【读书笔记】数据结构与算法分析 - C 语言描述 - 第一部分 - 基础知识
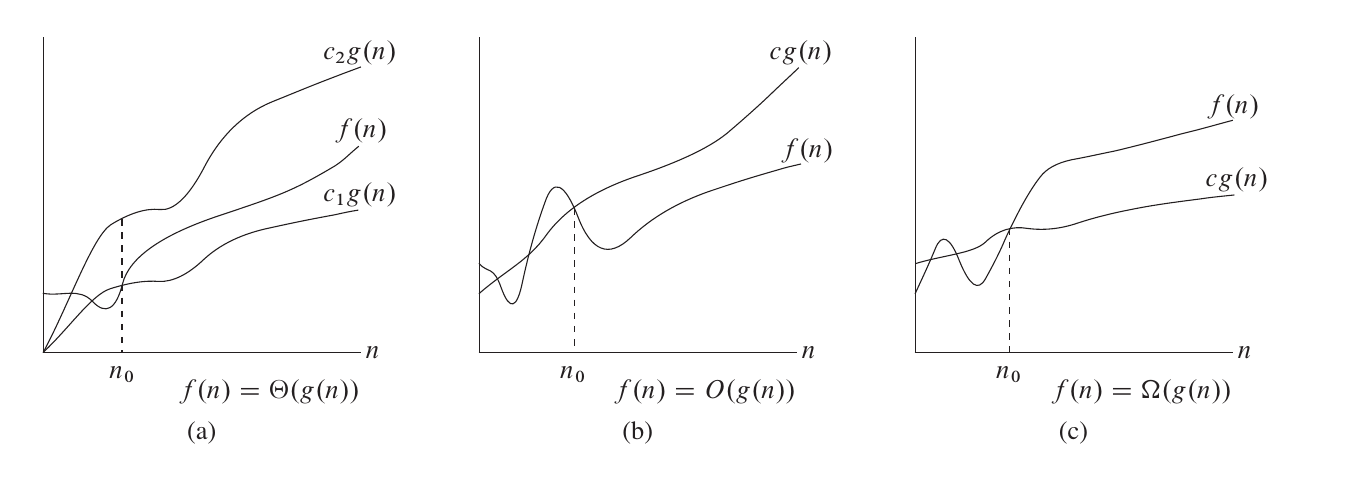
第一章 引言连通性问题:两个操作:查找(find)、并集(union)快速-查找(quick-find):N 个对象,M 次合并:MN快速-合并(quick-union):N 个对象,M 对:MN/2加权快速-合并(weighted quick-union):遍历 2lgN 个指针:线性带等分路径压缩的加权快速-合并:保证线性在线算法(online):能处理的数据没有限制第二章 算法分析的原理算法分析的种类:最坏情况(Worst Case):任意输入规模的最大运行时间(Usually)在任何输入下运行时间的一个上界平均情况(Average Case):任意输入规模的期待运行时间(Sometimes)最佳情况(Best Case):通常最佳情况不会出现(Bogus)基本思路:忽略掉那些依赖于机器的常量关注运..
更多【读书笔记】Go 程序设计语言
第一章 入门分号注入规则:编译器会将特定符号后的换行符(\n)转换成分号(;){ 必须和 func 在同一行x + y合法:1 2 x + y非法:1 2 x + y所有子序列操作都使用半开区间:包含第一个索引(省略则为0),不包含第二个索引(省略则为len(s)),也可以都省略 s[:]三索引切片:在现有数组或切片下,使用第二个冒号来指示新生成的切片的容量gofmt 会按照字母顺序表(字典顺序)对 import 中导入的包排序初始化:s := "" 显式初始化说明初始值的重要性var s string 隐式初始化说明初始值不重要map 包含一个引用,当传参时按值传递(副本),但因为是引用类型所以可以在函数体内修改并外部可见结构体类型转换忽略标签:结构体类型转换时,标签会被忽略。也就是说,标签不同的结构体..
更多【读书笔记】刻意练习 - 如何从新手到大师
前言长时工作记忆正是区分卓越者与一般人的一个重要能力,它才是刻意练习的指向与本质。刻意练习的任务难度要适中,能收到反馈,有足够的次数重复练习,学习者能够纠正自己的错误。长时工作记忆的培养要点:赋予意义,精细编码:(准)专家们能非常快地明白自己领域的单词与术语,在存储信息的时候,可以有意识地采取元认知的各项加工策略;提取结构或模式:往往需要将专业领域的知识,提取结构或模式以更好地方式存储;加快速度,增加连接:通过大量重复的刻意练习,专家在编码和提取过程方面比新手都快很多,增加了长时记忆与工作记忆之间的各种通路。认知复杂性高与认知复杂性低的学习活动的差异在很大程度上表现为隐性知识的多少与比重。认知复杂度高的人具有高度复杂化的思维能力,更善于同时使用互补与互不相容的概念来理解客观世界。人的学习受到情境的制约和促..
更多【读书笔记】国富论
前言作者着眼于他所观察到的尚未出现工业革命的世界经济,首次系统分析了国民财富产生、分配与持续运转的内在规律。他认为人类利己的动机就像一只看不见的手,在暗中推动一切经济行为,同时强调政府应尽可能少地干预,并给予贸易自由的发展。近代以来,一个国家真正的崛起,更多取决于它是否在经济上崛起,纯粹靠军事征服和领土扩张而实现的崛起,很难长久维系。以劳动价值论为基础,以增加国民财富为主线,以资本主义社会3个阶级的3种收入理论为核心,总结出国民财富增长的两种途径:分工与劳动生产率的提高;增加劳动者人数和资本积累。重要观点:分工的重要性劳动价值理论自由贸易的主张“看不见的手”规范政府的职责第一篇 论劳动生产力增进的原因,以及劳动生产物自然分配给各阶级人民的顺序第1章 论分工凡是能够分工的工作,一旦使用分工制,就能够相应地增..
更多【读书笔记】数据结构(C语言版)(第三版)人民邮电出版社
第一章 概论数据:逻辑结构:数据与数据之间所存在的逻辑关系存储结构:数据在计算机中的存储结构,体现逻辑结构运算集合:由为数据定义的所有运算构成,定义在逻辑结构上,实现依赖于存储结构结点:开始结点:无前驱结点内部结点:不是开始结点,也不是终端结点终端结点:无后继结点线性结构:只有一个开始和终端,其余每个结点有且仅有一个前驱和后继非线性结构:树型结构:一个开始,多个终端,除开始外都有且只有一个前驱图形结构:多个前驱,多个后继存储结构:顺序存储:物理位置相邻链式存储:每个结点有若干个指针索引存储:根据结点索引号确定存储地址散列存储:结点 k_i 的存储地址有函数 h(k_i) 确定数据的抽象发展阶段:无类型的二进制数:基本数据类型基本:用户自定义类型自定义:抽象数据类型数据类型:数据属性在这些数据上可施加的运算..
更多【读书笔记】人性的弱点
01:如欲采蜜,勿蹴蜂房批评不但不会改变事实,反而会招致愤恨。因批评而引起的羞忿,常常使雇员、亲人和朋友的情绪大为低落,并且对应该矫正的现实状况,一点好处也没有。尽量去了解别人,而不要用责骂的方式;尽量设身处地去想——他们为什么要这样做。这比起批评责怪要有益、有趣得多,而且让人心生同情、忍耐和仁慈。02:真诚地赞赏他人天底下只有一种方法可以促使他人去做任何事——给他想要的东西。在你每天的生活之旅中,别忘了为人间留下一点赞美的温馨,这一点小火花会燃起友谊的火焰。爱默生说:“我遇见的每一个人,或多或少是我的老师,因为我从他们身上学到了东西。”03:激发他人的强烈需求天底下只有一种方法可以影响他人,就是提出他们的需要,并且让他们知道怎样去获得。成功的人际关系在于你捕捉对方观点的能力;还有,看一件事须兼顾你和对方..
更多【读书笔记】软技能 - 代码之外的生存指南
第1章 为何这本书与你先前读过的任何书籍都迥然不同在我们成长过程中,我们被迫接受的大多数教育体系是支离破碎的,因为它们都依赖于一个错误的前提:你必须要有老师去教,学习只在一个方向上流动。第一篇:职业你所能犯的最大错误就是相信自己是在为别人工作。这样一来你对工作的安全感已然尽失。职业发展的驱动力一定是来自个体本身。记住:工作是属于公司的,而职业生涯却是属于你自己的。第2章 从非同凡响开始:绝不要做他人都在做的事只有你开始把自己当作一个企业去思考时,你才能开始做出良好的商业决策。职业生涯中必须要做的第一要务:转变你的心态,从被一纸“卖身契”束缚住的仆人转变为一名拥有自己生意的商人。在起步阶段就具备这种心态会改变你对职业生涯的思维方式,将此铭记在心,并积极主动地管理自己的职业生涯。你所能提供的服务就是创建软件。..
更多【读书笔记】自控力
前言提高自控力的最有效途径在于,弄清自己如何失控、为何失控。第一章 我要做,我不要,我想要:什么是意志力?为什么意志力至关重要?现代人大脑里前额皮质的主要作用是让人选择做“更难的事”。我要做:帮你处理枯燥、困难或充满压力的工作;我不要:克制一时冲动;我想要:记录你的目标和欲望。当下的自己和想要自控的自己,总有一方会击败另一方,只是双方觉得重要的东西不同而已。学会利用原始本能,而不是反抗这些本能。原始本能先发生作用,然后是前额皮质。注意力分散的人更容易向诱惑屈服。做决定时,应该排除干扰。冥想可以提升自控力、提升注意力、管理压力、克制冲动和提升认识自我的能力。5 分钟冥想:原地不动,安静坐好;注意你的呼吸;感受呼吸,弄清自己是怎么走神的。冥想时感觉“很糟糕”,才能让训练有效果。冥想不是让你什么都不想,而是让你..
更多【读书笔记】程序员健康指南
第一章 做出改变爬完一层楼梯,你是否会喘不过气?你是否经常一坐就是一个多小时?在最近一年内,你是否曾经因为背痛、颈痛、肩痛或手腕痛而使工作受到影响?在最近一周内,你的眼睛是否有过干涩、充血、发炎的症状,或是看完电脑屏幕之后难以看清别的东西?在最近一个月内,你是否至少有一次因吃得太饱而感到难受?今天你暴露在阳光下的时间是否不超过10分钟?在最近5年内,你的蛀牙是否增加了?弯下腰系鞋带时,你是否感到不适?过去5年内,你的腰围是否明显增大了?对于这些问题,哪怕只有一个答案是肯定的,那么你的健康状况就可能处在危险边缘—即使你认为自己的身体状况保持得还不错。体育锻炼不但能促进蛋白质的生成,从而巩固脑组织的神经化学物质平衡,还能提高大脑的氧气和葡萄糖水平,进而提高我们的认知能力。改变习惯的关键在于,在维持原先的暗示信..
更多【读书笔记】贫穷的本质 - 我们为什么摆脱不了贫穷
第一章 再好好想想专注于实务,而不是空谈。第二章 饥饿人口已达到 10 亿?如果人们更富有,他们就可以购买更多食物。一旦人体的新陈代谢需求得到了满足,所有额外的食物就可以用来增强力量,人的生产效率就会提高,从而生产出更多东西,满足维持生命以外的其他需求。如果主食的消费与贫穷的状态有关(比如说,因为主食价格便宜,但不那么好吃),那么富有的感觉可能会促使他们买更少的主食。穷人在选择食品时,主要考虑的并不是价格是否便宜,也不是有无营养价值,而是食品的口味怎么样。穷人常常拒绝我们为其想出的完美计划,因为他们不相信这些计划会有什么效果。在穷人的生活中,还有比食物更重要的东西。葬礼的花费是导致贫穷的主要原因。穷人的首要选择显然是,让自己的生活少一点儿乏味。穷人会更加怀疑那些想象中的机遇,怀疑其生活产生任何根本改变的可..
更多