这个主题想写已经很久了
自从换了新部门之后 也没有写过前端 因为部门总共6个人 有两个前端 然后后端和算法人员不足 因为我技术比较强 就被安排到了新的任务 老大和我说 做数据和算法比前端有前途 话是这么说的 但是我从大一起开始写前端写了这么多年 突然让我去写其他的 那我前端领域的优势就没了啊 而且就算我继续算法这些写个三年四年 到时候仍然随便一个刚刚毕业的专门研究算法的就能把我干趴下了好吗 毕竟我也没怎么专门研究过这些东西 不过既然部门有任务安排 那只能写了 这段时间经历了 python从入门到精通 hbase从入门到精通 hadoop从入门到精通 什么kafka 什么zookeeper 让我作为一个前端大开眼界 有点偏主题了。。。。
我的主要工作有三点本文只是涉及其中一点 就是基于协同过滤的推荐算法 我们部门是推荐技术部 各种推荐算法当然是我们部门的核心技术 协同过滤这一块没那么核心 但是也非常重要
这个相关的文章 网上也是一抓一大把 主要的原理是通过用户对物品的行为来计算物品与物品之间以及用户与用户之间的相似度 算法的核心数学公式有好几种 我就不重复写了 我负责的这一块是从其他项目中借鉴过来的 发现对应的数学公式和现有的一些公式并不一样 我也不便透露了 不过各种公式的功能是一样的 都是为了计算相似度 不同公式对不同对场景会有优劣而已
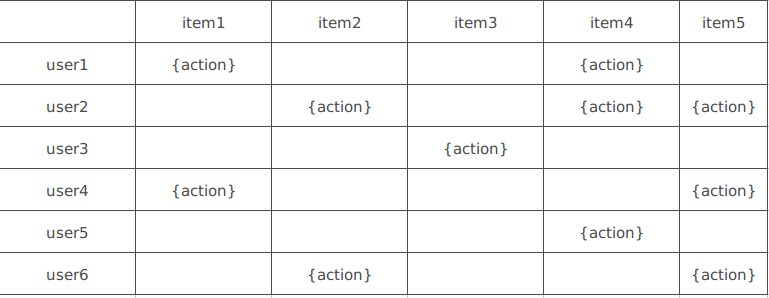
上图就是一个假设的用户对物品的操作的表 表示用户对各个物品的是否有过操作 在计算相似度的时候 不同的操作有不同的权值 或者直接可以使用用户的打分作为权值
协同过滤分为两种 以下假设所有的行为权值都一样
一种是基于用户的 计算用户之间的相似度 比如上图中 对item2有操作的用户为: [user2, user6] 对item5有操作的用户为: [user2, user4, user6] user2和user6操作过多个相同的物品 可以认为user2和user6相似度比较高 因此可以将这两个用户操作的物品相互推荐 例如吧user2操作过的item4推荐给user6
另外一种是基于物品 计算物品之间的相似度 比如user2操作过[item2, item4, item5] user6操作过[item2, item5] item2和item5被多个相同的人都操作过 所有可以认为item2和item5比较相似 可以把其中一个物品推荐给操作过另外一个物品的人 比如 就可以把item2推荐给操作过item5的user4
很明显可以看出来 上面两种是完全对称的 常常情况下 物品或者用户数量一方远大于另外一方 这时候就得考虑选择其中一种就可以了
当然上面的举的例子并不严谨 数量太少
协同过滤是一种典型的基于群体行为的方法 需要建立在大量的行为之上才能计算准确 而且数量越大越准确 基于内容相似的推荐 在不能起到作用时 协同过滤往往能起到奇效
具体的demo我以后再补吧