介绍
阿里出了个qwen1.8B,对于资源有所要求的场景或者需要支持长文本的场景,应该是目前国内在这个量级内最优的选择了吧。接下来以此来打通微调、部署各个流程,算是一次记录。
微调
首先按照要求和快速使用来跑起来,安装flash-attn,先跑下推理,正常,接下来就进入微调阶段。
按照微调流程,这里采用LoRA进行微调,但是需要注意的是,虽然官方给出了显存占用及训练速度,但是我在1080Ti上得到的显存占用还是要更高一些,大家可以将这个指标理解成为运行起来至少需要的显存,在进行训练时,还是会有一些增高。
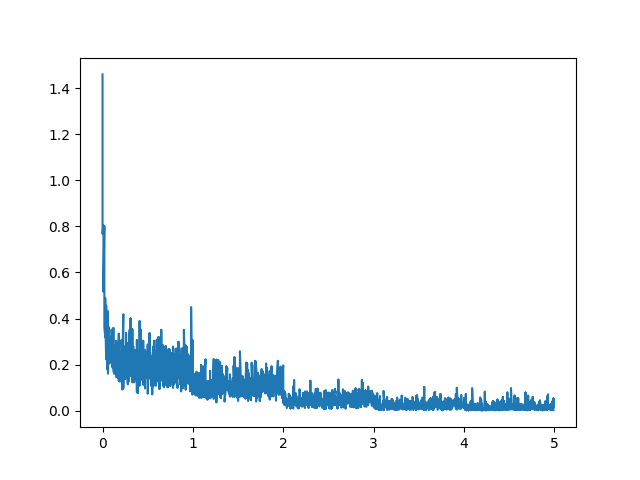
训练的话采用finetune_lora_single_gpu.sh默认配置,幸亏我没有采用train,而是使用了dev数据集,7500条数据,8个多小时,,不过整个loss还是蛮正常的,没有出现issue里出现的各种问题。。。
使用
我这里保存到了outout_qwen,下面为调用LoRA微调后的模型。
1 | path = 'Qwen-1_8B-Chat' |
注意的是,如果到此就打算部署的话,也要将adapter_config.json中的base_model_name_or_path正确引用,不过官方也给了合并代码,可以将LoRA和qwen合并到一起。
1 | from peft import AutoPeftModelForCausalLM |
llama.cpp
如果需要使用llama.cpp,这里还是建议进行上述步骤合并的,使用llama.cpp也不是很复杂,可按照官方README安装cmake编译安装,后续也不是很复杂,官方提供了非常清晰的使用说明。
1 | mkdir build |
不过需要注意的是,用不用量化或者说要不要做转换,本身上还是要根据转换后的效果和效率来决定的,由于目前我们直接跑在GPU上,后续有机会单独针对llama.cpp尝试深入一下~