本文来自于一个手工记账博主的脑洞大开,尝试通过向量数据库和 RAG 来想办法让自己少打几个字。顺便宣传一下最近开源的记账 bot.
背景
自从 2020 年将记账系统迁移到 Beancount 后,我就开发了一个 Telegram Bot 来辅助我记账。通过它,我可以使用 {金额} {流出账户} [{流入账户}] {payee} {narration} [{tag1} {tag2}] 的文法来快速生成一条交易记录并落库。虽然后来将这个 Bot 迁移到了 Mattermost 上,但四年以来,核心逻辑并没有做任何改动。
最近经常骑车去打球,每次骑完车之后总需要掏出手机去记账,输入诸如 1.5 支付宝 哈啰单车 自行车 的文本。虽然已经手动记账记了七年,但完全相同的内容记得次数太多了,也难免会有些枯燥。
前一阵子刚好在 GitHub 上刷到了基于 sqlite 的向量数据库方案 sqlite-vec,正好趁这个机会来对 RAG 做一个初步体验,探索一下是否存在系统性的手段,可以进一步降低单笔记账所需的字符数。
基础知识
RAG(Retrieval-Augmented Generation, 增强检索生成)这个概念在 2020 年最初提出,旨在提升大语言模型本身在回答问题时的准确性问题。在 2023 年 LLM 进入爆炸式发展后,人们也在不断地对 RAG 进行改进。
简单来说,RAG 的过程就是预先通过 embedding 技术构建一个离线的向量数据库;在用户提问时,从向量数据库检索到最相关的部分信息,然后将其作为参考信息和用户的问题一起喂给 LLM,这样 LLM 的回答就更有可能依据给出的参考信息来进行生成,出现幻觉的可能性更低。
从网上找到了一个比较简洁的 RAG 流程图(图片来源):
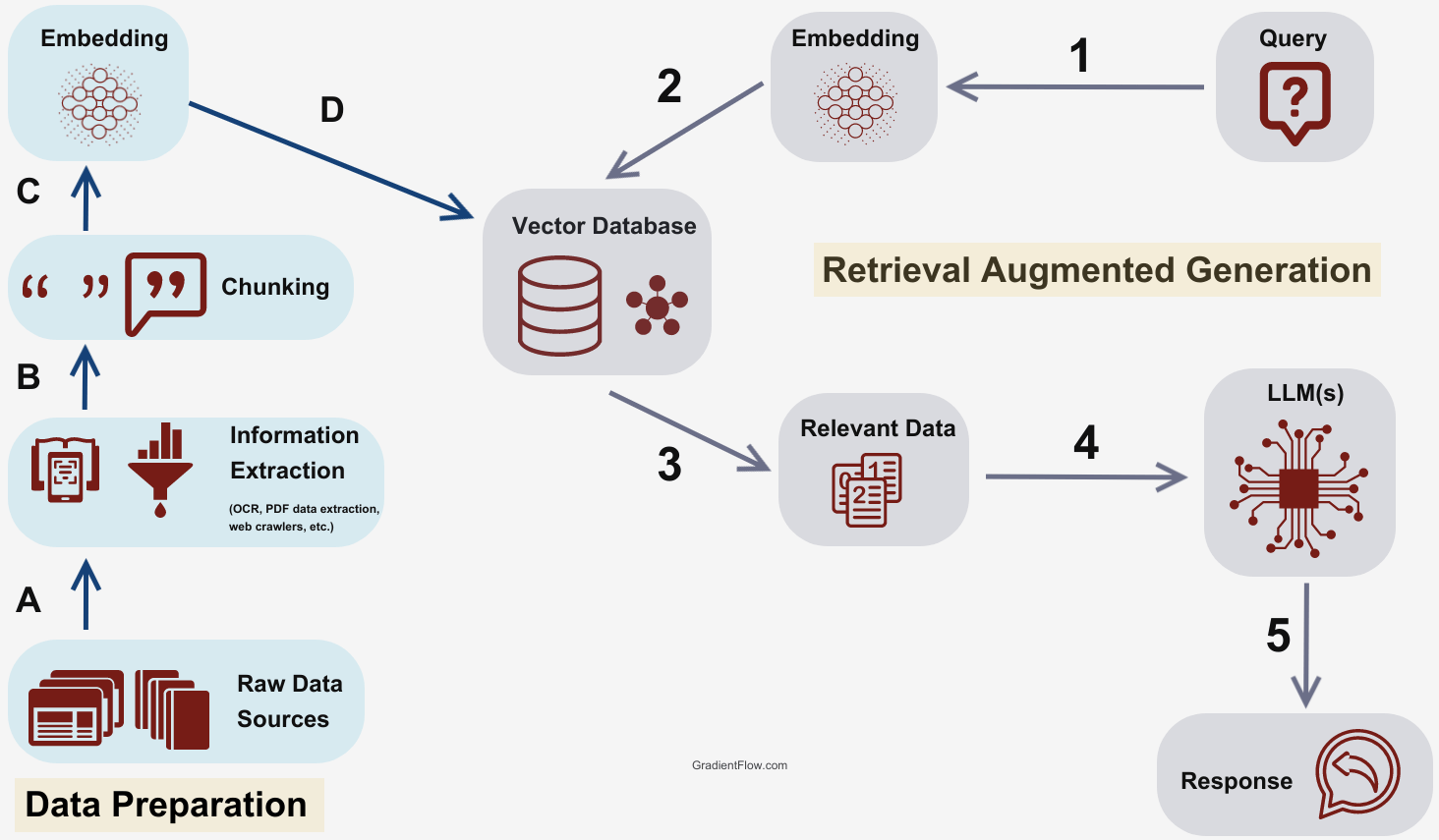
传统的长文本段落机械切分模式可能影响 embedding 结果,而直接查询检索方式可能导致问题理解不准确。以上问题可能会导致 RAG 的检索精度不足,进而影响到 LLM 的生成效果。近期,RAG 的优化重点在于提升检索准确性和处理复杂问题的能力,研究者们提出了如 GraphRAG 和 MultiHop-RAG 等先进架构。
不过对于一个记账应用来说,最简单的 RAG 架构,已经能够满足我的需求了。
应用设计
思路
在之前的文本转换逻辑中,我会通过 {金额} {流出账户} [{流入账户}] {payee} {narration} [{tag1} {tag2}] 的文法来将通过 IM 输入的文本流转换为 Beancount 交易。但如果要构建向量数据库,那匹配元素的优先级排序应是 payee > narration > 账户 > tag,而金额信息只会对检索构成干扰。
因此,我会取出最近 1000 条交易,然后将交易记录转换为 {payee} {narration} {账户列表} {标签列表} 的文本,以此来构建向量数据库。由于我的交易中包含中文,因此我选用了 BAAI/bge-large-zh-v1.5 来做 embedding。
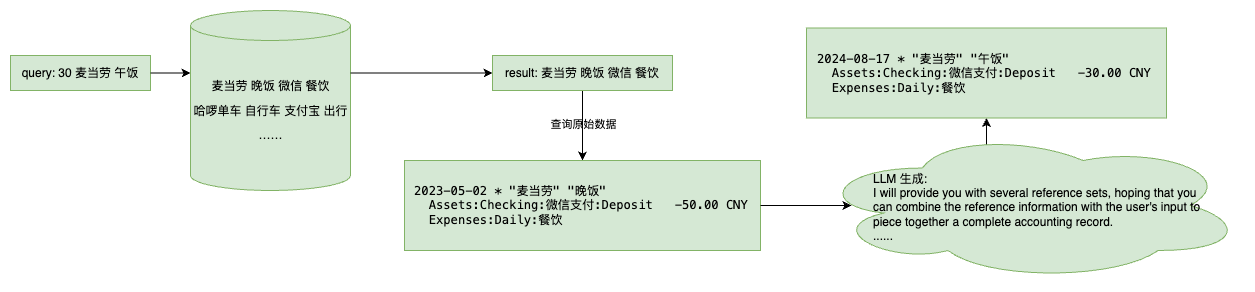
但是,在检索时,我是不太容易去判断用户输入的每个词具体属于哪个元素的,因此我会将用户的输入除去开头的金额后,直接进行 embedding,然后通过计算余弦相似性找出相关记录,并找到它们对应的原始交易。
都说汉字的序顺并不定一能影阅响读,但 embedding 不会完全认这个。 为了获得更好的匹配和补全效果,我还需要通过 LLM 来仔细分辨里面的每一个元素,并对可能有问题的元素进行修正。比如,当我使用了新的支付账户进行交易,但系统中没有检索到完全一致的交易记录时,就可以用 LLM 来帮我进行账户的替换。
流程设计
用户输入内容后,首先还是会按照原本的文法来尝试对输入信息进行匹配。若匹配失败,则可以选择两种模式:向量数据库检索,或 RAG 生成。
使用向量数据库匹配时,会从现有数据库中找出多个相近的条目,然后对其中的词语重排后,再传给原有的生成逻辑,从而生成候选条目。

若使用 RAG,则会通过向量数据库匹配后,将对应的原始条目塞给 LLM,让 LLM 参考已有条目和用户输入,生成一条全新的条目并输出。
尾声
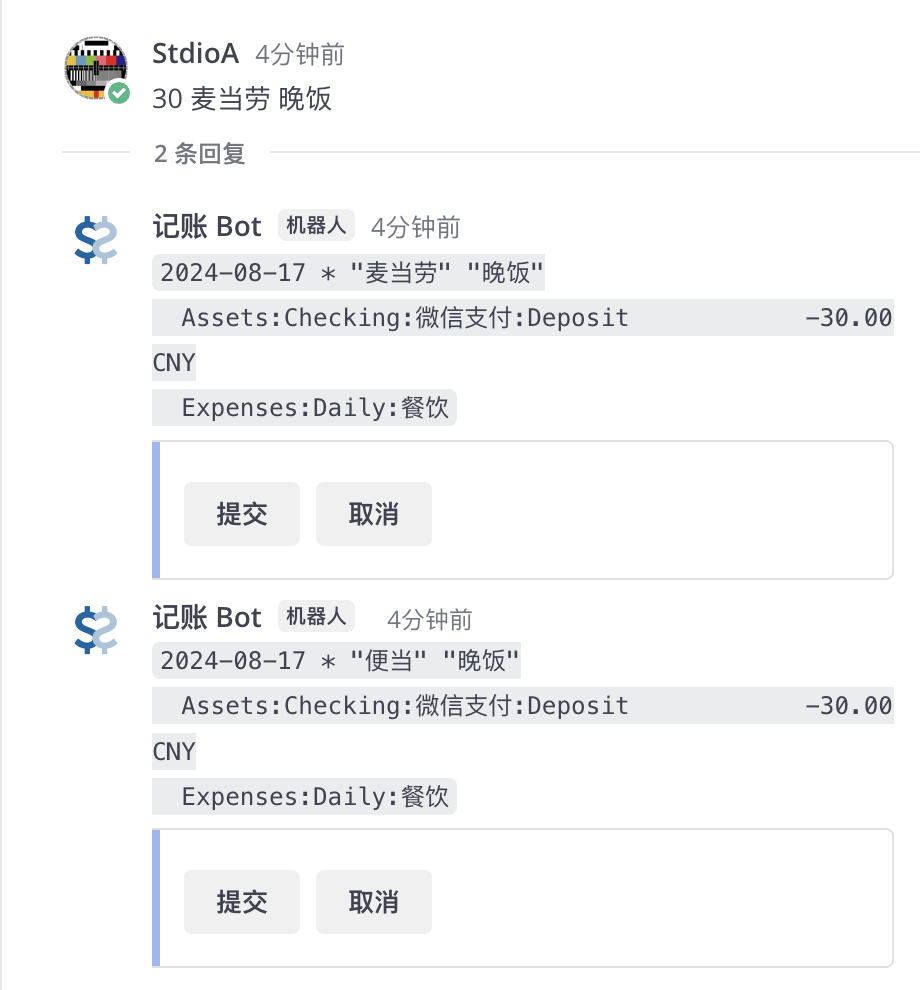
开发完成后,两种匹配模式都尝试用了几天。向量匹配效果还不错,绝大多数情况下,前两个候选输出中就能够包含目标结果;RAG 在 gpt-4o-mini 和 DeepSeek-V2-Chat 模型上的效果都能令我满意。不过我并不太需要使用 RAG,因此日常用的更多的还是向量数据库匹配的模式。
不过话说回来,很多人使用 Beancount 本身就是有隐私保护方面的考虑,因此也不太能够接受把自己的账目数据喂给大公司去用于训练的行为。不过好在现在的端侧小模型对硬件的要求也不算很高,我们也可以用 ollama 提供本地的 LLM 和 embedding 服务来保护隐私。
作为参考,我使用本地的 Gemma2-2B 模型试了一下,补全效果非常糟糕,不过 Qwen2-7B-Instruct 在我随便写的 prompt 下就能够正常工作了。
这个 Bot 的代码已经开源,前端支持 Telegram 和 Mattermost,欢迎大家使用和 star: https://github.com/StdioA/beancount-bot