问题
多模态如何做融合,本文是对CLIP模型理解做个记录。
前提
目前业界有中文开源版本的,例如Chinese-CLIP以及IDEA/Fengshenbang-LM太乙系列,本文采用Chinese-CLIP来梳理其流程。
数据集采用wukong-dataset,预训练模型使用chinese-clip-vit-base-patch16来进行实验。
流程
1. 文本处理
1 | import pandas as pd |
基于ChineseClip官方说明,知道其text-encoder部分都使用了chinese-roberta-wwm,另外一个可验证点是其vocab.txt的md5值和chinese-roberta-wwm是一样的。所以文本处理,就是找了中文版的bert来做中文的支持,故这部分到此就结束啦~
2. 图像处理
1 | import pandas as pd |
其流程如下所示,包括转RGB、resize、rescale、normalize、然后转CHW通道。
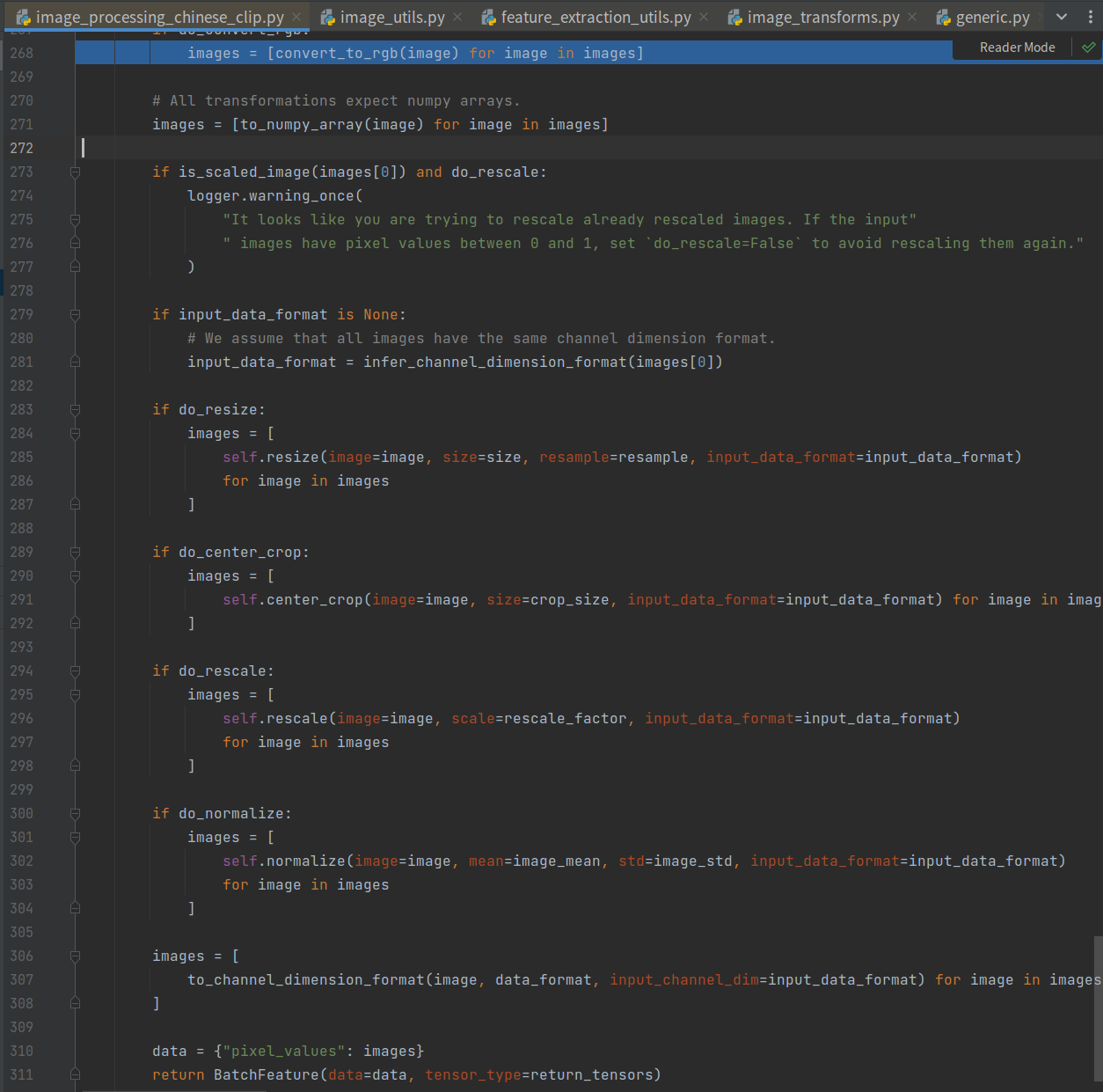
注意resize那里将图片调整为(224, 224),这里对后面处理有用。
3. 融合
重点来喽~
其整理流程如下所示。
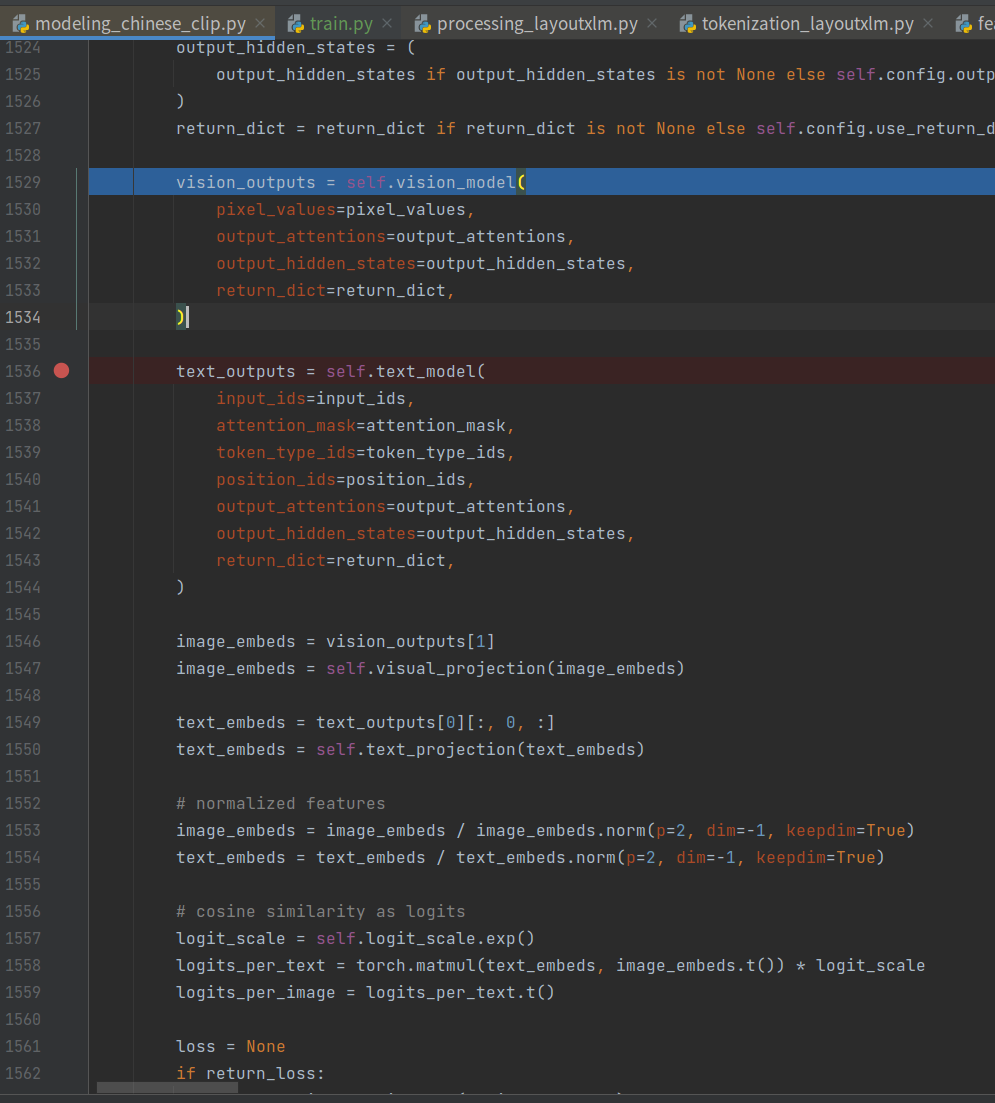
3.1 vision model
其vision_model下获取embedding如下。
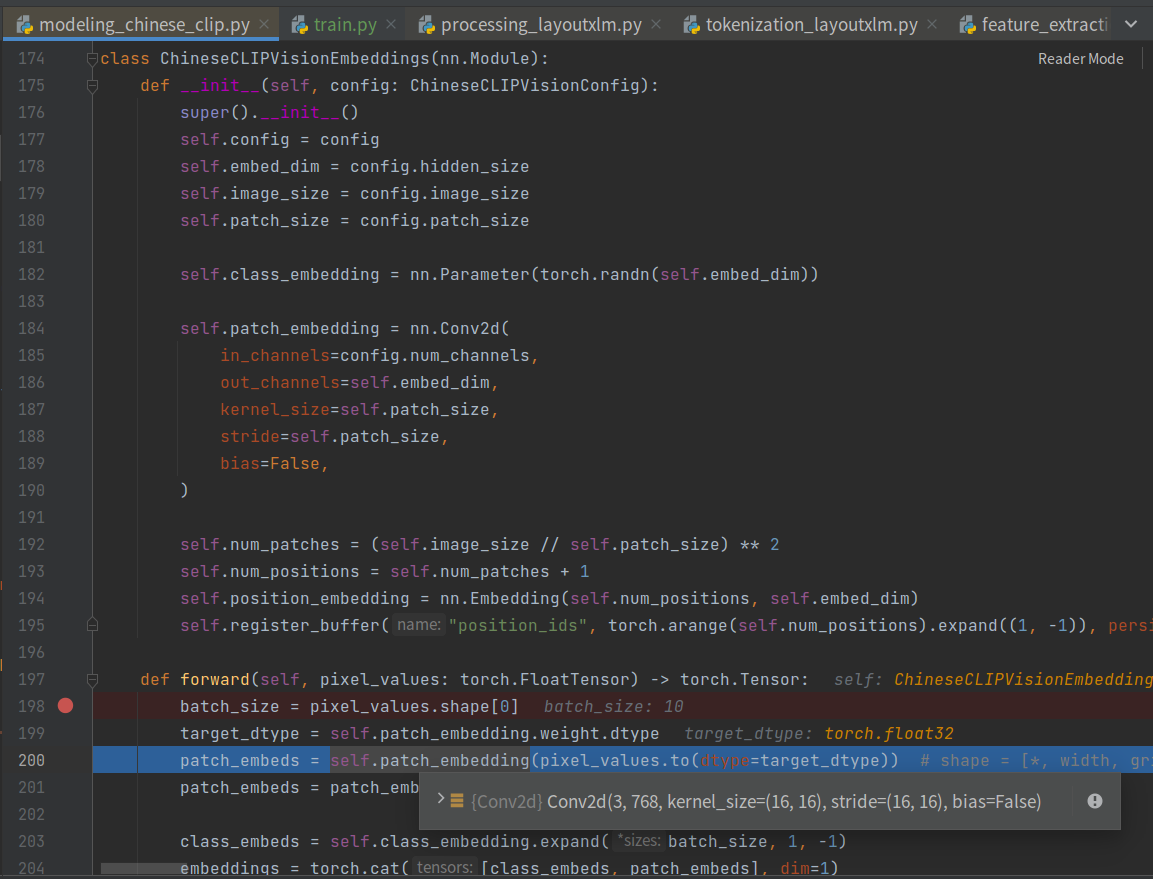
其patch_embeds经过conv2d,转成成了torch.Size([10, 768, 14, 14]),接着
201行代码为:
1 | patch_embeds = patch_embeds.flatten(2).transpose(1, 2) |
14*14=196,最终转换成了(10, 196, 768),到这里就清晰了~
不过在patch_embeds结束后,引入了一个class_embeds,这个就是类似bert中的[CLS]位置,用以做下游分类的。
在拿到vision embedding之后,后面就是encoder部分啦,这里对应ChineseCLIPVisionEncoder,这部分本文先忽略。
3.2 text model
这部分就是bert处理流程了,作者也写的很明白,就是bert那一套。
3.3 融合
至此拿到vision_outputs和text_outputs,其vision_outputs为:
1 | last_hidden_state=(10, 197, 768) |
其text_outputs为:
1 | last_hidden_state=(10, 64, 768) |
好奇:至此768维已经对齐了,为啥还要各自经过一个self.visual_projection和self.text_projection将其转为512维。。。
3.4 计算loss
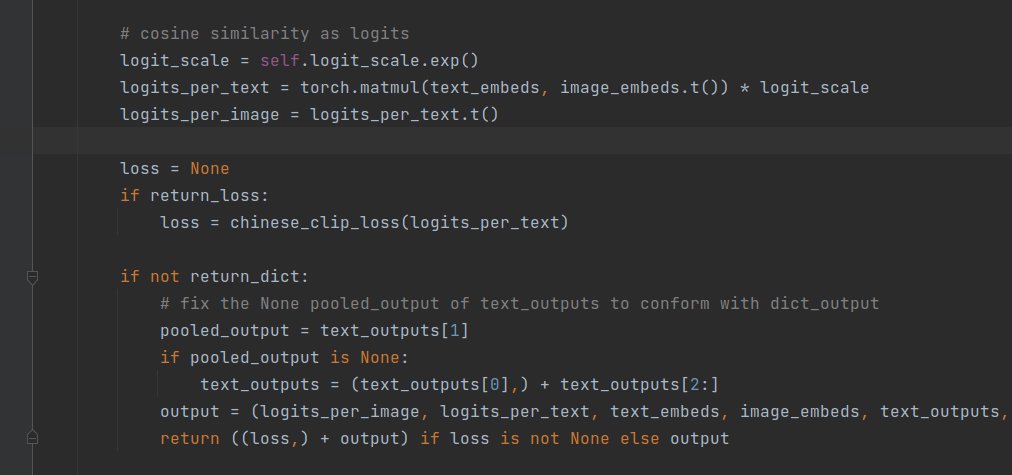
这里处理跟simcse计算loss流程蛮类似的,不过这里计算loss还是蛮有意思的:
1 |
|
正常来讲,我们只需要计算一次即可,这里分别进行计算,也算是一个有意思的点。
至此,模型整体流程大致完成。能够用来基于文本找图像。
那是否有一种文本跟图像语义对齐的呢?留给以后~