Git 连接多个远程仓库
有时候我们可能会需要 push 到多个远程仓库,比如同时链接多个代码托管平台的账号,那么可以参考本文所述的方法配置。 保险起见在操作之前请先做好备份工作,毕竟数据无价。 方法 1 - 添加多个远程仓库比如要链接两个 Github 仓库,分别是 github1 和 github2,那么: 1234567891011121314151617# 添加 github1git remote add github1 https://github.com/username/github1.git# 添加 github2git remote add github2 https://github.com/username/github2.git# 提交到 github1git push github1 master# ..
更多nodejs stream to buffer
/** * * @param {ReadableStream} stream */ async function streamToBuffer(stream) { return new Promise((resolve, reject) => { const buffers = []; stream.on('data', (chunk) => { buffers.push(chunk); }); stream.on('end', () => { resolve(Buffer.concat(buffers)) }) stream.on('error', (error) => { re..
更多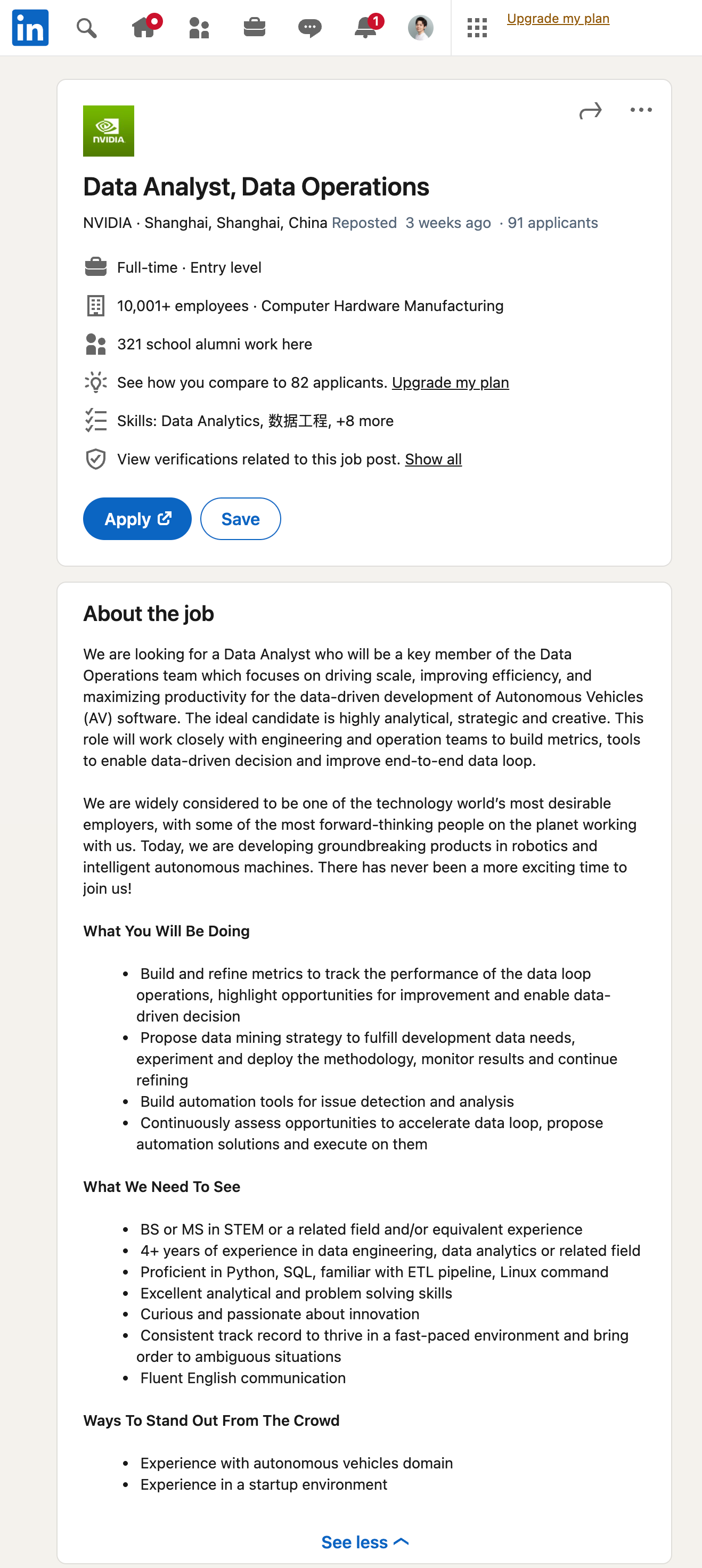
一日一技:自动提取任意信息的通用爬虫
使用过GNE的同学都知道,GNE虽然是通用爬虫,但只是文章类页面的通用爬虫。如果一个页面不是文章页,那么就无能为力了。随着ChatGPT引领的大语言模型时代到来,这个问题基本上已经不是问题了。我们先来看一个效果。首先打开Linkedin,随便找一个招聘的岗位,如下图所示:然后,我们直接使用GPT从这里提取信息:对应的Prompt为:12345你是一个数据提取小助手,能够从一大段招聘相关的文本中提取有用的信息并以JSON格式返回。{经过清洗的网页源代码或者文本}请从上面的文本中,提取招聘相关的信息,返回数据格式如下: {"title": "岗位名称", "full_time": "是否为全职", "employee_num": "雇员数量", "level": "岗位等级", "skill": "岗位需要的..
更多ChatGLM微调记录
介绍以ChatGLM-6B ptuning提供的微调代码来进行测试,整体代码在此。 训练和推理训练就直接使用官方代码啦,推理也是滴,整体流程跑通都很顺畅,整体是采用quantization_bit=4,所以单卡(5~6G显存)就能跑的起来。 记录几个有意思的点。 1. p-tuning这个是众多Parameter Efficient fine-tune实现方式之一,其发展历程简单理解有两个阶段,一是人工构造template,二是机器自己学习一个template。 比如一开始做分类,例如“这个沙发怎么样”,那就在这句话前面(当然也可以放到后面)加上一个template,比如情感分析,这个沙发怎么样,你觉得这句话是正向还是负向:这个沙发怎么样,那训练时只对这个template进行微调,因为微调seq_len很..
更多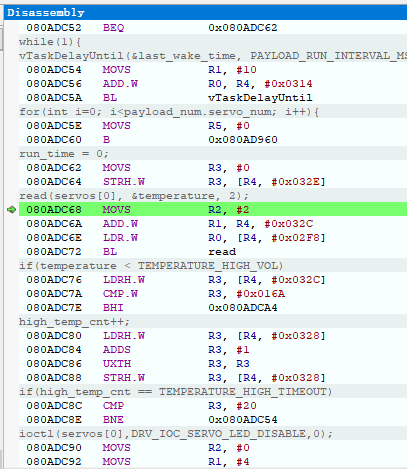
SES使用Ozone调试FreeRTOS
Foreword Debug遇到一个诡异情况,之前没注意过 单步失效 简单说系统里有很多地方在read,但是debug的那个read,在进入read内部以后,会出现整个堆栈指针都跳变成另外一个线程中read流程 ssize_t read(struct file *filep, void *buf, size_t nbytes) { struct inode *inode; int ret = -EBADF; configASSERT(filep); inode = filep->f_inode; /* Was this file opened for read access? */ if ((filep->f_oflags & O_RDOK) == ..
更多
GnePro:文章类通用爬虫接口
GnePro是开源项目GNE的付费版,能够实现如下功能:输入任意文章页面的URL,返回标题/作者/正文/发布时间/图片/面包屑等一系列信息支持异步加载文章页提取支持上传自定义的HTML代码提取正文支持自动检测网页编码支持自动提取网页全部URL在8个国家13万个新闻类网站进行测试,准确率高达90%提取文章正文12345678910111213141516171819import requestsimport jsonurl = "https://crawler.kingname.info/gne/crawl"body = { "url": "https://www.kingname.info/2023/10/17/rubbish/", "js": False, "charset": "auto"}he..
更多