我的 Vibe Coding 最佳实践——ADR文档
工作和业余也用AI写代码,大大小小项目都经历了。从 rules, skills, spec, agent 到 harness 都玩过了 从AI嘴里发现一条比较稳的套路——ADR文档 rule, skills, spec 这些东西最大的问题就是瞎jb指挥。ADR 的好处是记录why,以及决策演变历史。 贴一段我整理的 ADR 文档就明白了: --- title: 如何使用 ADR id: ADR-001 date: 2026-06-26 09:01:21 status: accepted --- ADR ADR(Architecture Decision Record,架构决策记录)的核心目标很简单:记录为什么做出了某个重要技术决策,而不是记录系统长什么样。 目前比较常见的是 MADR、Nygard ADR..
更多MacOS 快速插入当前时间
第一步:创建快捷指令 打开 Shortcuts。 点击右上角 + 新建快捷指令。 添加动作 1:日期 搜 添加 日期(Current Date) 动作,默认为当前时间 添加动作 2:格式化日期 添加 格式化日期,日期格式 自定义,填 yyyy-MM-dd HH:mm:ss 添加动作 3:Applescript on run {input, parameters} -- 稍微延长一点延迟,确保触发快捷键的手指已经离开键盘 delay 0.1 -- display dialog "Current date" -- 将 Shortcuts 传入的 list 转换为字符串 set ts to item 1 of input as string tell application "System..
更多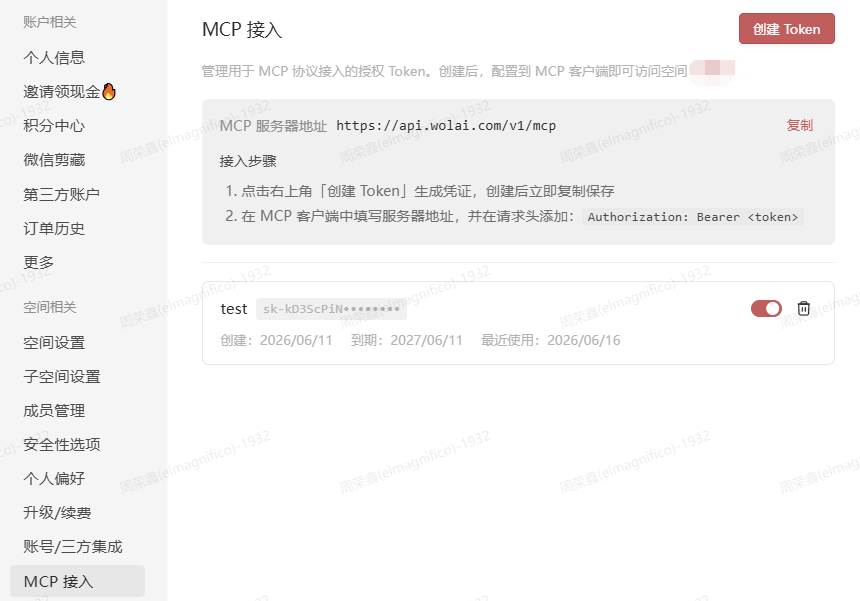
wolai MCP
Foreword wolai这几年被阿里收购以后,马锐拉似乎就不在台前了,更新节奏也从「一天一更」退化成了「一年一更(大概)」。我们刚用 wolai 那会儿正好是他还在的时候;后来他去阿里当副总裁搞 AI,我们提的意见就跟进了漂流瓶——能漂到对岸算缘分。更新说明文档一两年没认真维护,新出的 MCP 也不宣发,偷偷地,跟地下接头似的,还得自己打听才知道有这玩意儿。 前一段时间贼火的《置身钉内》,我也啃完了——7.5 万字,三易其稿,读完感觉自己也在 C6 项目室吸了两口霉味空气。马锐拉在相关文章里说过自己早已辞职;我这边则是刚把 wolai MCP 接进 Cursor 试了一圈,配置顺手记一下,踩坑也顺手记一下。 wolai MCP 开启wolai MCP 首先创建好MCP的Token,一次性展示,..
更多locate cost
翻到一个 AI 编程的出错提示 Could not find oldString in the file. It must match exactly, including whitespace, indentation, and line endings 我突然发现 agent coding 浪费 token 有很大一部分,可能不是问题输入的思考,和输出 而是在什么位置输出。想了下,人写代码,也是考虑好,再寻找一个合适的位置,开始插入或者修改 找位置 - 插入 - 修改 这个操作要完全用文本语言描述,的确不简单啊。甚至可以说超级复杂。 问了下AI,这个叫 locate cost 。定位成本 要做好这一点,Banthropic 他们的做法是 bash,grep。玩得花的是 SAT,diff,patch 什..
更多
AI自进化
Foreword 最近看了一个文章,有点意思,有点想法,记录下来。 AI自我迭代 https://mp.weixin.qq.com/s/AXyCo0RRwW_HKLpkUx1jUg 这篇文章是 CSDN 编译的 Anthropic 长篇报告《When AI Builds Itself(当 AI 构建自身)》,核心观点是:AI 正越来越多地参与 AI 本身的研发,”递归式自我改进(Recursive Self-Improvement)”时代可能比想象中来得更早。 Anthropic 梳理了自己的研发演进路线:2021-2023 年人类工程师纯手写构建第一代 Claude;2023-2025 年聊天机器人生成代码片段、人工复制到 IDE;2025-2026 年 Claude Code 等编码 Ag..
更多基于 git 的零拷贝静态web服务器
无聊,产生了个crazy的想法。 git 内部用 zlib 压缩文件内容 Content-Encoding: gzip 也是 如果web服务器输出 .git 里的 静态 内容,是不是可以减一个二次解压/压缩步骤??? blob sha1 直接当etag? 跟AI较量了几轮,一开始它说做不到。因为 blob 的格式比较变态。因为 hello world... 在 .git/objects/ab/cdef... 里的东西是这么存的 zlib(blob 1234\0hello world...) I was like ???日他妈真变态啊。这前面是写死了 blob <size>\0 然后把文件内容放在一起,再压缩的。 .git 这设计脑子有病啊。。。为啥不是原始文件gz而是加个头去gz。。。 此路不通!结..
更多AI 时代的软件自由
我一直很喜欢好用的软件。 GUI 软件里,Raycast、Fork、Tailscale 这类软件我已经用了很久。它们的交互、默认行为和完成度都很舒服,也会反过来影响我理解“好软件”应该是什么样子。 命令行软件里,Neovim、kitty、fzf、ripgrep,以及各类 Unix 风格的小软件,同样非常符合我的品味。它们更强调可组合、可脚本化和低摩擦的日常使用,这也是我一直很喜欢命令行环境的原因。 只是到了某些非常具体的场景,我会产生一些很个人的偏好。比如 Markdown 预览窗口最好从命令行直接打开,壁纸筛选最好能理解一点主观审美,AI 工作台最好贴合我自己的使用环境。这些需求夹在成熟软件之间,通常很难刚好被某个现成软件完整覆盖。继续找下去当然也可以,但现在“自己补一个小软件”的成本变低了。 这里说的软件自..
更多Skills进阶
Foreword 前一篇Skills算是简单的试用,日常用起来也没问题。但是如果要给一个软件写 Skills,把软件能力变成 AI 可以控制并且能完成你设定 pipeline 的 Skill,实践起来就有一些不一样了。 这里以 MenuReel(连锁餐厅数字菜单动效短片编排软件)为例,记录一下实际落地时和「Blog 润色 Skill」这类简单 Skill 的差异。 其实 MenuReel 的程序接口还没全部实现,但我已经提前通过 Skill 写一套「模拟调用协议」,让 Agent 按真接口的方式逐步执行完整 pipeline,而不是口头说「我已经帮你创建好了 10 个镜头段落」。反复试用的目的,是发现 Skill 没覆盖的地方,以及产品、接口上缺少的能力,从而把接口和产品补全,真接口一上线就能正常用。 ..
更多AI和柜台费
现在这个时间点,观察到两件事: 华为的大模型哑火。国内的AI圈反而没那么多恶臭拉踩舆论 雷不斯天天给MIMO搞新闻。一开始是免费用在Openrouter刷榜;然后在大家都玩按次数的 codng plan它家率先搞 token plan涨价;然后又是 100T 申请免费送;然后跟ds4同款缓存优化降价;然后又是给流失老付费用户免费一个月套餐 MIMO是很用力的去刷榜。why? 马斯克几百亿买 cursor,一个vscode套壳,why? 这两个问题,我在过去几周一直琢磨,那就是 AI 行业和 软件 互联网 最大的差别,他是有边际成本的。他的玩法变了 雷不斯刷榜的 Openrouter 和马斯克买的 Cursor,还有遍地开花的 “中转站”,而且据说有大厂买中转站数据去训练和蒸馏。 边际成本不为0 ,中间商,这..
更多KVM/QEMU 初探
看过我其他文章的朋友应该能看出来,我一直是一个 self-hosted 爱好者。无论是折腾 PVE、网络,还是各种跑在自己服务器上的服务,虚拟化都是绕不开的一层。平时用起来倒是很自然,但越用越会好奇:一台 VM 到底是怎么被跑起来的?PVE 和 virt-manager 这类工具背后究竟做了什么? 这个学习计划其实搁置过很久。QEMU/KVM 的入口并不算友好,QEMU 参数、libvirt、KVM API、virtio、tap/bridge 每个方向都能展开,之前总觉得需要一整块时间才能系统梳理。现在有了 Codex 这样的 agent,反而终于可以释放一下这部分好奇心了。 当然,Codex 并不能替我理解 KVM/QEMU。它更像是一个可以被反复追问的搭子,真正有价值的还是我能不能问出下一个问题。 这里..
更多