熟悉我的同学都知道,GNE可以自动化提取任意文章页面的正文,专业版GnePro的准确率更是在13万个网站中达到了90%。
但GNE一直不支持列表页的自动抓取。这是因为列表页的列表位置很难定义。例如下面这张图片:
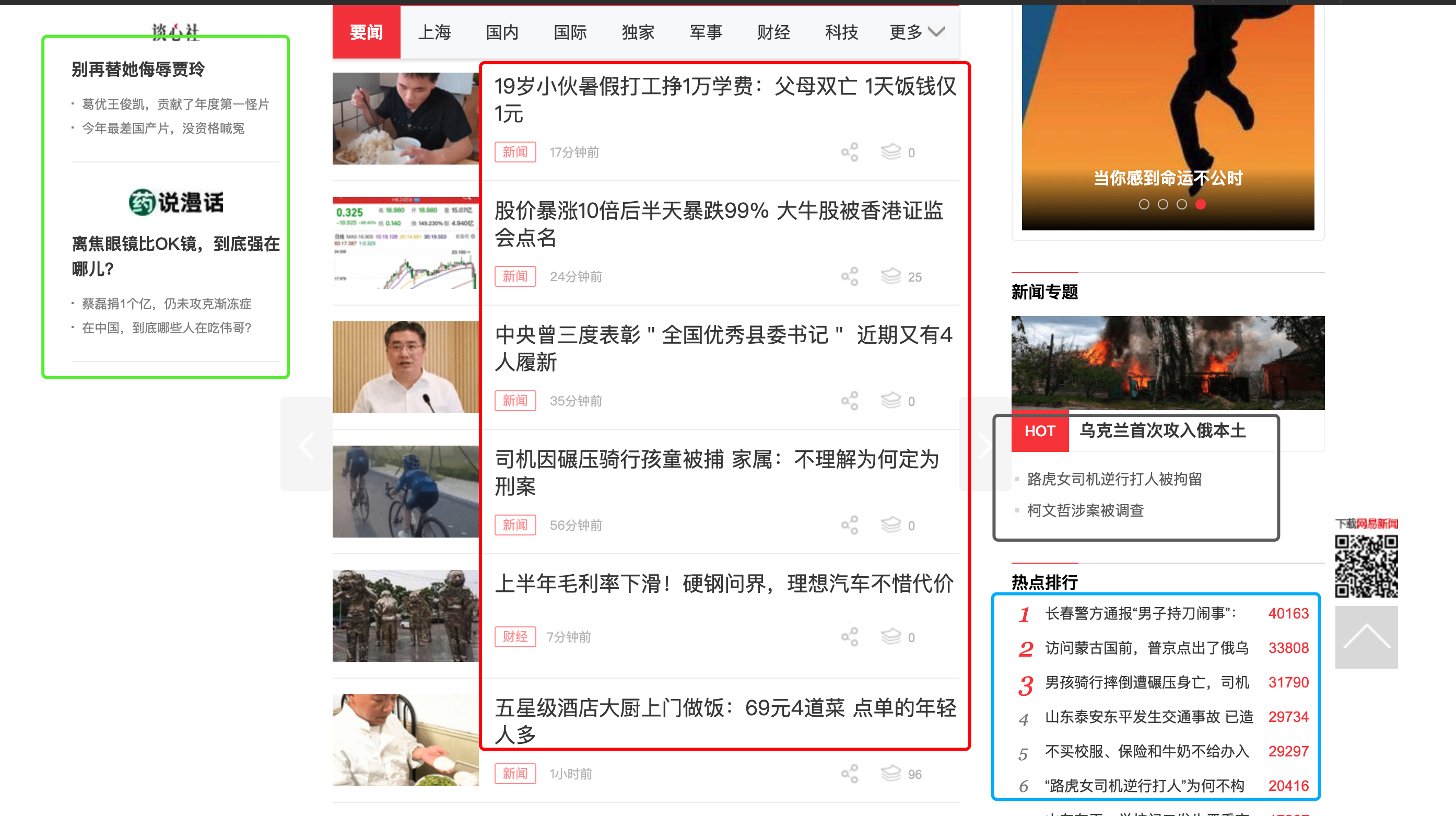
对人来说,要找到文章列表很简单,红色方框框住的部分就是我们需要的文章列表。但如果让程序自动根据HTML格式相似的规律来寻找列表页,它可能会提取出蓝色方框的位置、绿色方框的位置、灰色方框的位置,甚至导航栏。
之前我也试过使用ChatGPT来提取文章列表,但效果并不理想。因为传给大模型HTML以后,他也不能知道这里面某个元素在浏览器打开以后,会出现什么位置。因此它本质上还是通过HTML找元素相似的规律来提取列表项目。那么其实没有解决我的根本问题,上图中的蓝色、绿色、灰色位置还是经常会提取到。
前两天使用GLM-4V识别验证码以后,我对智谱的大模型在爬虫领域的应用充满了期待。正好这两天智谱上线了视频/图片理解的旗舰模型GLM-4V-Plus。于是我突然有了一个大胆的想法,能不能结合图片识别加上HTML,让大模型找到真正的文章列表位置呢?
说干就干,我这次使用少数派的Matrix精选页面来进行测试。如下图所示:
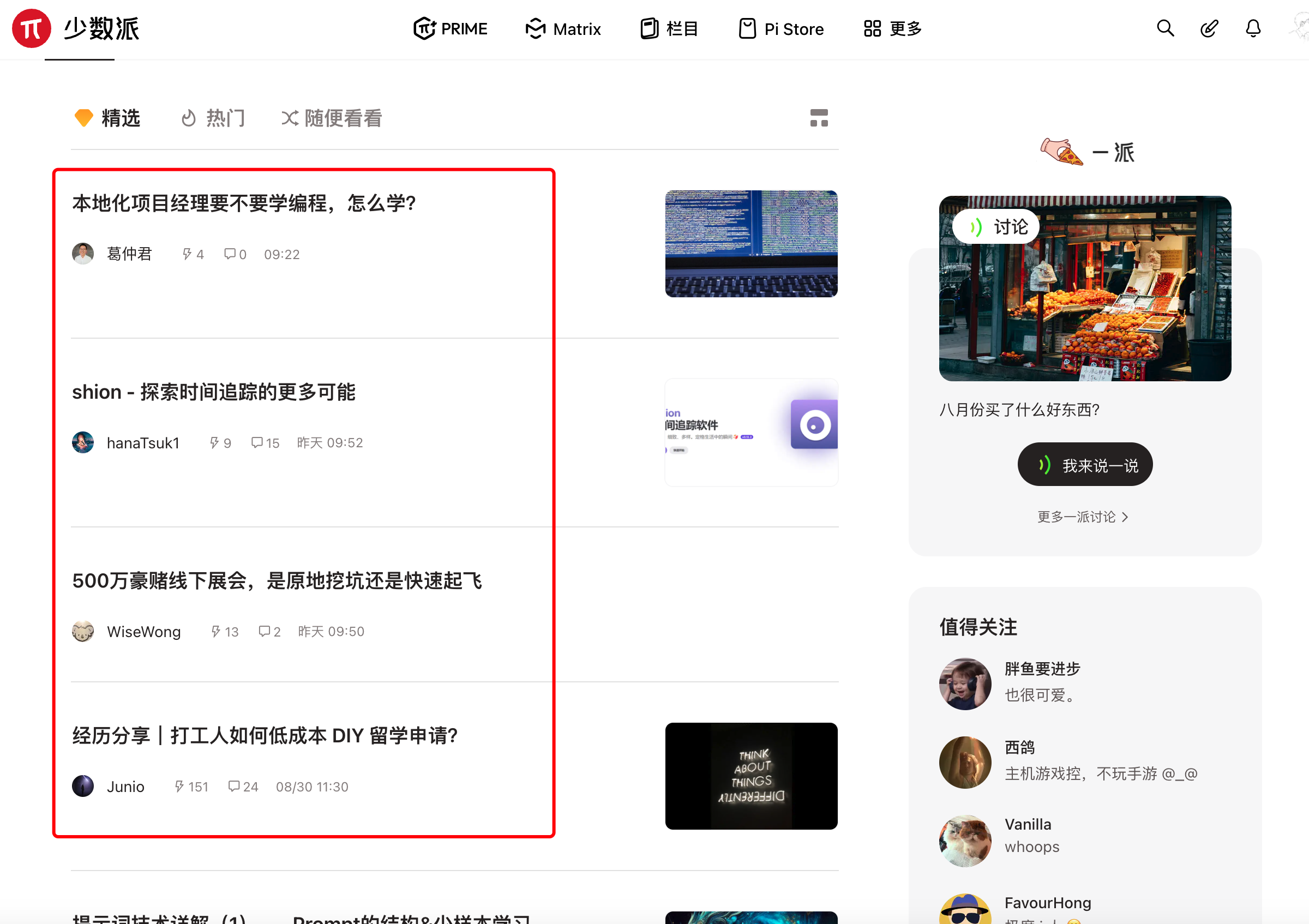
需要注意的是,这个页面是异步加载的页面,因此通过在开发者工具中右键来获取包含列表页的源代码,如下图所示:
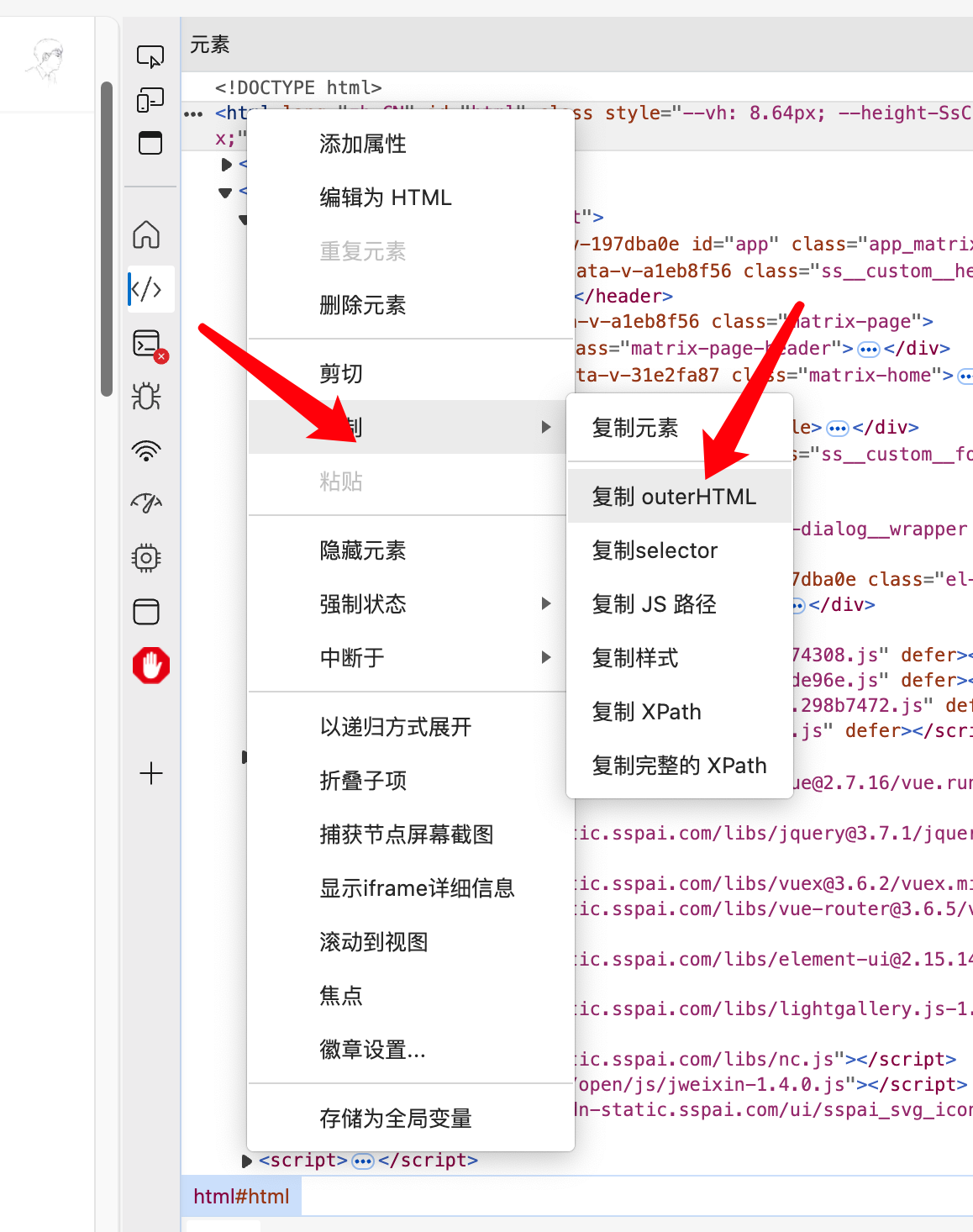
接下来,为了节省Token省钱,我首先对这个HTML进行清洗,移除一些显然不需要的HTML元素:
1 | from lxml.html import fromstring, HtmlElement |
代码如下图所示:

其实有很多页面,在源代码里面会有一个
<script>标签,它有一个type属性,值是application/ld+json。它的text是一个大JSON,包含了页面上的所有有用信息。只需要提取这个JSON并解析就能拿到需要的全部信息。不过这个情况不在今天的讨论范围,因此我们也把<script>一并删去。
接下来,对少数派这个列表页做一下截图,调用GLM-4V-Plus模型时,同时上传截图和源代码。如下图所示:
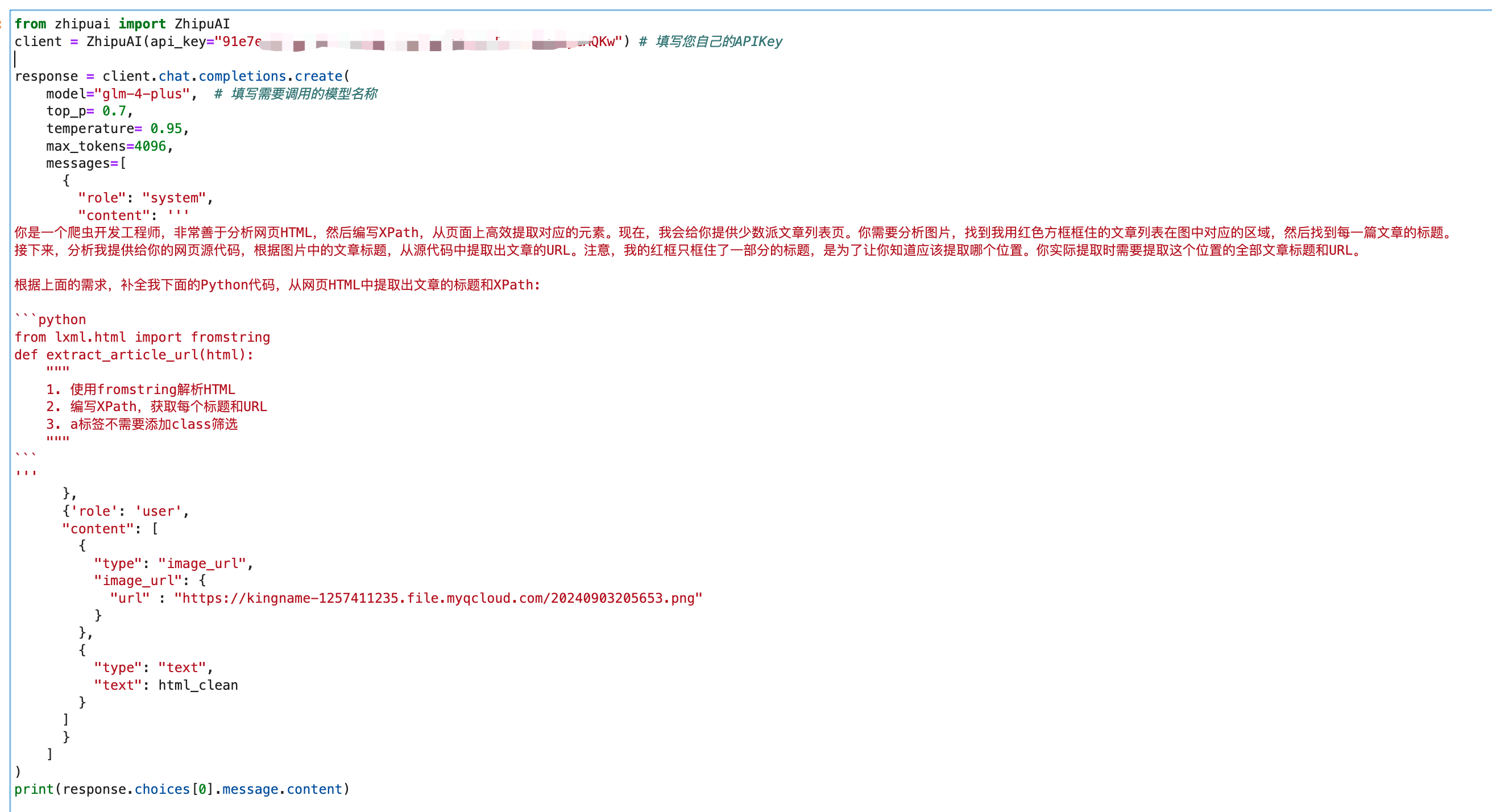
在system里面,我定义了一个函数,并通过注释说明这个函数需要实现什么功能。让GLM-4V-Plus首先理解图片,然后分析HTMl,并补全我的Python代码。
最后运行生成的代码如下图所示:
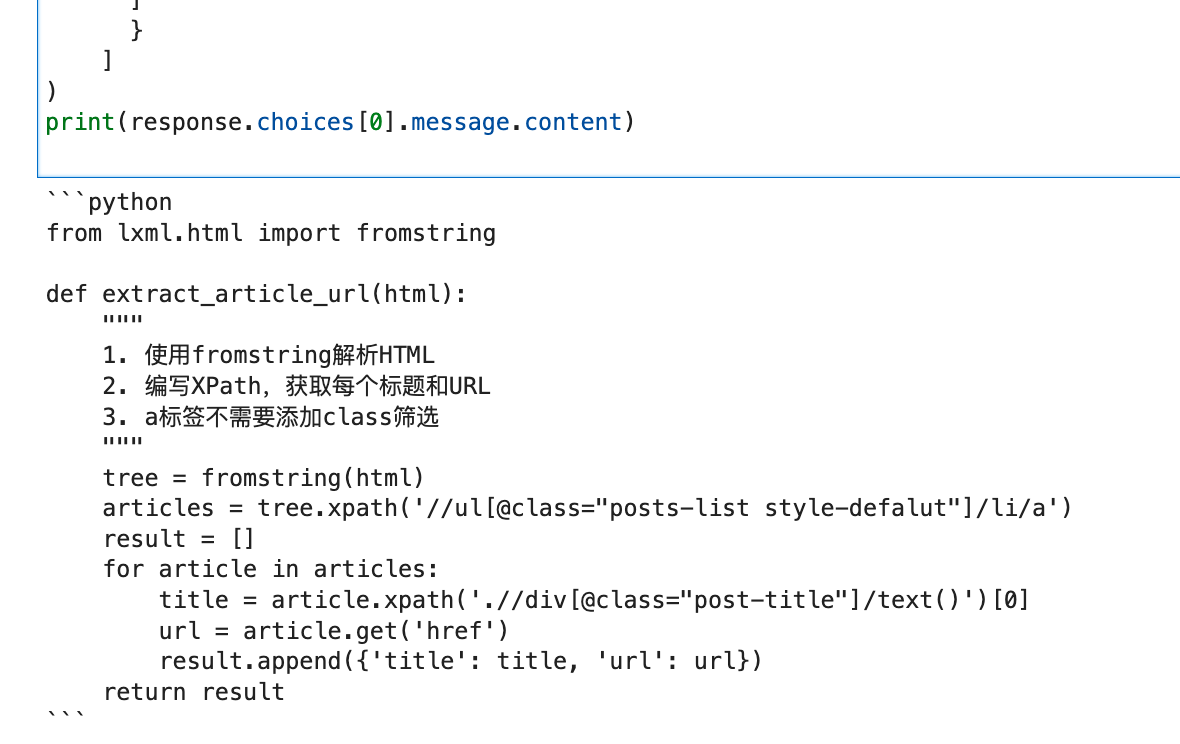
我把这段代码复制出来执行,发现可以正确解析出列表页中每篇文章的标题和URL,如下图所示:
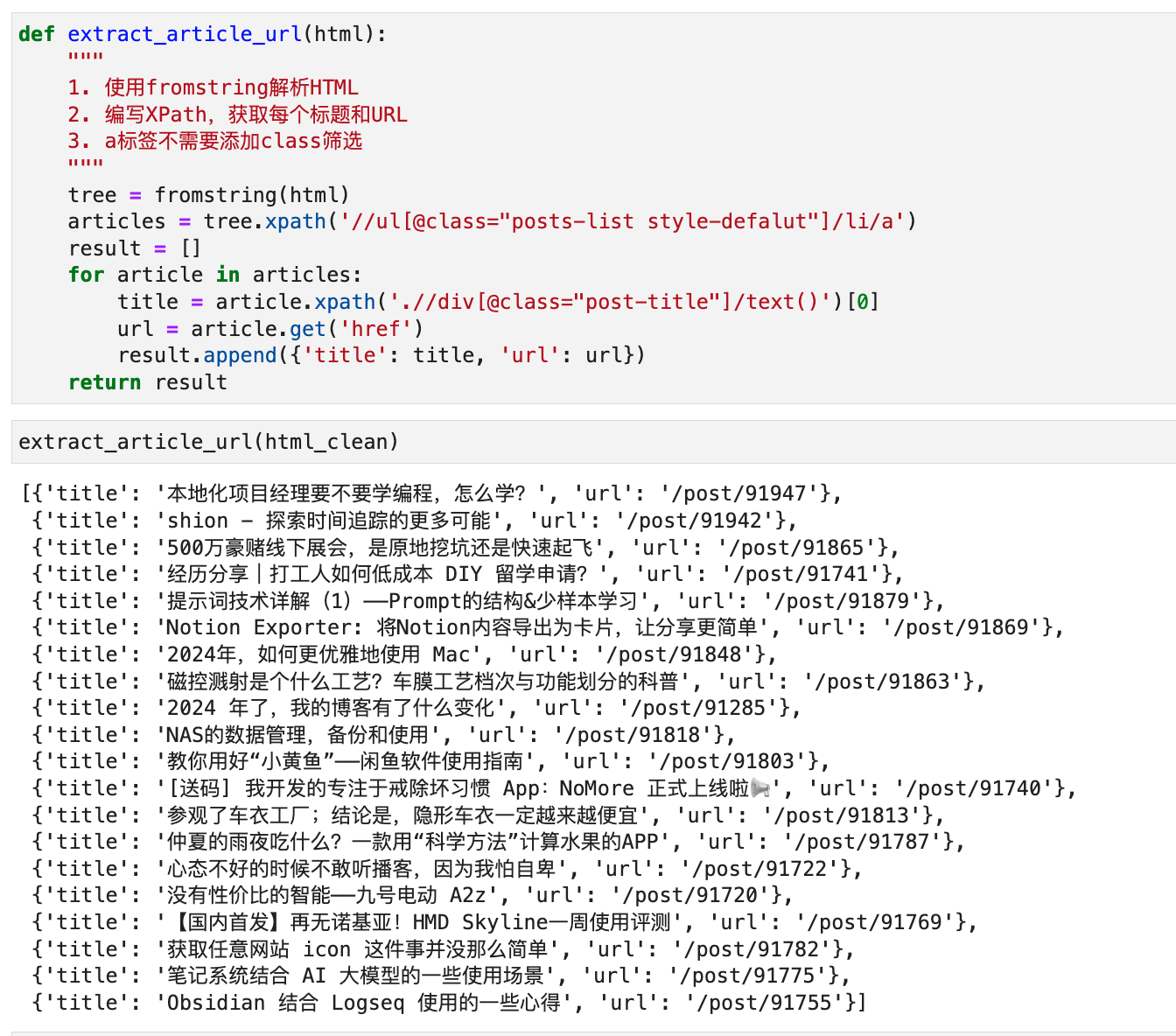
它自动生成的XPath,到少数派页面上手动验证,发现确实能够正确找到每一篇文章:
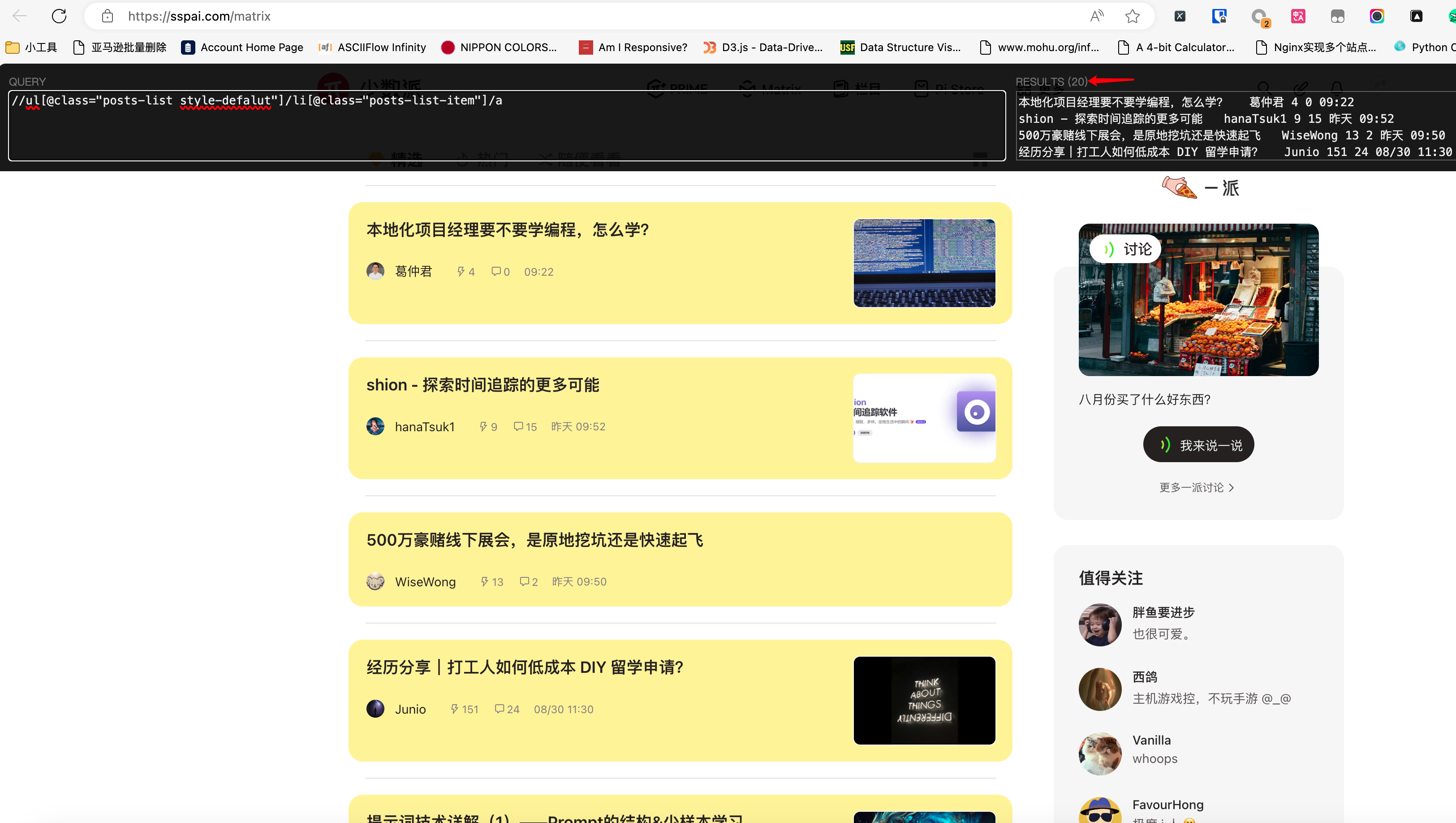
看起来,GLM-4V-Plus模型真的是天然适合做爬虫啊。如果我再把DrissionPage用上,通过模型的Tool Call机制来控制DP操作页面,嘿嘿嘿嘿。
如果大家对GLM-4V-Plus+DrissionPage结合的全自动爬虫有兴趣,请在本文下面留言。我们下一篇文章,就来实现这个真正意义上的,自己动,自己抓,自己解析的,拥有自己大脑的全自动爬虫。
我看智谱的推广文案里面说,推出-Plus旗舰模型,专注于大模型的中国创新,让开源模型和开放平台模型,推动 AI 力量惠及更多人群。那么我们爬虫工程师肯定是第一批被惠及到的人群。