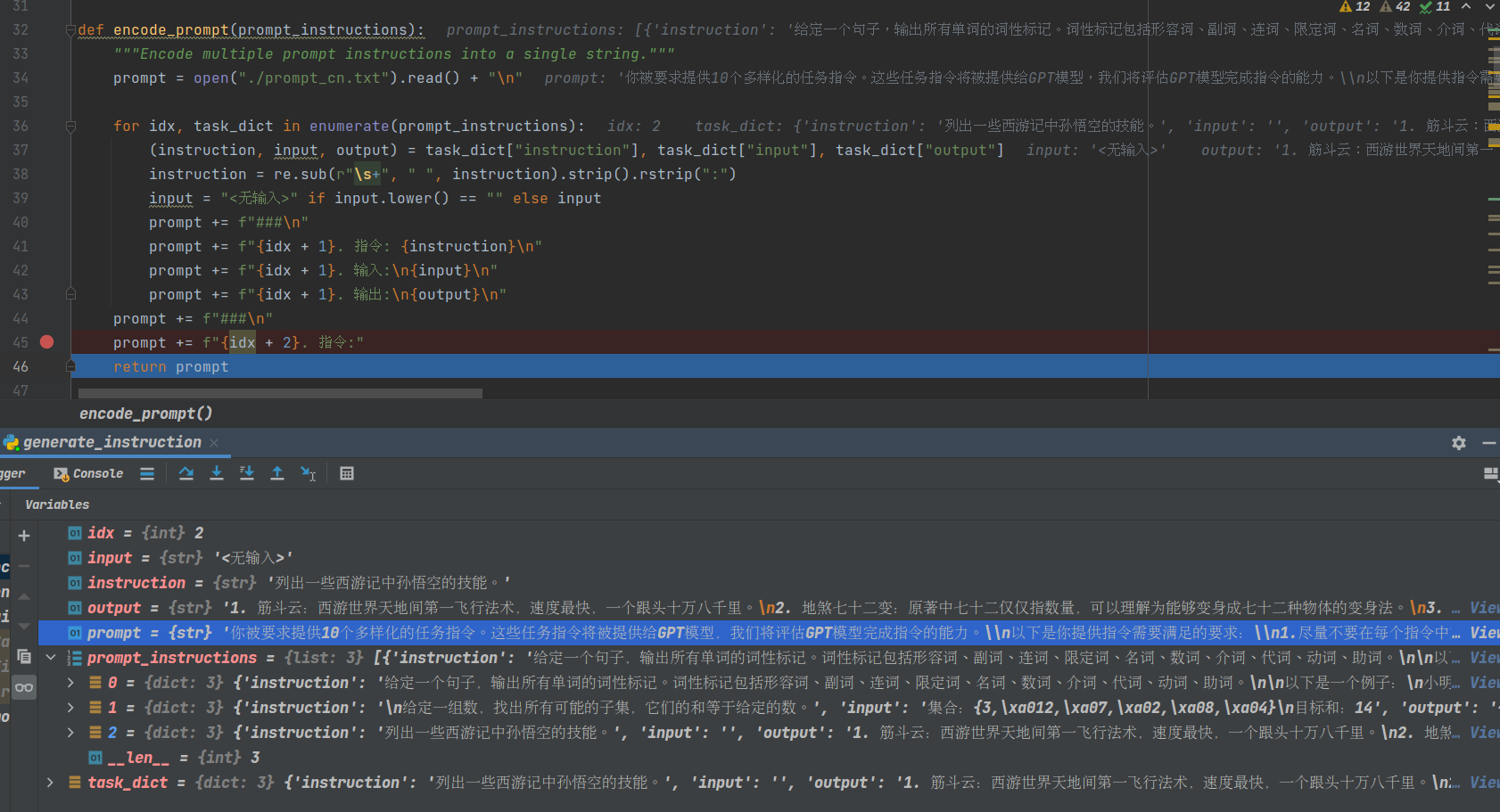
最终prompt如下图所示
1 | 你被要求提供10个多样化的任务指令。这些任务指令将被提供给GPT模型,我们将评估GPT模型完成指令的能力。\n以下是你提供指令需要满足的要求:\n1.尽量不要在每个指令中重复动词,要最大化指令的多样性。\n2.使用指令的语气也应该多样化。例如,将问题与祈使句结合起来。\n3.指令类型应该是多样化的,包括各种类型的任务,类别种类例如:brainstorming,open QA,closed QA,rewrite,extract,generation,classification,chat,summarization。\n4.GPT语言模型应该能够完成这些指令。例如,不要要求助手创建任何视觉或音频输出。例如,不要要求助手在下午5点叫醒你或设置提醒,因为它无法执行任何操作。例如,指令不应该和音频、视频、图片、链接相关,因为GPT模型无法执行这个操作。\n5.指令用中文书写,指令应该是1到2个句子,允许使用祈使句或问句。\n6.你应该给指令生成适当的输入,输入字段应包含为指令提供的具体示例,它应该涉及现实数据,不应包含简单的占位符。输入应提供充实的内容,使指令具有挑战性。\n7.并非所有指令都需要输入。例如,当指令询问一些常识信息,比如“世界上最高的山峰是什么”,不需要提供具体的上下文。在这种情况下,我们只需在输入字段中放置“<无输入>”。当输入需要提供一些文本素材(例如文章,文章链接)时,就在输入部分直接提供一些样例。当输入需要提供音频、图片、视频或者链接时,则不是满足要求的指令。\n8.输出应该是针对指令和输入的恰当回答。 \n下面是10个任务指令的列表: |
由于没有OPENAI_API_KEY,所以咱们此处构造下results的结果,来看看post_process_gpt3_response的处理。
3. post_process_gpt3_response
1 | results = [ |
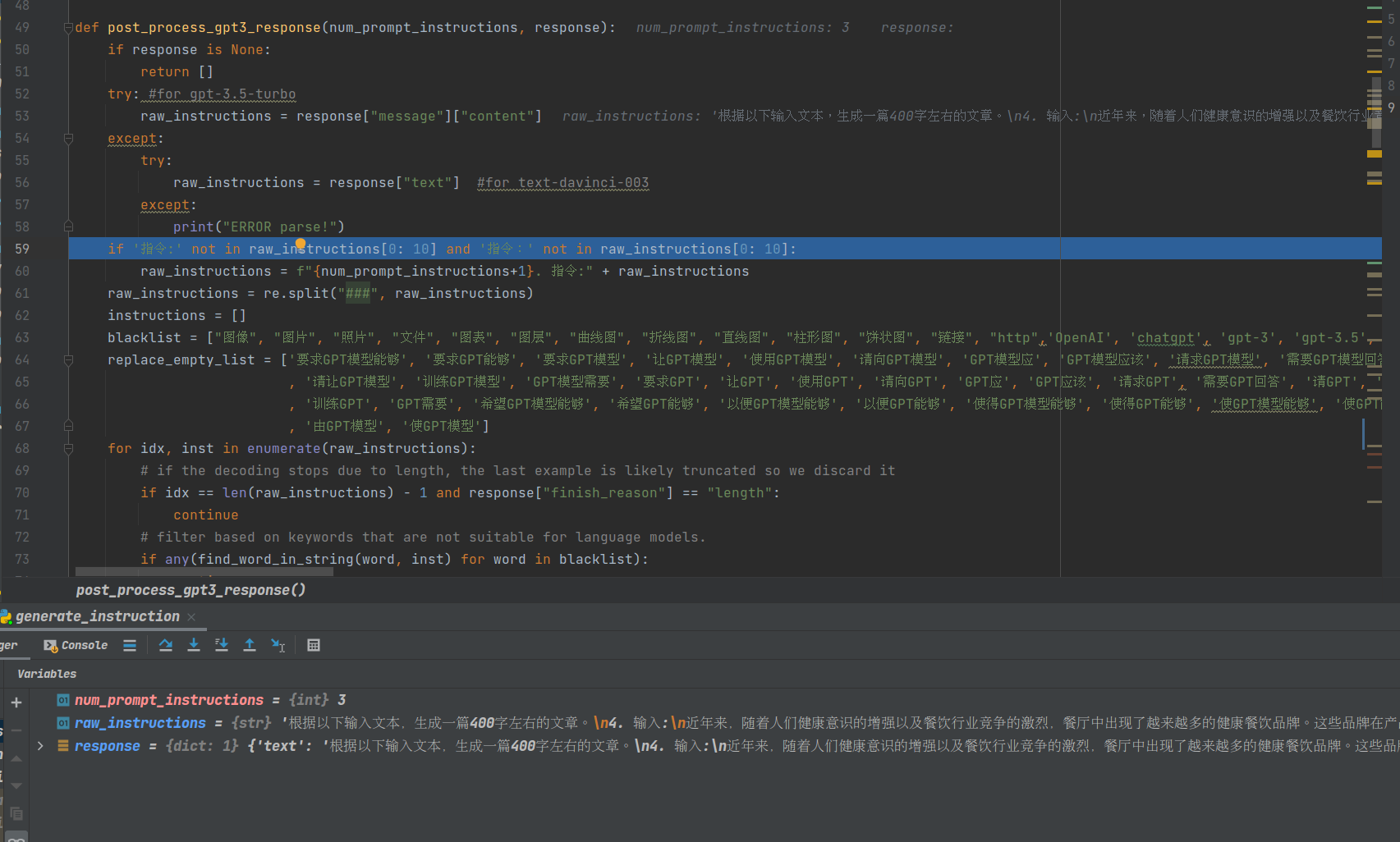
可看到,具体做了一些chatGPT回复内容的后处理操作。比如过滤黑名单,chatGPT回复内容提出input、output、instruction。
4. bm25计算instruction相似度
这步也是后处理,计算chatGPT生成的instruction和已经拥有的instructions的相似度,如果大于阈值,就忽略掉生成的这个instruction。
最后
在huggingface上可看到作者生成的数据,比如train_0.5M_CN,train_1M_CN,这俩构成了作者宣称的1.5M数据集,当然还有一个10M的数据集。更多可看BelleGroup Datasets。