前言
过年期间,deepseek-R1火出了圈,各家媒体都在狂轰乱炸宣传deepseek,以及技术圈各种文章来介绍其实现原理。那这里仅从“高质量数据”角度作为入口来阐述对其的理解。
为什么需要高质量数据集?
这不废话吗,没有高质量数据集怎么训练高质量模型。对的,这个回答完全没有问题,从目前大模型能力角度来讲,其回答已经持平或者某些方面已经高于绝大多数人的认知,这是其一。其二是在垂直领域或者具体业务,更多、更贴和的真实数据会给模型带来更好的效果以及降低一个量级的参数量,这也是下游能够应用大模型的主要原因。
那其三呢,我们无法构建一个真实环境,来给大模型进行交互,让其不断试错和学习,所以我们需要将人类对于各种问题的理解以及自然规律等等,用其简单明了直接的方式告诉大模型,这个就是答案,所以出现了SFT。其他文章在介绍到SFT时,喜欢用与人类能够交互的方式来解释这里,我觉得这里的原因是同等重要的,如果模型能够进化到具身智能,那么人类知识作为其主要部分,仍是绕不开与人类交互的。
什么是高质量数据集?
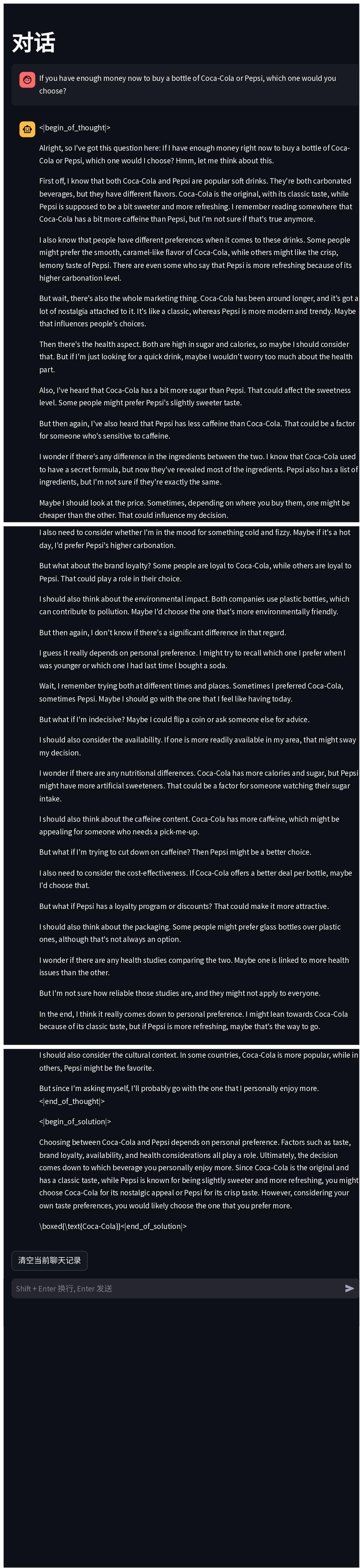
那自然伸展到这里了,或者说高质量数据集应该包含哪些可能,以及什么样的高质量数据集可以更大可能的激发出大模型的能力(aha moment或者是能力涌现)。aha moment是指经过先思考再回答,think step by step,对于推理问题,例如数学、代码方面表现出了优秀的结果。能力涌现是在pretrained model到sft model,指少量标注的QA可以激发出Pretrained model按照人类交互的方式回答用户问题。至此总结了两种高质量数据集的可能表达形式。这也是OpenAI O1、deepseek目前所带来的新的能力。那多模态大模型和agent交互所带来的,我认为也会是接下来的发展方向。
下面展示一个对话demo,经过这种reason dataset来让经过sft model训练后所带来的思考能力。
 |
 |
|---|