Foreword
SES的排除编译文件非常蠢,他不能将这个设置继承给其他配置文件,这就导致如果配置文件很多,每次变动需要把每个配置文件重新设置一次,手动的话很容易设置漏了,所以写个脚本来直接处理这个事情
XML
简单说现在有4个主配置,基于他们每个衍生出来2个配置,也就是一共12个配置,目标是每次只要配置这四个主配置,其他配置就能自动同步他们的排除编译文件的配置。
想了想用批处理或者shell实现,有点麻烦,还是XML,光是分析什么的写起来就很复杂,所以干脆用python写了,CI调用
XML DOM基础
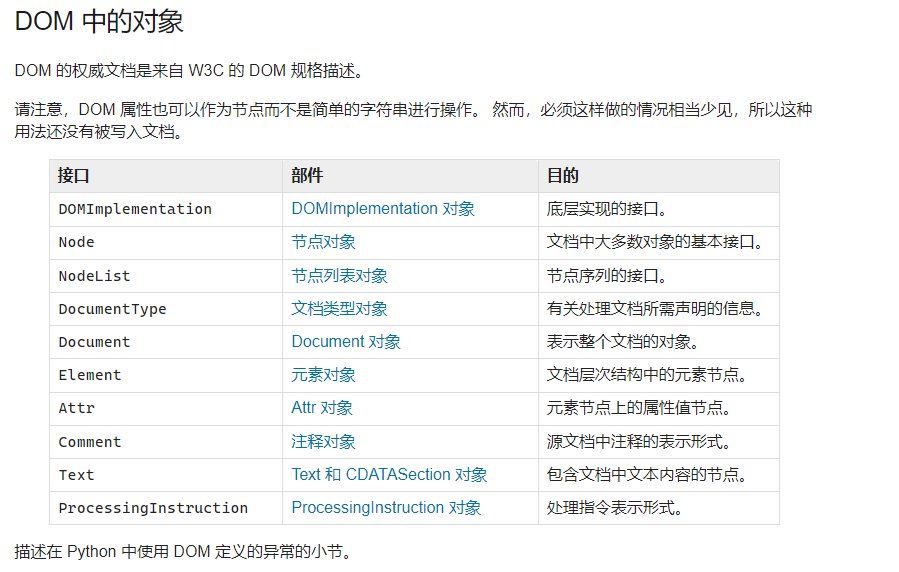
DOM将XML以树状的方式进行构建或者展示,所以每个节点都有子节点或者父节点
<collection shelf="New Arrivals">
<m
ovie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
</collection>
这里collection就是一个元素或者节点,可以称之为Element或者Node
一个元素内部的称为属性,比如这里的shelf,就是属性Attribute
而movie则是collection的子节点,同理type format year rating...
这里要注意一个问题,python api中 getElementsByTagName是可以获得此节点下所有符合的Tag,无论他是子节点还是孙节点,只要符合都会返回。
python操作xml,可以直接使用内置的库,不需要额外引用。这里使用xml.dom.minidom来实现
提取排除编译配置
下面基本就能把所有具有排除编译的配置和文件、文件夹提取出来
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import xml.dom.minidom
# open xml
DOMTree = xml.dom.minidom.parse("demo.emProject")
collection = DOMTree.documentElement
# test attribute
if collection.hasAttribute("Name"):
print("find name")
project = collection.getElementsByTagName("project")[0]
folders = project.getElementsByTagName("folder")
print(len(folders))
root_dir = folders[0]
print("root child:" + str(root_dir.childNodes.length))
exclude_nodes = {}
confs = root_dir.getElementsByTagName('configuration')
if len(confs) > 0:
print(len(confs))
# check all configurations
for conf in confs:
if conf.hasAttribute("build_exclude_from_build"):
# save config and parent node
if conf.parentNode in exclude_nodes:
exclude_nodes[conf.parentNode].append(conf)
else:
exclude_nodes[conf.parentNode] = [conf]
# show exclude file
if conf.hasAttribute("Name"):
name = conf.parentNode.getAttribute("Name")
if name == "":
name = conf.parentNode.getAttribute("file_name")
print(name + " exclude from " + conf.getAttribute("Name"))
深度、广度优先遍历
有可能会需要深度或者广度优先遍历,我也都随便写了个
def dfs(node):
if node.hasChildNodes:
for n in node.childNodes:
# print(n.nodeType)
# jump text node
if (n.nodeType == 1):
if n.getAttribute("Name") != "":
print(n.nodeName + " " + n.getAttribute("Name"))
elif n.getAttribute("file_name") != "":
print(n.nodeName + " " + n.getAttribute("file_name"))
dfs(n)
else:
return
return
def bfs(nodes):
if len(nodes) > 0:
todo = []
for n in nodes:
if (n.nodeType == 1):
# print(n.childNodes)
if n.getAttribute("Name") != "":
print(n.nodeName + " " + n.getAttribute("Name"))
elif n.getAttribute("file_name") != "":
print(n.nodeName + " " + n.getAttribute("file_name"))
if len(n.childNodes) != 0:
for nc in n.childNodes:
todo.append(nc)
bfs(todo)
else:
return
return
dfs(root_dir)
bfs(root_dir.childNodes)
处理替换分支
这里main asdf就是主要分支了,其他的都是顺势而生的分支
need_CI = ["main", "asdf"]
need_Boot = ["main_boot", "asdf_boot"]
ci_branch_map = {
"main": "main_CI",
"asdf": "asdf_boot",
}
boot_branch_map = {
"main": "main_boot",
"asdf": "asdf_boot"
}
doc = DOMTree
# deal all exclude node
for node in exclude_nodes:
type = 1
name = node.getAttribute("Name")
if name == "":
type = 2
name = node.getAttribute("file_name")
branchs = []
last_conf = ""
for conf in exclude_nodes[node]:
branch = conf.getAttribute("Name")
#print(name + " exclude from " + branch)
branchs.append(branch)
last_conf = conf
to_add = []
for branch in branchs:
if branch in need_CI:
ci_branch = ci_branch_map[branch]
if ci_branch not in branchs:
to_add.append(ci_branch)
#print("need add CI " + ci_branch)
if branch in need_Boot:
boot_branch = boot_branch_map[branch]
if boot_branch not in branchs:
to_add.append(boot_branch)
#print("need add boot " + boot_branch)
# get tab
tab = last_conf.previousSibling
for branch in to_add:
n = doc.createElement("configuration")
at_name = doc.createAttribute("Name")
at_name.value = branch
n.setAttributeNode(at_name)
ex = doc.createAttribute("build_exclude_from_build")
ex.value = "Yes"
n.setAttributeNode(ex)
new = node.insertBefore(n, last_conf)
# for /n
newline = doc.createTextNode("")
node.insertBefore(newline, last_conf)
# for indent
new_tab = tab.cloneNode(deep=False)
node.insertBefore(new_tab, last_conf)
f = open("demo1.emProject", "w")
doc.writexml(f)
f.close()
这里可能最后的地方插入节点的地方有点奇怪。
XML作为一种标记性文本,每个换行和每个制表符或者每个空格,在XML中都是作为一个标记的,也就是说他们也是一种节点(Text类型)。前面没理解这个概念,弄了半天发现输出的XML中,新增节点都是连着的,怎么都不会自动换行,而且前面也没有空格。

属性也是,也有这个概念,用来区分换行和不换行

加入Text Node以后就正常了
Summary
还有另外两种方式操作XML,可能比这种更简单一些
Quote
https://docs.python.org/zh-cn/3/library/xml.dom.html#document-objects
https://docs.python.org/zh-cn/3/library/xml.dom.minidom.html