在上一篇文章中我们已经搭建好了HDFS环境,现在我们在这个环境的基础上继续搭建YARN和MapReduce环境。
修改三台机器的etc/hadoop/mapred-site.xml文件,添加如下配置
1 | <configuration> |
修改三台机器的etc/hadoop/yarn-site.xml文件,添加如下配置
1 | <configuration> |
随后我们在172.19.65.196节点上执行命令启动yarn
./hadoop-3.3.2/sbin/start-yarn.sh之后在节点上分别执行jps命令可以看到ResourceManager和NodeManager都已经起起来了
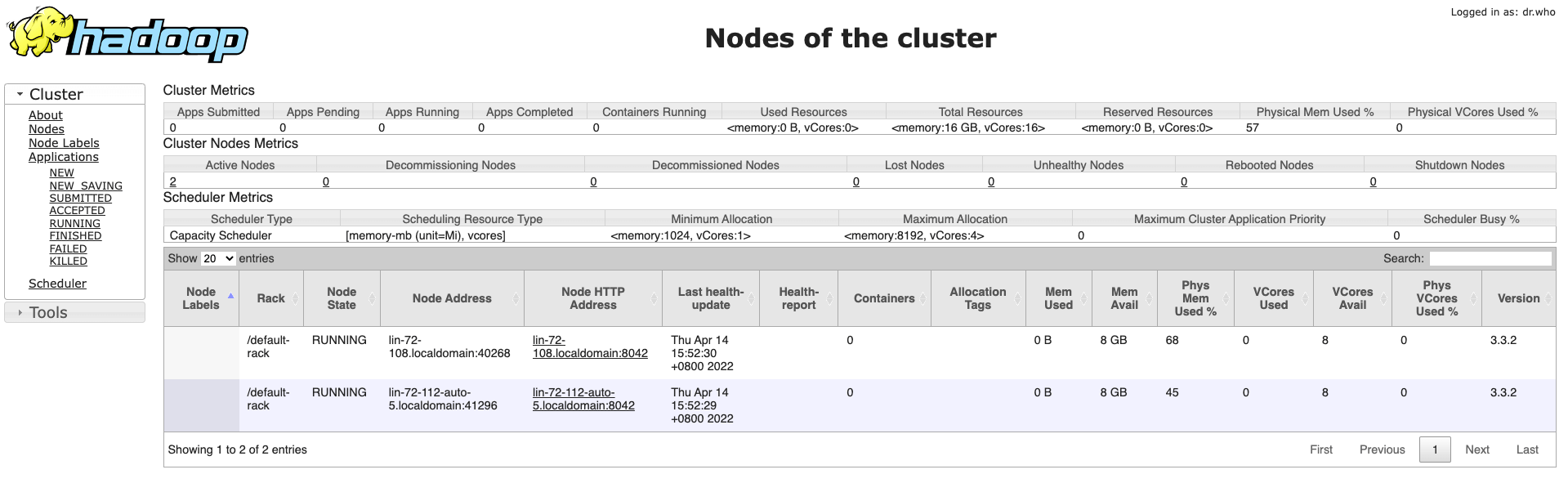
[hadoop@lin-65-196 ~]$ jps30690 SecondaryNameNode10466 ResourceManager10779 Jps30462 NameNode[hadoop@lin-72-108 ~]$ jps19909 DataNode23208 Jps23069 NodeManager之后我们访问网页http://172.19.65.196:8088/cluster/nodes就可以看到节点信息了
之后提交一个我们之前在单机上测试过的任务
# 在hdfs上创建input文件夹./bin/hadoop fs -mkdir /input# 传输文件到hdfs./bin/hadoop fs -put etc/hadoop/*.xml /input# 删除我们之前在hdfs上创建的test文件夹./bin/hadoop fs -rm -f -r /test# 提交任务./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar grep /input /output 'dfs[a-z.]+'参考
Hadoop之YARN的安装与测试
yarn-default.xml
注:为了使用方便,可以在本机使用SwitchHosts进行IP和Hostname的映射
172.19.65.196 lin-65-196.localdomain172.19.72.108 lin-72-108.localdomain172.19.72.112 lin-72-112-auto-5.localdomain