React Hook Effect
useEffect 每当你的组件渲染时,React 将更新屏幕,然后运行 useEffect 中的代码(屏幕更新渲染之后)该 Hook 接收一个包含命令式、且可能有副作用代码的函数。在函数组件主体内(这里指在 React 渲染阶段)改变 DOM、添加订阅、设置定时器、记录日志以及执行其他包含副作用的操作都是不被允许的,因为这可能会产生莫名其妙的 bug 并破坏 UI 的一致性。使用 useEffect 完成副作用操作。通过使用这个 Hook,你可以告诉 React 组件需要在渲染后执行某些操作。React 会保存你传递的函数(我们将它称之为 “effect”),并且在执行 DOM 更新之后调用它。同时你也可以使用多个effect hook,React 将按照 effect 声明的顺序依次调用组件中的每一个..
更多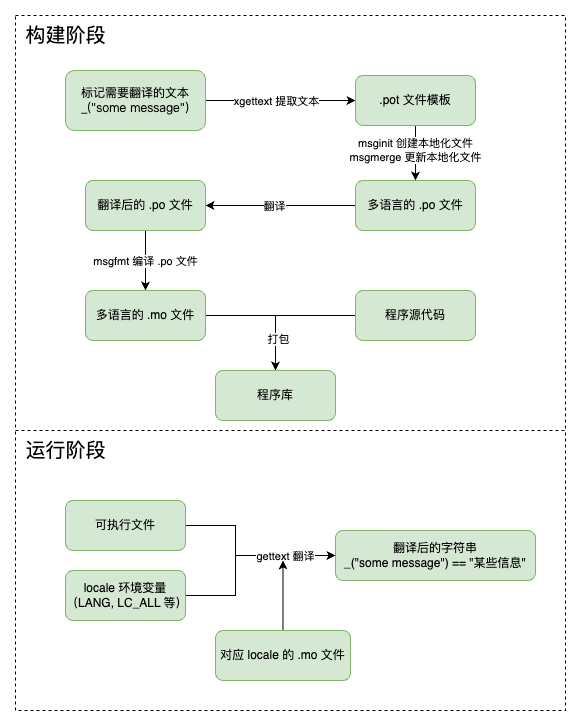
为 Python 项目提供多语言支持
突发奇想,给自己的 beancount-bot 接入了多语言支持。本文简单记录了接入和使用的流程。 在很久很久以前,我曾经在 Django 中使用过多语言支持,但还未尝试过使用底层框架为任意项目提供多语言支持。正巧昨天想将最近开源的 beancount-bot 推荐给 awesome-beancount 项目,而之前的所有文本几乎都是用中文写的。于是,我打算为它提供多语言支持,顺便学习一下 gettext. 背景 在企业中,我们通常将涉及到多语言的工作称为“国际化”工作,但提到相关领域,我们通常绕不开两个意思相近的词:国际化(internationalization,缩写为 i18n)和本地化(localization,缩写为 l10n)。 按照我的理解,国际化工作更偏向框架层面,旨在为程序提供支持多..
更多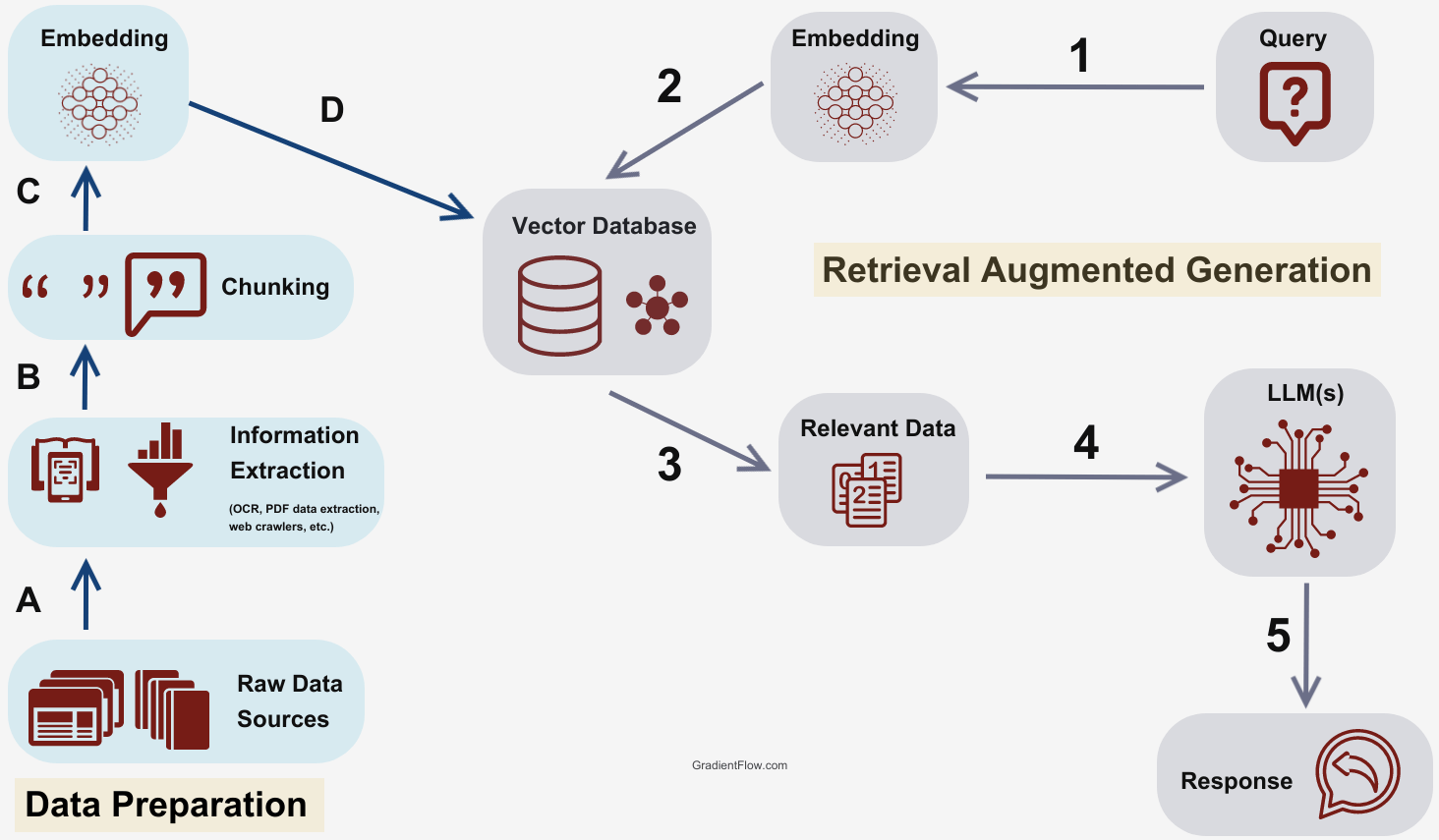
RAG 基本应用——Beancount 记账效率优化
本文来自于一个手工记账博主的脑洞大开,尝试通过向量数据库和 RAG 来想办法让自己少打几个字。顺便宣传一下最近开源的记账 bot. 背景 自从 2020 年将记账系统迁移到 Beancount 后,我就开发了一个 Telegram Bot 来辅助我记账。通过它,我可以使用 {金额} {流出账户} [{流入账户}] {payee} {narration} [{tag1} {tag2}] 的文法来快速生成一条交易记录并落库。虽然后来将这个 Bot 迁移到了 Mattermost 上,但四年以来,核心逻辑并没有做任何改动。 最近经常骑车去打球,每次骑完车之后总需要掏出手机去记账,输入诸如 1.5 支付宝 哈啰单车 自行车 的文本。虽然已经手动记账记了七年,但完全相同的内容记得次数太多了,也难免会有些枯燥。 ..
更多
GitLab/ArgoCD/Jenkins CI/CD方案梳理和对比
CI/CD的概述良好的CI/CD应该拥有哪些功能自动化构建 自动化构建触发:每次代码提交、合并请求、或其他触发事件时,自动启动构建过程。 依赖管理:自动处理项目依赖,确保构建环境的一致性。 可复用的构建脚本:使用脚本或配置文件(如Makefile、Gradle、Maven等)来定义构建过程,确保构建步骤的一致性和可复用性。 版本控制:构建过程中自动生成版本号或构建标签,以便于版本管理和追踪。 自动化测试自动化测试是CI/CD系统确保代码质量的重要功能,通过自动化测试,开发团队可以快速发现和修复问题。 单元测试:每次构建后自动运行单元测试,确保代码功能的正确性。 集成测试:在代码合并到主分支前运行集成测试,验证不同模块的协同工作。 端到端测试:模拟用户行为,验证应用的整体功能和性能。 代码覆盖率:生成代..
更多
一日一技:如何正确保护Python代码
去年我写过一篇文章《一日一技:如何对Python代码进行混淆》介绍过一个混淆Python代码的工具,叫做pyminifier,这个东西混淆出来的代码,咋看起来有模有样,但仔细一看,本质上就是变量名替换而已,只要耐下心来就能看懂,如下图所示:而我今天要介绍另一个工具,叫做pyarmor。pyminifier跟它比起来,就跟玩具一样。pyarmor使用pip就可以安装:pip install pyarmor。pyarmor是一个收费工具,但免费也能使用。免费版有绝大部分功能,加密小的脚本足够了。我们今天要测试的脚本如下图所示:运行以后如下图所示:现在,执行命令pyarmor g json_path_finder.py。对这个脚本进行加密,会在dist文件夹中生成加密后的文件,如下图所示:加密后的文件打开以后长..
更多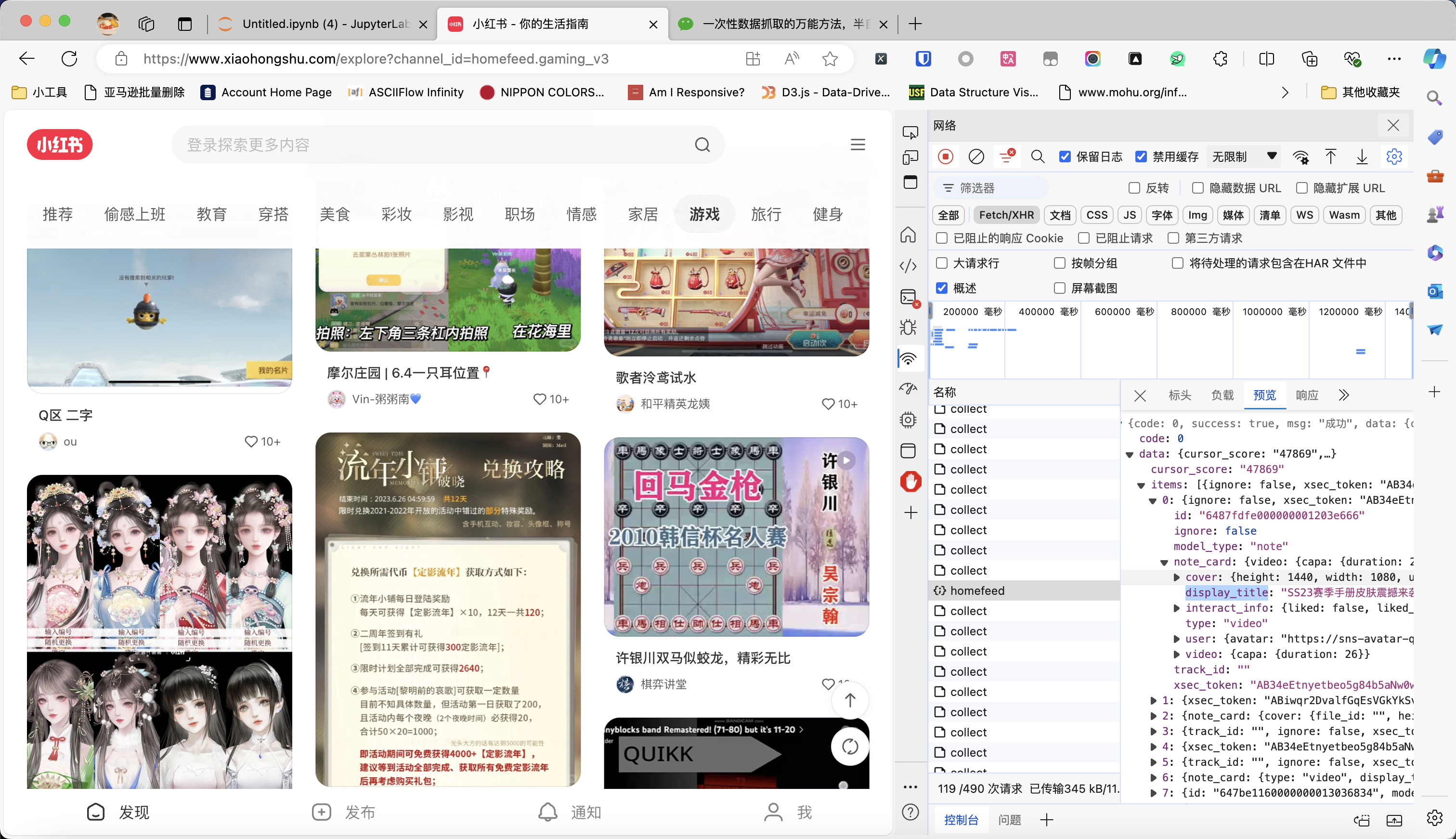
一日一技:真正的自然语言编程
在之前的文章《一次性数据抓取的万能方法,半自动抓取任意异步加载网站》中,我讲到一个万能的爬虫开发方法。从浏览器保存HAR文件,然后写Python代码解析HAR文件来抓取数据。但可能有同学连Python代码都不想写,他觉得还要学习haralyzer太累了,有没有什么办法,只需要说自然语言,就能解析HAR文件?最近我在测试open-interpreter,发现借助它,基本上已经可以实现自然语言编程的效果了。今天我们用小红书为例来介绍这个方法。如下图所示,我现在要抓取小红书首页游戏频道的帖子。通过不停往下滑动页面,我已经抓到了不少数据包。现在,把所有数据包保存为xiaohongshu.har文件(方法看我上一篇文章)。接下来,我们来安装open-interpreter,使用pip进行安装就可以了:pip ins..
更多When tailscale subnet router meet fake IP
我非常喜欢 Tailscale 这个组网工具,但在移动端设备上,通常只能开启一个 VPN。虽然 Tailscale 可以配置 Exit-nodes,但这样会接管全部流量,这显然不太理想。 Tailscale 能够自动接管设备的 DNS,并配置上游以支持其 Magic DNS 功能,同时,Tailscale 还支持 advertise-routes。利用这两个功能,再结合 FakeDNS (FakeIP) 功能,可以将国外网站的 DNS 指向 FakeDNS 的 CIDR,并将这个 CIDR 宣告到 Tailscale 的某个节点。然后,在这个节点上运行代理程序,就能实现所有 Tailscale 节点的透明代理。 我用 mosDNS + clash 实现了上述思路,目前运行体验非常好,配置并不算复杂,捋一遍..
更多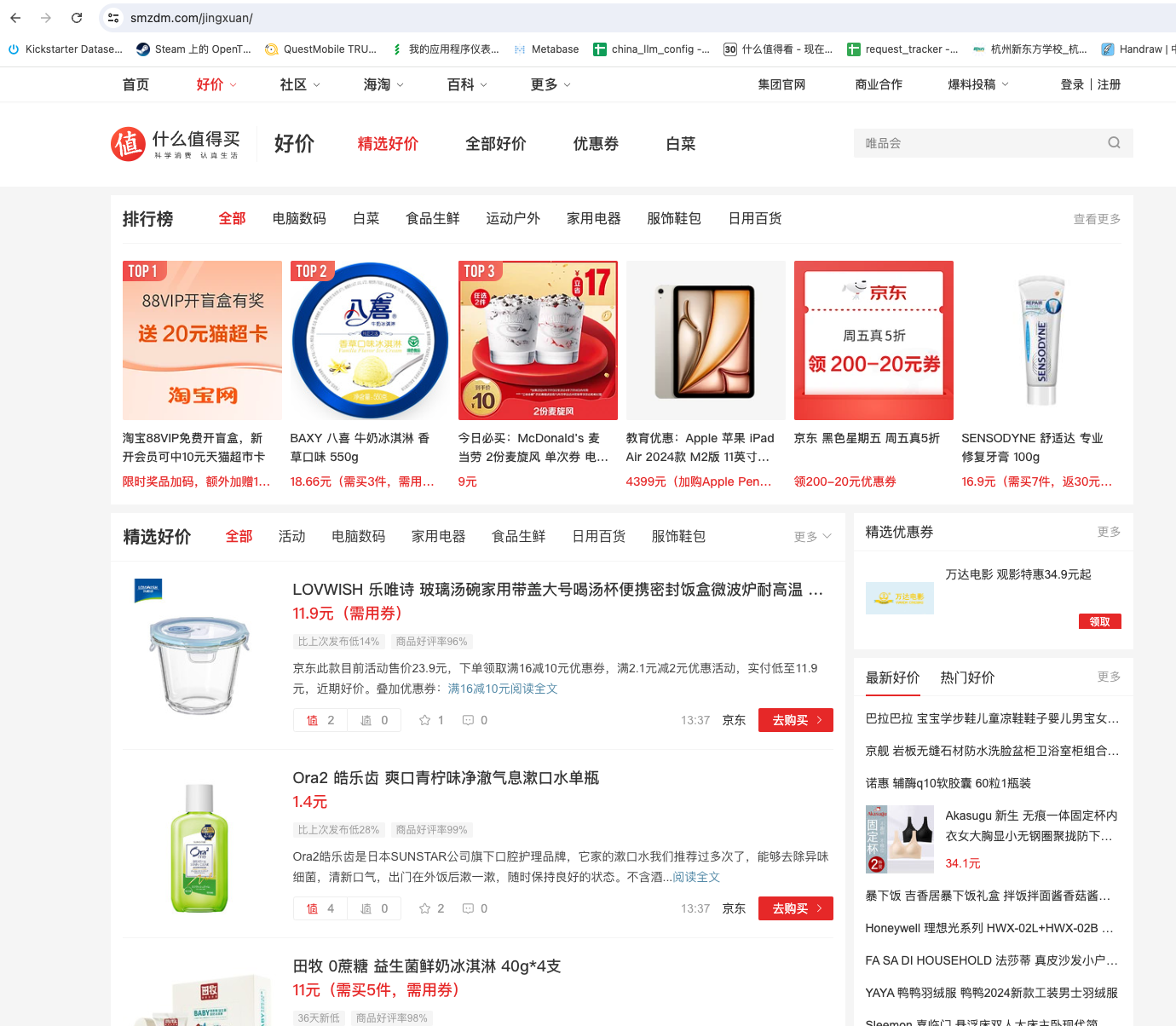
一次性数据抓取的万能方法,半自动抓取任意异步加载网站
我们有时候临时需要抓取一批数据,数据不多,可能就几页,几百条数据。手动复制粘贴太麻烦,但目标网站又有比较强的反爬虫,请求有防重放的验证,写代码抓取也不方便。用模拟浏览器又觉得没必要,只用一次的爬虫,写起来很麻烦。例如,我经常逛色魔张大妈的精选好价页面。这个页面会列出各种折扣的信息。但它只能按大类筛选,无法用关键词搜索。如下图所示我打算只看前 10 页内容就好了。但一页一页看太麻烦了。有没有什么快速爬虫,把这个列表页的内容抓取下来呢?其实这种需求,使用半自动爬虫是最简单的。不需要考虑网站反爬虫的问题,因为你使用的就是真实的浏览器,不会通过代码来发起请求。而且这个列表页的内容都是异步加载的,直接在开发者工具可以看到数据包,数据包里面就有当前页面的全部内容。如下图所示:有没有什么办法,快速把这些数据包弄下来处理..
更多
Jenkins迁移
Foreword 迁移Jenkins 腾讯云镜像导出 如果腾讯云镜像是windows,无法下载到本地,无论怎么弄都不行,所以只能手动迁移 如果腾讯云轻量镜像是Linux,可以通过几个间接的办法把整个镜像下载下来 选择轻量服务器,制作镜像 轻量服务器的镜像菜单中的共享镜像,共享给云服务器CVM 进入云服务器的镜像菜单,同地域复制,随便复制到一个地方,它就变成了自定义镜像 此时就可以通过自定义镜像进行下载 Windows Jenkins迁移 首先确保Jenkins版本一致,如果不一致迁移会导致很多错误,还不如直接重建 强烈建议每次保存一下Jenkins等相关环境的安装包,下次再迁移的时候可以直接安一样的版本 版本一致以后,看一下老的Jenkins存储路..
更多Valid HTTP verbs
从这里 想到,fetch/xhr 可以发起哪些 http verb 呢? python -m http.server 随手测试了下,发现连 !,$ 这种符号都可以作为 http verb,比如 fetch('/asdf', {method:"$"}) 这样的请求是能发起的。于是去 chromium 搜了下 "is not a valid HTTP method" 相关的解析放在 blink/renderer/platform/network/http_parsers.cc // See RFC 7230, Section 3.2.6. bool IsValidHTTPToken(const String& characters) { if (characters.empty()) re..
更多