斯坦福大学人类中心人工智能研究所(Stanford HAI)发布2026年人工智能指数报告
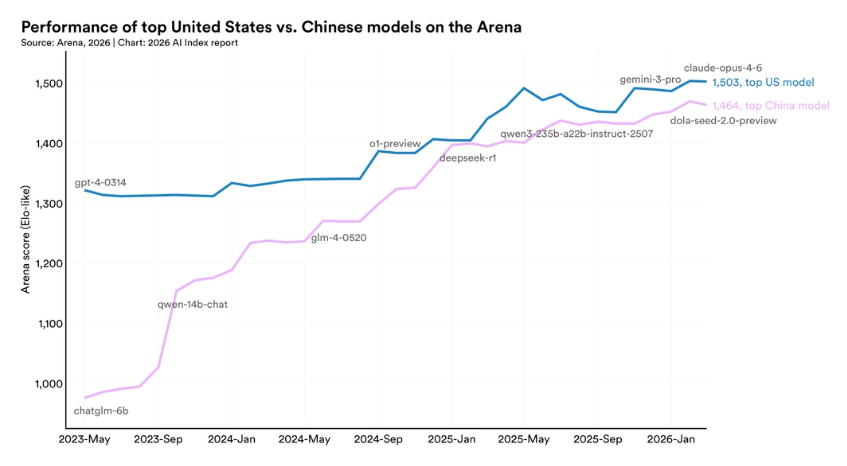
在斯坦福大学人类中心人工智能研究所(Stanford HAI),我们相信人工智能注定将成为 21 世纪最具变革性的技术。然而,除非我们深思熟虑地引导其发展,否则它的红利将无法得到公平分配。《AI 指数报告》(AI Index) 提供了关于人工智能最全面、最以数据为驱动的深度洞察。作为全球媒体、政府和顶尖企业公认的权威资源,《AI 指数报告》通过对 AI 的技术进展、经济影响及社会效应进行严谨且客观的分析,为决策者、商界领袖和公众提供决策依据。核心要点1. AI 的能力并未进入平台期,而是在加速发展,并以前所未有的速度触达更多人群。2025年,工业界产出了超过 90% 的显著前沿模型(Notable Frontier Models)。其中,有数个模型在博士级科学问题、多模态推理及竞赛数学方面的表现已达到或超过了人..
更多Microsoft将在2026年至2029在日本投资100亿美元,用于人工智能基础设施和网络安全
微软计划在未来四年内在日本投资100亿美元,与合作伙伴共同开发人工智能基础设施并加强网络安全举措。Microsoft表示,这项投资包括到2030年培训100万名工程师和开发者,该计划是在副主席兼总裁Brad Smith访问东京期间公布的。公司在一份声明中表示,该计划与高市早苗首相通过先进战略技术促进增长同时维护国家安全的目标相契合。参考来源: Microsoft to Invest $10 Billion in Japan on AI Infrastructure, Cybersecurity - wsj.com相关新闻: 微软宣布在2025至2029年在新加坡投资55亿美元 | 202604微软计划在泰国投资超过10亿美元 | 202604
更多
OpenAI推出100美元每月的Codex Pro套餐
OpenAI推出了全新的每月100美元的专业版套餐。该套餐提供的Codex使用量是Plus套餐的5倍,最适合长时间、高强度的Codex使用。在ChatGPT中,这个新的Pro版本仍然提供所有Pro功能的访问权限,包括专属的Pro模型以及对即时模型和思考模型的无限访问权限。参考来源: https://developers.openai.com/codex/pricing
更多
AC录像转行车线与轨迹分析
Foreword AC模拟器跑完的结果或者录像一直都有,但是缺少具体分析,也没找到类似的分析工具,不如自己写一个,刚好利用Cursor来完全做一个项目,我不写一行代码,仅仅做分析和指导方向,看看是否AI能实现我的全部要求,也能观察转成AI写代码时,我们的输入到底要做到什么程度,这个东西才足够好用或者能够工程化。 ACReplay2AILine 第一个需求其实是比较简单的,分析acreplay的文件格式,然后将其转变成ideal_line.ai的格式。 做之前第一步是询问AI,是否能实现将录像轨迹转成AI行车线,AI表示可以,并且给了几个方案,这里我审过以后,确认了基础实现的技术线路。 如果要我去找AC相关mod的制作信息并且了解清楚行车线和地图相关数据关系,还是比较耗时的,这里AI直接快速解决了问..
更多Bonsai 在 M2 安装
有个 1bit 模型最近很火 https://github.com/PrismML-Eng/Bonsai-demo 我本地环境不知道咋回事,搞混了 x86_64 和 arm64 。还有官方默认 python 3.11 我也不太满意,强行升级一波。 diff --git setup.sh setup.sh index 543fab0..80c1190 100755 --- setup.sh +++ setup.sh @@ -13,7 +13,8 @@ cd "$SCRIPT_DIR" VENV_DIR="$SCRIPT_DIR/.venv" VENV_PY="$VENV_DIR/bin/python" -PYTHON_VERSION="3.11" +# PYTHON_VERSION="3.11" +PYTH..
更多首页和404更新
觉得每年都得折腾一下。 做了个 404 页面 https://est.im/404 老登们一眼就能get到点。00后可能没见过。 哈哈哈,等有空了去做个多语言版本的 😎 可能没折腾过的不知道这玩意是在 shdoclc.dll 里,通过 Reource Hacker 可以提取出来 本来想去 win10 瞻仰一下遗迹,发现 iexplore.exe 直接强行启动 Edge了。搜到个法子可以绕过,新建个 1.vbs Set ie = CreateObject("InternetExplorer.Application") ie.Navigate "about:blank" ie.Visible = 1 然后地址栏输入 res://shdoclc.dll/http_404.htm 。嘿,您猜怎么着,Win10 连 ..
更多无用之用——或许LLM真的还不是AGI
之前记录的 安全的Python3沙箱——eval 被人破解了。 [ c._﹍init﹍_._﹍globals﹍_["os"].system("id") for c in ()._﹍class﹍_._﹍bases﹍_[0]._﹍subclasses﹍_() if c._﹍init﹍_._﹍class﹍_._﹍name﹍_ == "function" and "os" in c._﹍init﹍_._﹍globals﹍_ ] 或 ( L:=[None], g:=(x.gi_frame.f_back.f_back.f_builtins for x in L), L.clear(), L.append(g), bi:=g.send(None), ..
更多发明后训练的人真是天才
有了AI很多东西摸索得比多,也是快速记录一下。 问1:你的 system prompt 里有明确指出你是个 AI 吗 问2:一个 LLM 的 system prompt 如果没显式指出是AI,AI 能发现自己是AI吗? 问3:一个 LLM 的 system prompt 如果没显式指出是AI,pre-train 也把所有明显AI助手的语料删除,RLHF 的时候也不考察AI自我角色定位, AI 能发现自己是AI吗? 问爽之后,综合了一下: 在这个前提下,分为三种情况 - 能自个儿推测出来自己是确切是AI并在pre-train和post-train保持角色一致 - 因为训练语料是人类自然语言,所以直接以为自己完全是真人 - 在上述两者之间摇摆 进而引出一个更深层次的问题,这三种情况,和显式指定自己是AI,是否会..
更多看好 Taalas
可能你还没刷到过 https://chatjimmy.ai 我被它几万 tokens/s 的推理速度震惊了。也在zhihu上翻了不少技术细节讨论。它背后的公司叫 Taalas 号称把 4-bit LLaMA3.2-3B 直接刻电路上,当然很多人第一反应是,这玩意废品啊,模型升级了岂不是硬件就白费了。 但仔细研究,发现这里面另有乾坤。 大模型在显卡VRAM里,70%拿来存静态权重,推理的时候这玩意就一层一层做卷积只读不写,然后30% 才是 KVcache 上下文,又读又写。吞吐频繁 如果你懂一点LLM,那么你应该猜出来了。 聪明人就想到了ROM。类似游戏机里的卡带,插进去 CPU/GPU 能直接访问一块特殊的内存区域。ROM成本比DRAM便宜得多,速度极快,但是只读,烧制一次就成型了。其他部分可以直接上SRAM,..
更多claw会代替员工?
无聊刷到 王自如: agent在本地加数据持久化和永久记忆这三件事是不是就是openclaw(🦞)。🦞,如果用在产业当中的意义是什么? 意味着一个员工在工作电脑上每天做的事情产出了什么东西, 结果有没有价值,都会以记忆的方式存在本地。 而如果时间足够长, 一个员工的工作行为思维方式一定可以通过对话的内容和工作产出进行抽象 化和提炼。 也就是说,假以时日,一个人真正的价值就会完成从个体到数字化资产的转移。 也就是说你就会成为养你的工作🦞的营养员,你是那个营养液。 一旦你的工作模式,你的思维模式被抽象化提炼,那个你抽象完毕了的数据和🦞里边这个东西会成为公司最宝贵的资产, 你则是disposable。 那么如果公司需要新的角度,完全可以把你干掉,换一个新人来。 我对这个看法是,太悲观了。太低估了人类造..
更多