说到Python装饰器的执行顺序,有很多半吊子张口就来:
靠近函数名的装饰器先执行,远离函数名的装饰器后执行。
这种说法是不准确的。但是这些半吊子多半还会不服,他们会甩出一段代码给你,来『证明』自己的观点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def decorator_outer(func):
print("我是外层装饰器")
def wrapper():
func()
return wrapper
def decorator_inner(func):
print("我是内层装饰器")
def wrapper():
func()
return wrapper
@decorator_outer
@decorator_inner
def func():
print("我是函数本身")
func()
|
运行效果如下图所示:

decorator_inner这个装饰器靠近函数名,是内层装饰器,他里面的print先打印出来;decorator_outer远离函数名,是外层装饰器,它里面的print后打印出来。看起来确实是内层装饰器先执行,外层装饰器后执行。
为什么我说这种看法是不准确呢?我们来看看下面这段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| def decorator_outer(func):
print("我是外层装饰器")
print('a')
print('b')
def wrapper():
print('外层装饰器,函数运行之前')
func()
print('外层装饰器,函数运行之后')
print('外层装饰器闭包初始化完毕')
print('c')
print('d')
return wrapper
def decorator_inner(func):
print("我是内层装饰器")
print(1)
print(2)
def wrapper():
print('内层装饰器,函数运行之前')
func()
print('内层装饰器,函数运行之后')
print('内层装饰器闭包初始化完毕')
print(3)
print(4)
return wrapper
@decorator_outer
@decorator_inner
def func():
print("我是函数本身")
func()
|
上面这个代码的运行效果如下图所示:

从图中可以看到,装饰器里面的代码中,wrapper闭包外面的代码确实是内层装饰器先执行,外层装饰器后执行。但是在闭包wrapper内部的代码,却稍微复杂一些:
- 外层装饰器先执行,但只执行了一部分,执行到调用
func() - 内层装饰器开始执行
- 内层装饰器执行完
- 外层装饰器执行完
这个执行效果有点类似于:
1
2
3
4
5
6
7
8
9
10
11
12
| def func():
print('我是函数本身')
def deco_inner():
print('内层装饰器,函数运行之前')
func()
print('内层装饰器,函数运行之后')
def deco_outer():
print('外层装饰器,函数运行之前')
deco_inner()
print('外层装饰器,函数运行之后')
|
运行效果如下图所示,跟装饰器里面各个wrapper闭包的运行顺序是一致的。
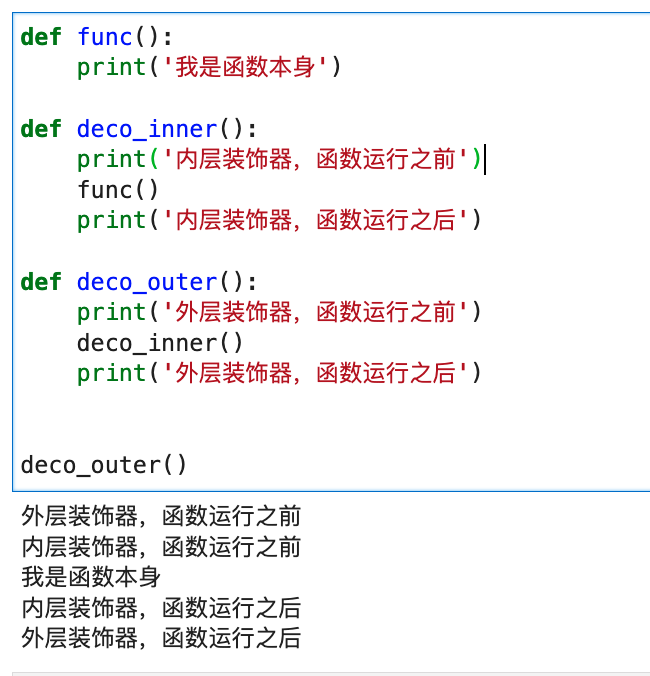
所以,当我们说多个装饰器堆叠的时候,哪个装饰器的代码先运行时,不能一概而论说内层装饰器的代码先运行。这会给人一种错觉,认为是内层装饰器的代码从第一行到最后一行都是先运行的。准确的说法应该是,wrapper外面的代码,确实是内层装饰器先运行,外层装饰器后运行。但是wrapper里面的代码,是外层装饰器先开始运行,后运行完毕,内层装饰器后开始运行,先运行完毕。
这个知识看起来似乎有点像面试八股文,有什么用呢?我给大家举个例子。下面是使用FastAPI写的一个接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
| from fastapi import FastAPI
app = FastAPI()
def do_query_dataset(dataset_id):
print("直接读取数据库,获取dataset信息")
dataset_info = {"xxx": 1, "yyy": 2}
return dataset_info
@app.get('/dataset')
def get_dataset(dataset_id: int):
dataset_info = do_query_dataset(dataset_id)
return {'success': True, "data": dataset_info}
|
用户访问这个接口,URL中传入参数dataset_id,就可以获得数据集的信息。如下图所示:

现在,要增加权限校验,首先要判断用户是否登录。在用户已经登录的情况下,看这个用户是否有这个数据集的权限。在有这个数据集的权限时,才能返回数据集信息。
你肯定想到了使用装饰器来做这两步,一开始你写的代码可能是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def check_login(func):
def wrapper(*args, **kwargs):
print('检测是否有特定的Cookies')
is_login = False
if not is_login:
return {'success': False, "msg": "没有登录"}
return func(*args, **kwargs)
return wrapper
def check_data_set_permission(func):
def wrapper(*args, **kwargs):
print('检测是否有特定的数据集权限')
print('首先从请求参数中获取dataset_id')
print('然后从登录session中获取用户id,注意,如果没有登录,是没有session的')
print('判断用户是否有这个dataset的权限')
has_data_set_permission = True
if not has_data_set_permission:
return {'success': False, "msg": "没有数据集权限"}
return func(*args, **kwargs)
return wrapper
|
这个时候,我们要确保check_login里面检查用户是否登录的代码首先运行。然后才能是check_data_set_permission里面检查数据集权限的代码。
本文开头的半吊子,认为靠近函数名的装饰器先执行,远离函数名的装饰器后执行。按他们理论,就会写成:
1
2
3
4
| @check_data_set_permission
@check_login
def do_query_dataset(dataset_id):
...
|
这样写显然是错误的。因为check_data_set_permission装饰器会有一个前提,就是用户已经登录了,代码才会走到这里。那么他就会直接去session取用户ID。没有登录的用户是没有用户ID的。在取ID的这一步就会出错。
根据本文上面的解释,由于这两个逻辑都是在wrapper内部的。
wrapper内部的代码,外层装饰器先开始运行。因此,这里我们装饰器的正确顺序,只能按照如下顺序排列:
1
2
3
4
| @check_login
@check_data_set_permission
def do_query_dataset(dataset_id):
...
|
这个写法,从直觉上,就会跟本文开头的认知矛盾。但这才是正确的顺序。