有时候,我们需要使用多行字符串配合format格式化函数来生成Markdown文本。例如,我现在开发了一个AI对话机器人,我发送一个txt文件过去,他首先帮我总结整个文件的内容,然后以问答的形式列出10个要点。
你的代码可能是这样写的:
1 | def bot(text): |
返回Markdown以后,通过前端渲染出正常的文本。
但如果你直接这样写,你会发现Markdown的渲染好像出问题了。如下图所示:
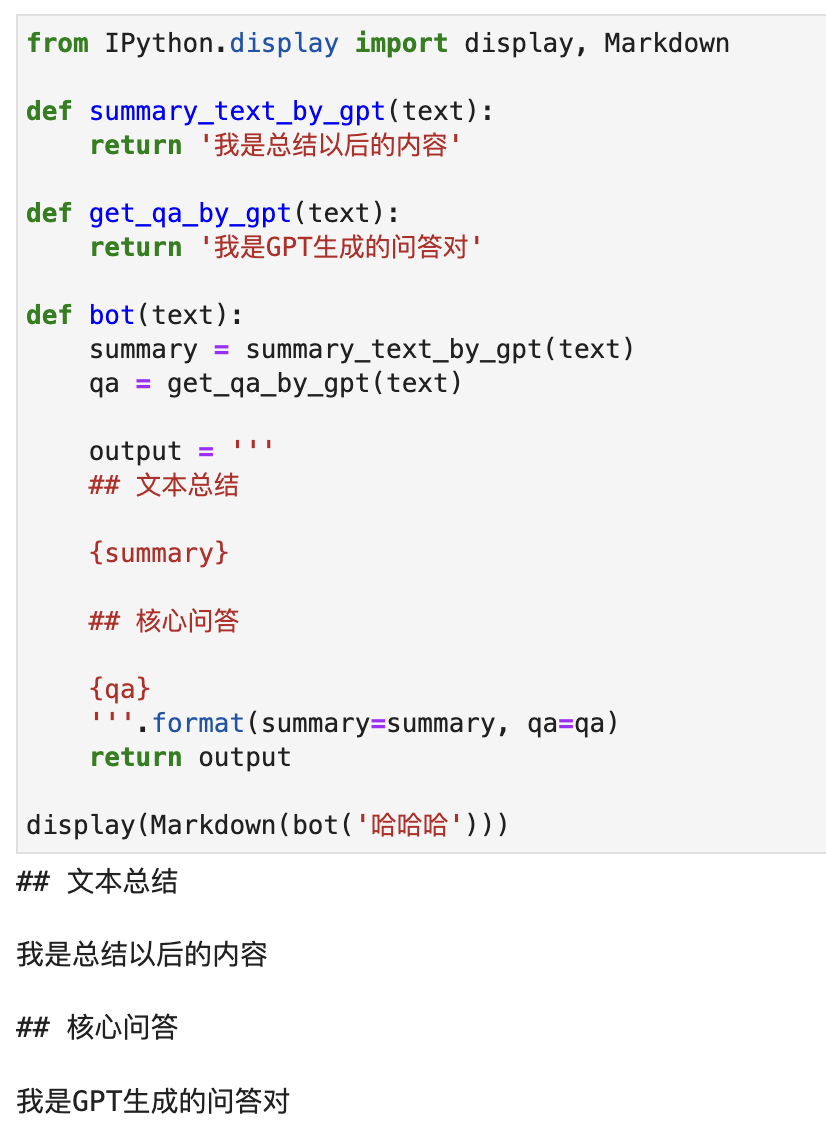
为什么会出现这个问题呢?其实很简单,因为你的Markdown文本有问题。我们来看一下正常的Markdown长什么样:

你上下对比看看,会不会觉得非常疑惑,这明明就是一样的,为什么下面可以上面不行?实际上,他们关键的差异,就在于你看不到的空格:
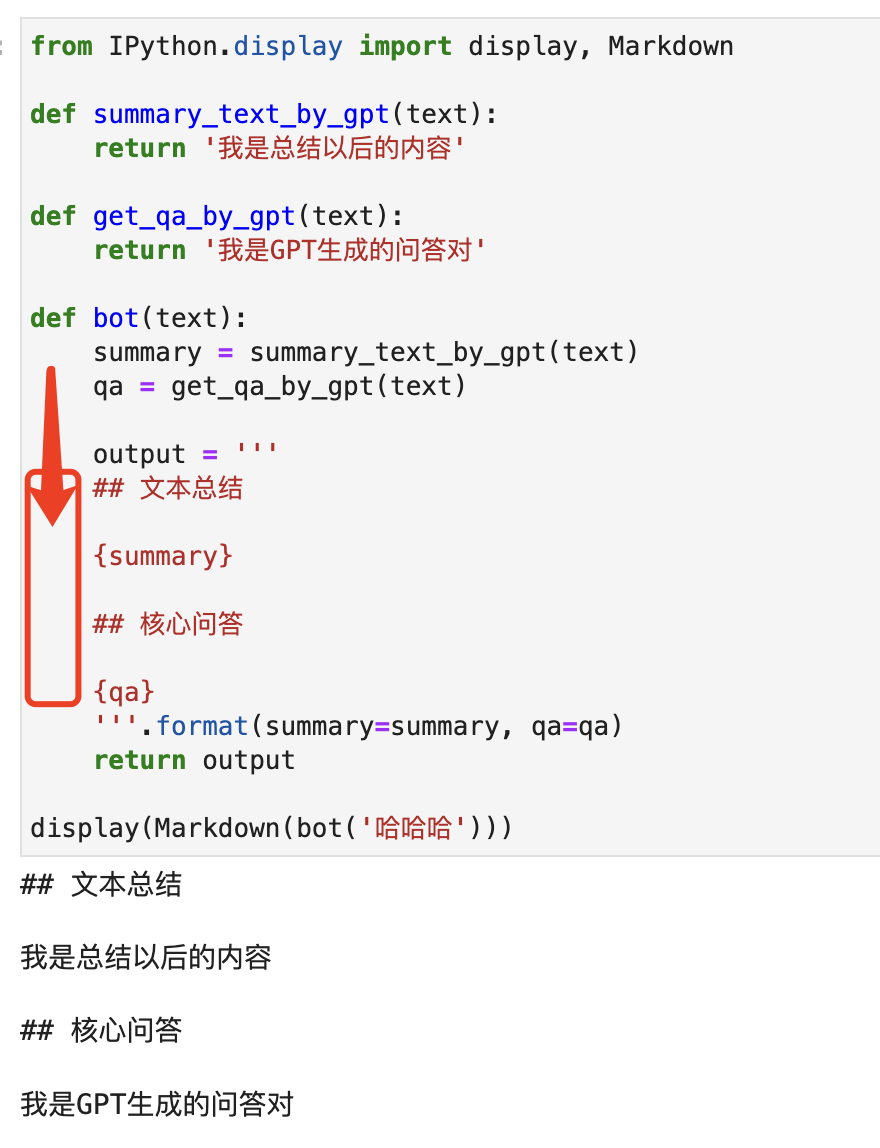
在Python里面,三引号表示多行字符串。在一对三引号之间的所有字符都是这个多行字符串的一部分。包括你在Python里面习以为常的缩进。
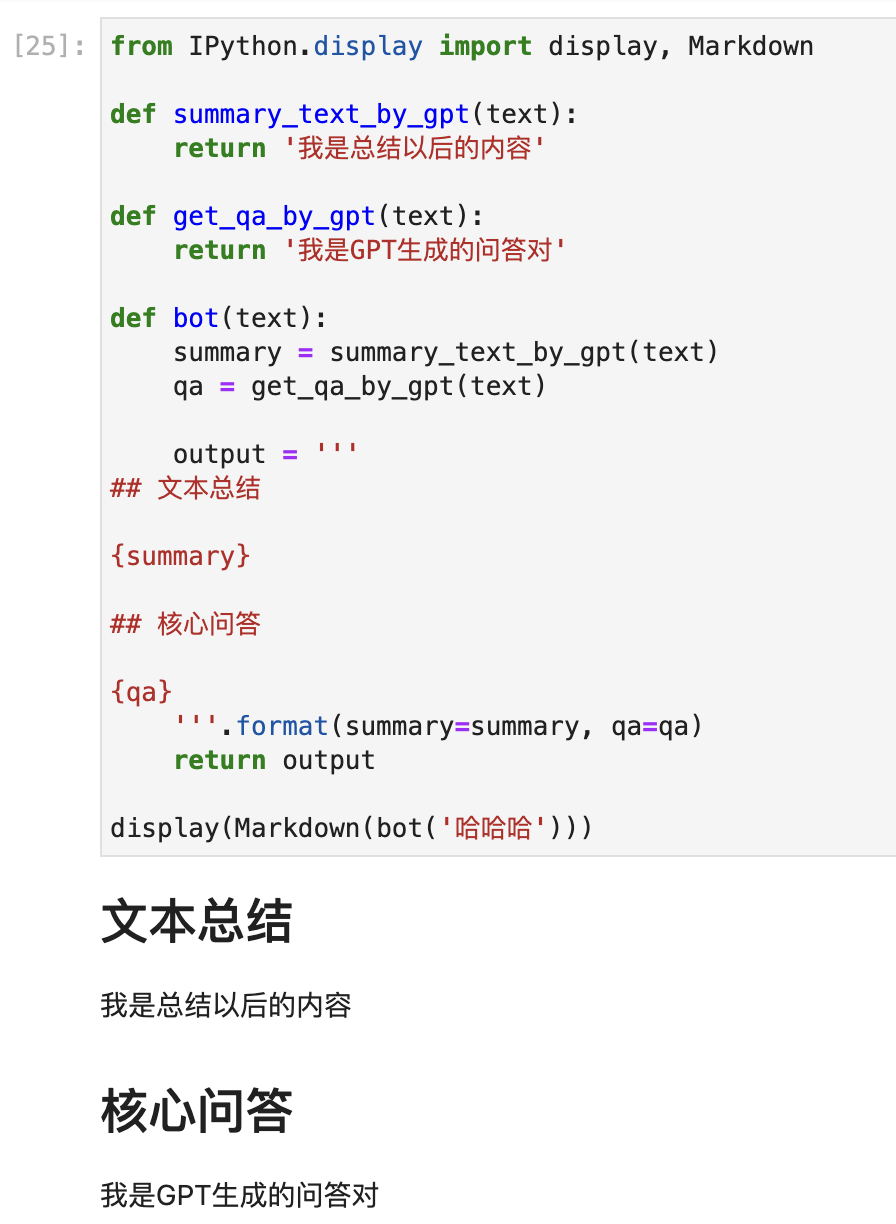
我们使用repr命令来看看这个有缩进的output实际上长什么样:

注意到了吗,在函数里面定义多行字符串时,很容易把缩进带进来,导致##前面有空格,于是这就变成了不合法的Markdown。
要解决这个问题其实也非常简单,在多行字符串定义的时候,不要缩进:
但这样你有没有觉得代码变得非常丑?参差不齐。如果你定义多行字符串时还是在更深的缩进里面,代码会更难看,如下图所示:
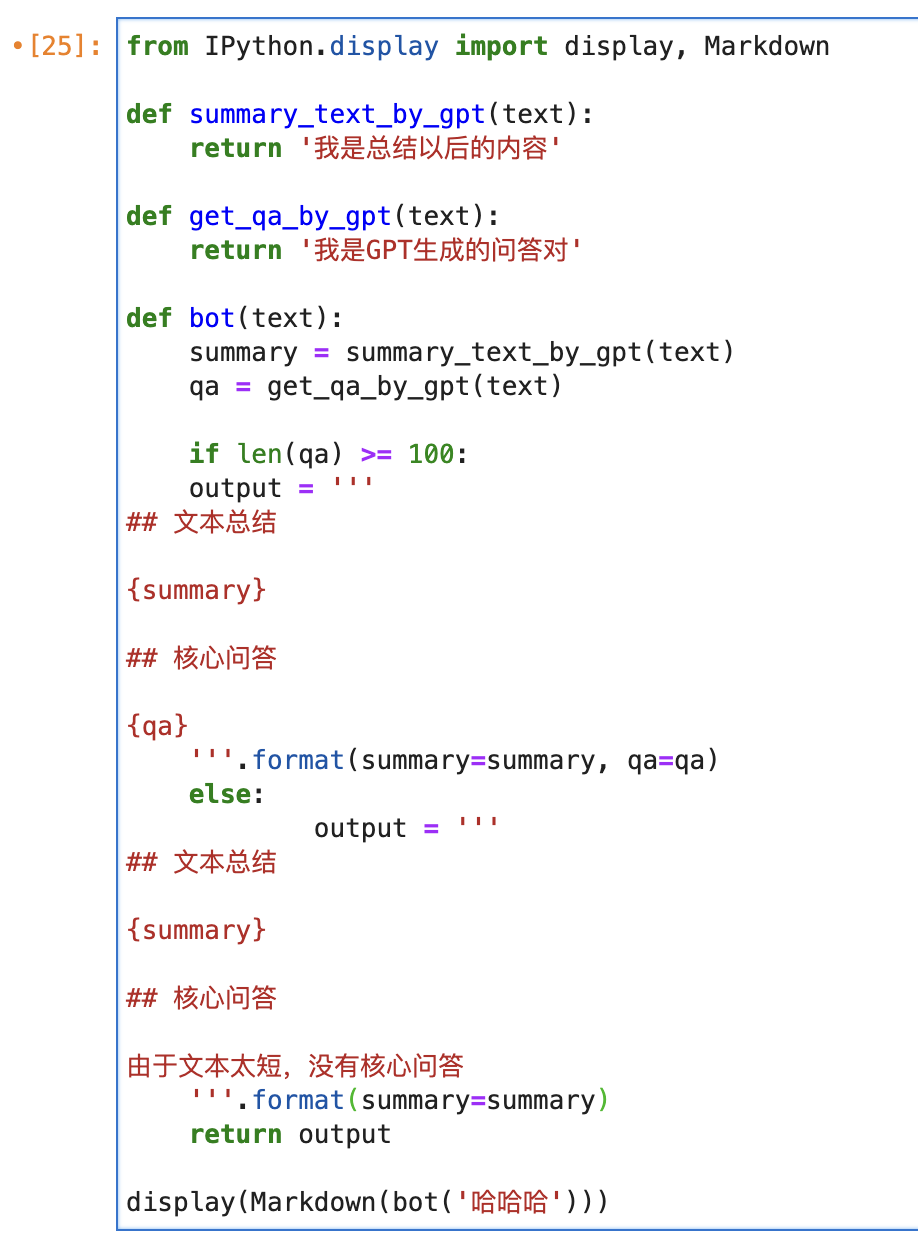
这可太丑了,要是被那些不喜欢Python缩进的人看到,又要被调侃了。
其实要解决这个问题非常简单,使用Python自带的textwrap模块中的dedent就可以了。它可以自动移除多行字符串每一行的前导空格。如下图所示:
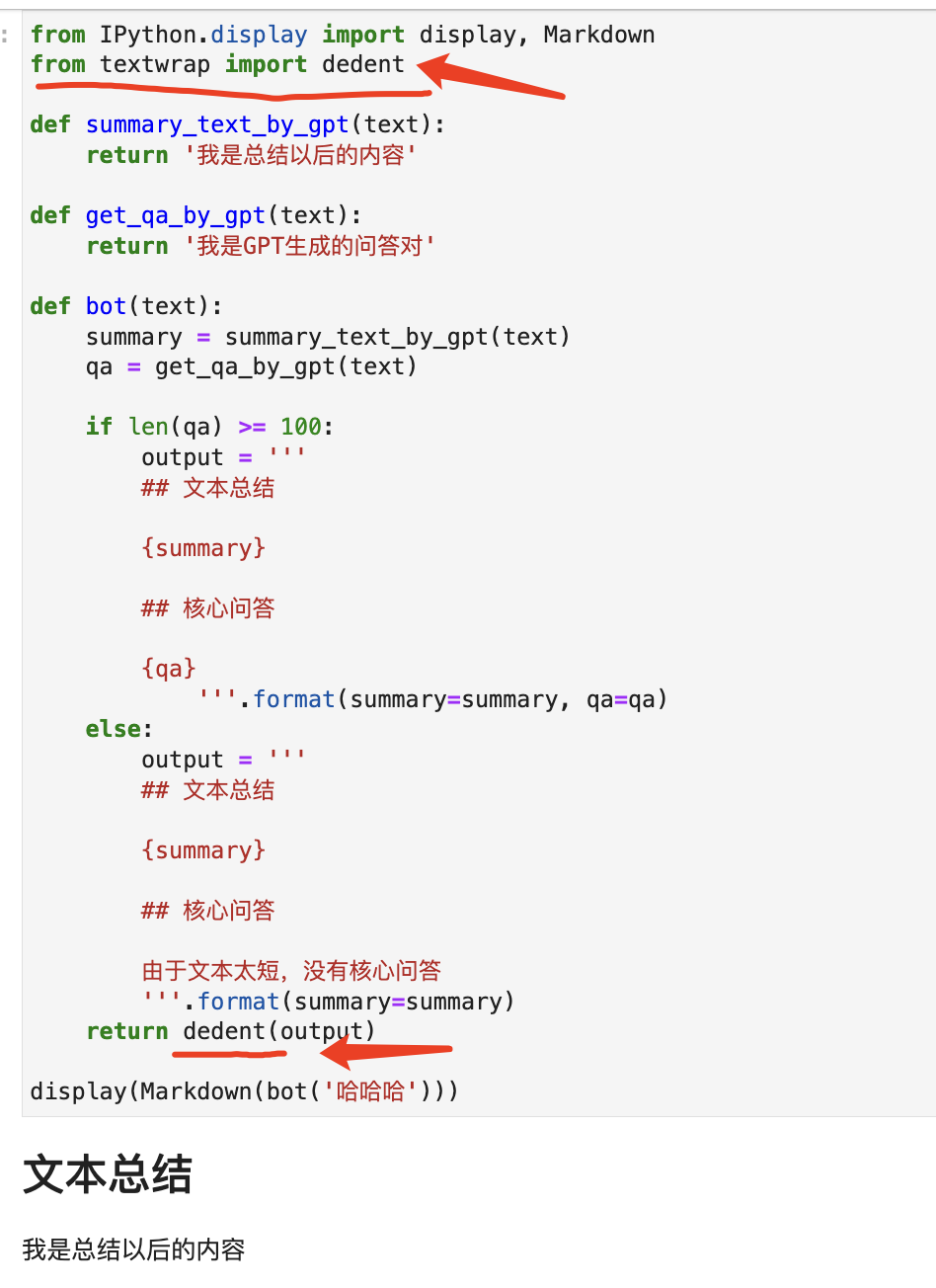
这样一来,既兼顾了多行字符串的美观,又不会因为缩进导致Markdown渲染失败。