一日一技:自动提取任意信息的通用爬虫
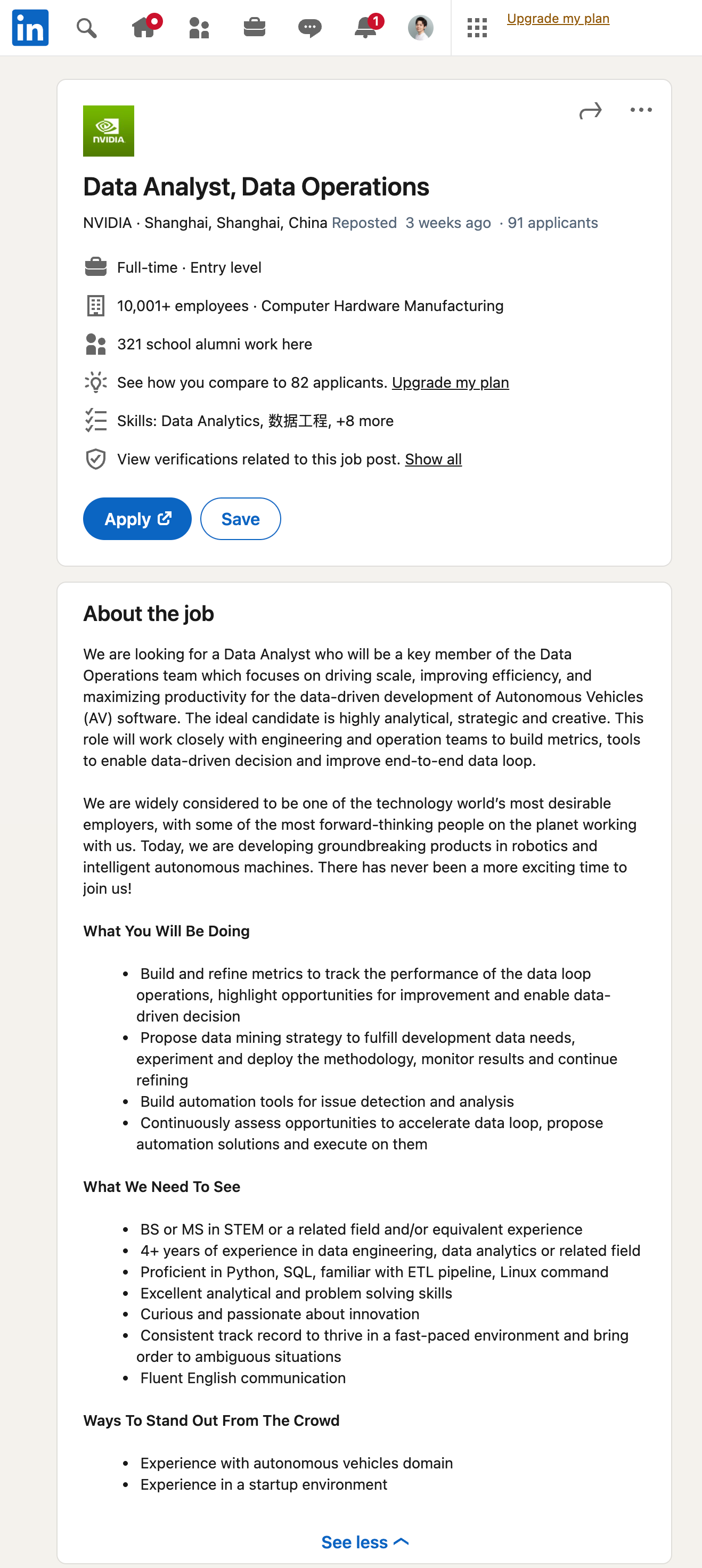
使用过GNE的同学都知道,GNE虽然是通用爬虫,但只是文章类页面的通用爬虫。如果一个页面不是文章页,那么就无能为力了。随着ChatGPT引领的大语言模型时代到来,这个问题基本上已经不是问题了。我们先来看一个效果。首先打开Linkedin,随便找一个招聘的岗位,如下图所示:然后,我们直接使用GPT从这里提取信息:对应的Prompt为:12345你是一个数据提取小助手,能够从一大段招聘相关的文本中提取有用的信息并以JSON格式返回。{经过清洗的网页源代码或者文本}请从上面的文本中,提取招聘相关的信息,返回数据格式如下: {"title": "岗位名称", "full_time": "是否为全职", "employee_num": "雇员数量", "level": "岗位等级", "skill": "岗位需要的..
更多
GnePro:文章类通用爬虫接口
GnePro是开源项目GNE的付费版,能够实现如下功能:输入任意文章页面的URL,返回标题/作者/正文/发布时间/图片/面包屑等一系列信息支持异步加载文章页提取支持上传自定义的HTML代码提取正文支持自动检测网页编码支持自动提取网页全部URL在8个国家13万个新闻类网站进行测试,准确率高达90%提取文章正文12345678910111213141516171819import requestsimport jsonurl = "https://crawler.kingname.info/gne/crawl"body = { "url": "https://www.kingname.info/2023/10/17/rubbish/", "js": False, "charset": "auto"}he..
更多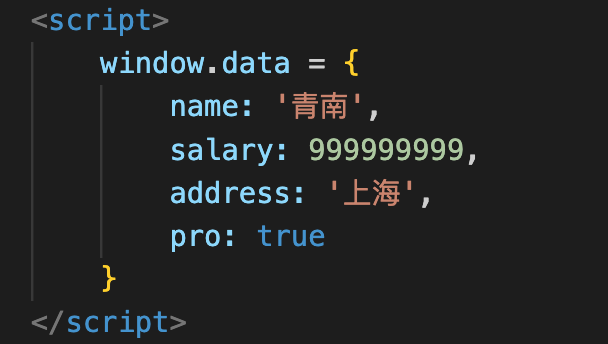
一日一技:爬虫如何解析JavaScript Object?
我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据放到HTML中的<script>标签里面。这些数据长得有点像JSON,但又有差异,如下图所示:这种格式,我们叫做JavaScript Object。长得很像Python的字典,又很像是JSON。但是这个格式在Python里面,无论直接当字典解析,还是当JSON解析,都会报错,如下图所示:遇到这种情况,有同学准备使用正则表达式来解析,又有同学直接放弃。但实际上,这种数据结构,使用Yaml是可以直接解析成Python的字典。我们首先来安装一下Yaml:1pip install pyyaml然后直接像解析JSON一样解析:12345678910import yamldata = '''{ name: '青南', salary: 99..
更多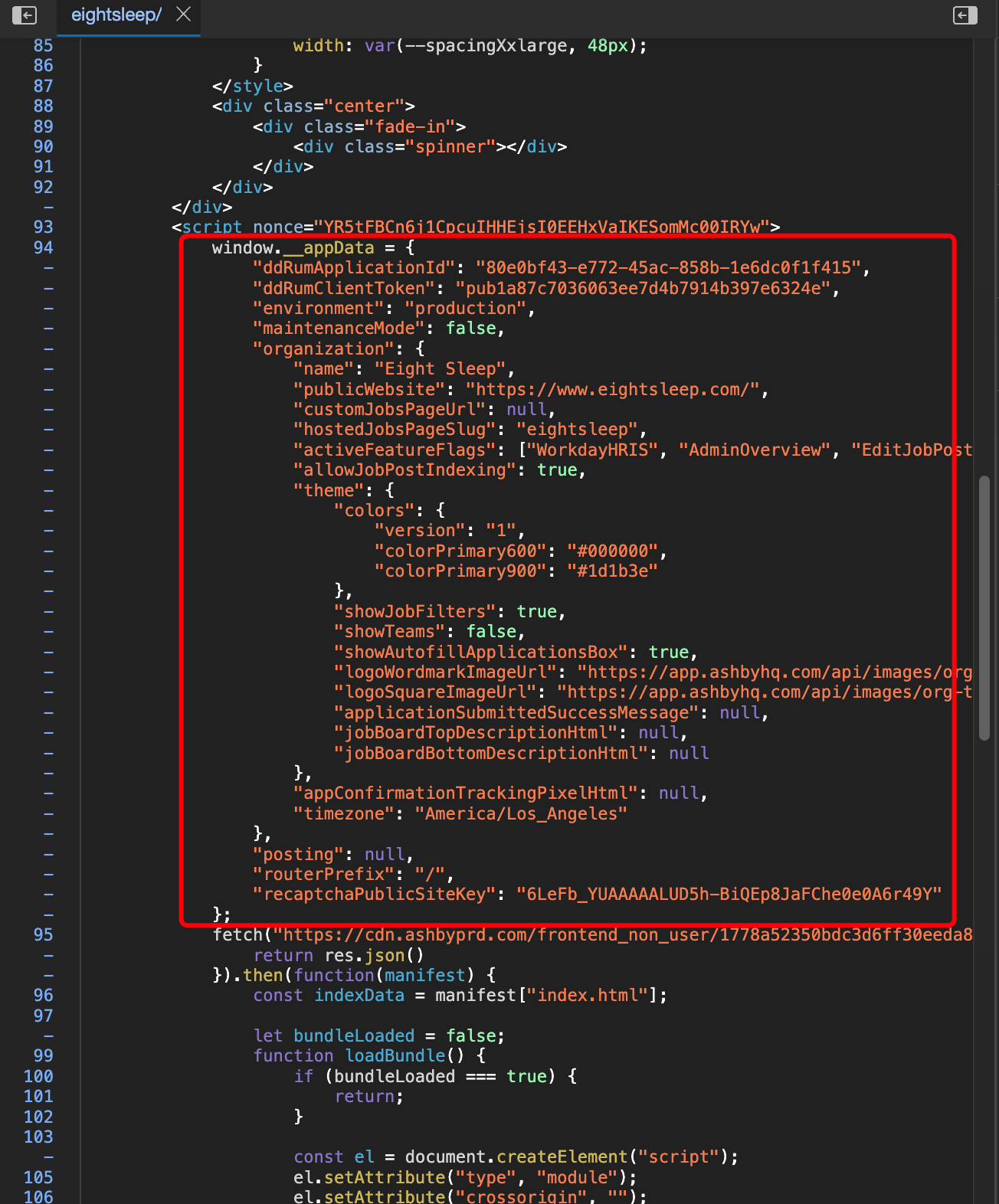
一日一技:HTML里面提取的JSON怎么解析不了?
我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据以JSON的形式,通过<script>标签放到页面源代码中。如下图所示:有时候请求URL拿到HTML的过程比较麻烦,有些同学习惯先把HTML复制到代码里面,先把解析的逻辑写好,然后再去开发请求HTML的代码。这个思路本身是没有什么问题的,于是他们就写了如下的代码:代码中的html_data = '''里面就是原样复制的网页HTML,没有做任何修改,因为太长了,我这里做了折叠。展开以后如下图所示:但当运行这段代码的时候,发现代码报错了,如下图所示:看这个报错信息,难道说是JSON本身有问题?于是,你到网页上,把这个JSON复制下来:使用JSONHero这种验证网站,进行验证,结果发现一切正常:这就见鬼了,为什么正则表达式提取的JSON就不对..
更多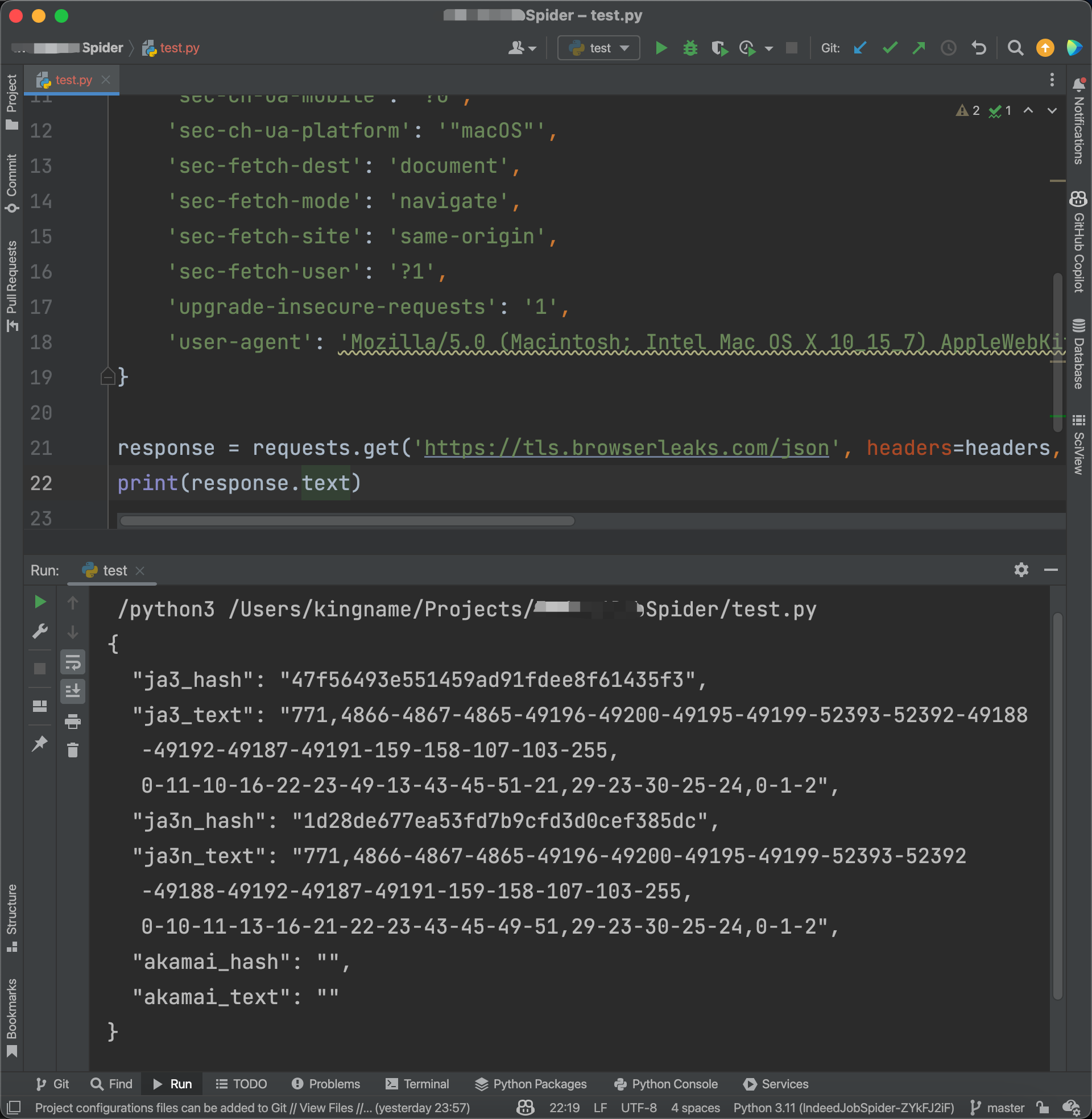
一日一技:Requests被网站识别怎么办?
现在有很多网站,已经能够通过JA3或者其他指纹信息,来识别你的请求是不是Requests发起的。这种情况下,你无论怎么改Headers还是代理,都没有任何意义。我之前写过一篇文章:Python如何突破JA3,但方法非常复杂,很多初学者表示上手有难度。那么今天我来一个更简单的方法,只需要修改两行代码。并且不仅能过JA3,还能过Akamai。先来看一段代码:123456789101112131415161718192021import requests headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/s..
更多一日一技:在Scrapy中如何拼接URL Query参数?
我们知道,在使用Requests发起GET请求时,可以通过params参数来传递URL参数,让Requests在背后帮你把URL拼接完整。例如下面这段代码:12345678910111213# 实际需要请求的url参数为:# https://www.kingname.info/article?id=1&doc=2&xx=3import requestsparams = {'id': '1','doc': '2','xx': '3'}requests.get('https://www.kingname.info/article', params=params)那么在Scrapy中,发起GET请求时,应该怎么写才能实现这种效果呢?我知道很多同学是通过字符串的format操作来拼接URL的:12..
更多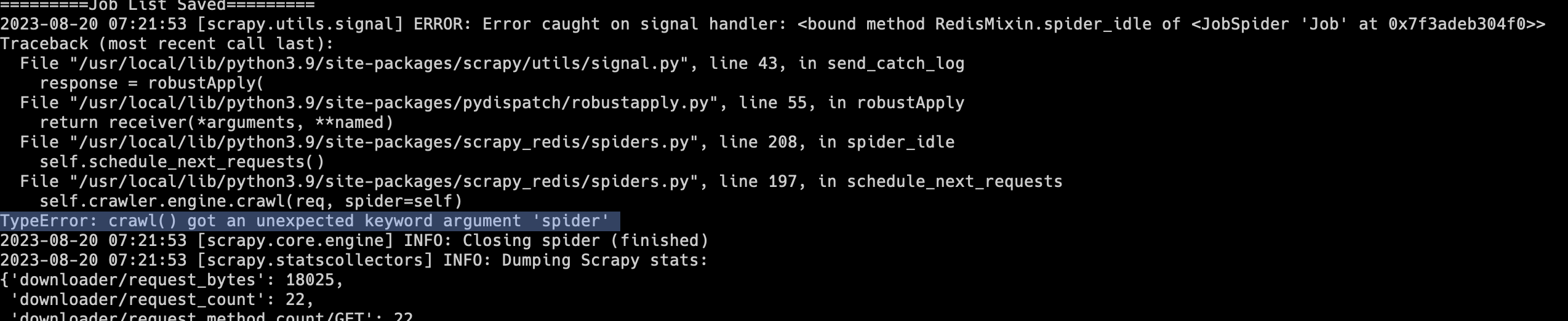
一日一技:Scrapy最新版不兼容scrapy_redis的问题
有不少同学在写爬虫时,会使用Scrapy + scrapy_redis实现分布式爬虫。不过scrapy_redis最近几年更新已经越来越少,有一种廉颇老矣的感觉。Scrapy的很多更新,scrapy_redis已经跟不上了。大家在安装Scrapy时,如果没有指定具体的版本,那么就会默认安装最新版。这两天如果有同学安装了最新版的Scrapy和scrapy_redis,运行以后就会出现下面的报错:1TypeError: crawl() got an unexpected keyword argument 'spider'如下图所示:遇到这种情况,解决方法非常简单,不要安装Scrapy最新版就可以了。在使用pip安装时,绑定Scrapy版本:1python3 -m pip install scrapy==2.9..
更多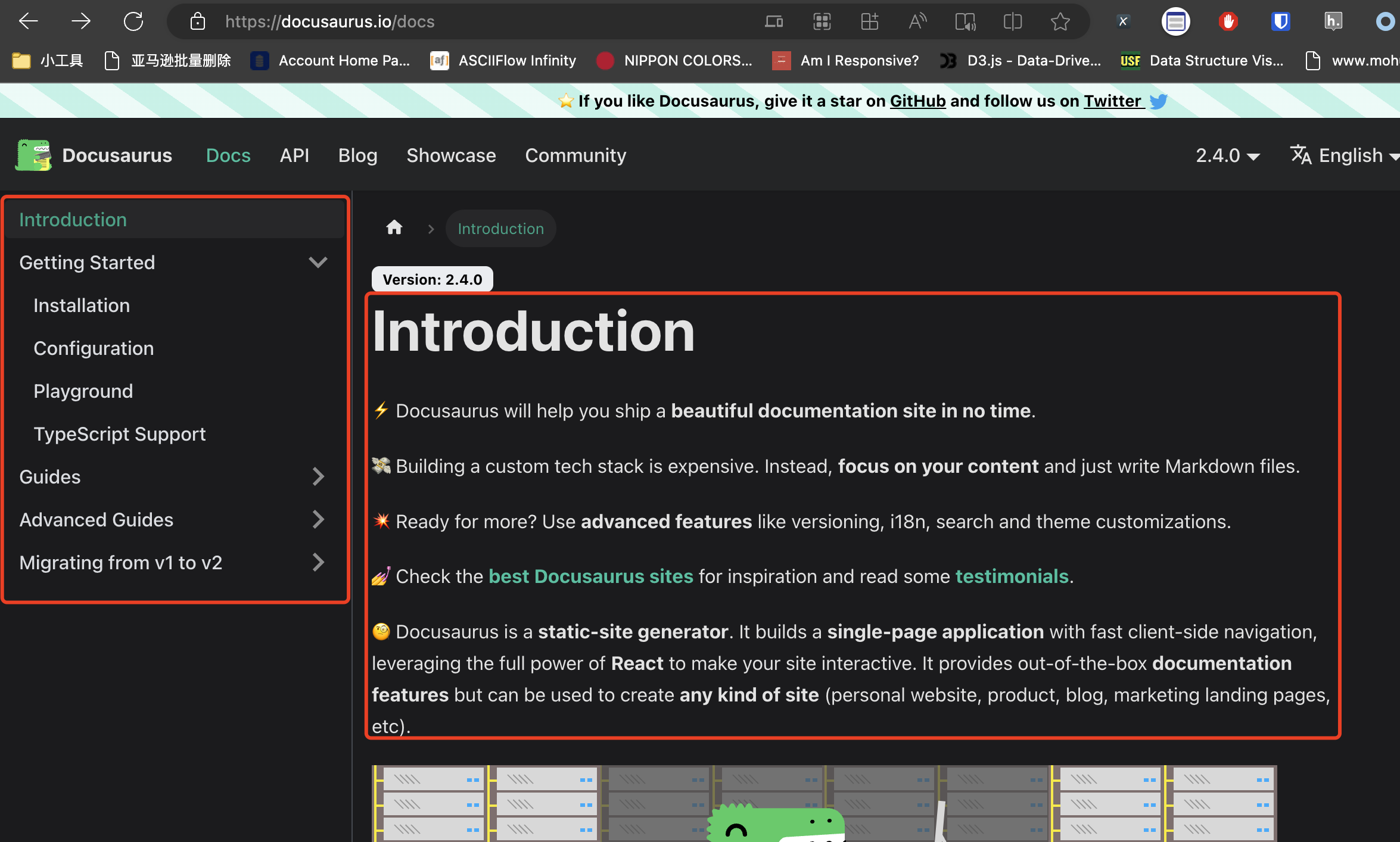
一日一技:不走常规路线,列表页1秒搞定
最近遇到一个需求,需要抓取Docusaurus上面的全部文档。如下图所示:抓文档的正文非常简单,使用GNE高级版,只要有URL直接就能抓取下来,如下图所示:但现在的问题是,我怎么获取到每一篇文档的URL?Docusaurus是一个文档框架,它的页面和目录都是JavaScript实时渲染的。当我们没有展开它的目录时,XPath只能提取到当前大标题的链接,如下图所示:当我们点开了某个大标题,让里面的小标题出现时,XPath能够提取的数据会随之变化,如下图所示:在这种情况下,我们经常使用的爬虫方案,都会遇到阻碍:直接使用Requests获取源代码——源代码里面没有每条目录的URL使用Selenium——直接执行XPath获取不完整。你需要控制Selenium依次点开每个小箭头,才能使用XPath获取到全部的UR..
更多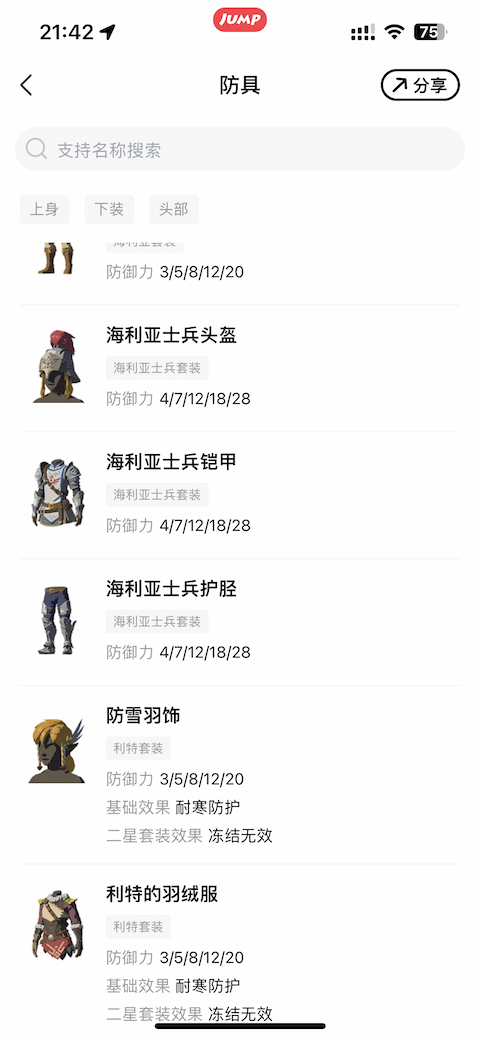
一日一技:iOS抓包最简单方案
写过爬虫的同学都知道,当我们想对App或者小程序进行抓包时,最常用的工具是Charles、Fiddler或者MimtProxy。但这些软件用起来非常复杂。特别是当你花了一两个小时把这些软件搞定的时候,别人只用了15分钟就已经手动把需要的数据抄写完成了。我的需求如果你不是专业的爬虫开发者,那么大多数时候你的抓包需求都是很小的需求,手动操作也不是不能。这种时候,我们最需要的是一种简单快捷的,毫不费力的方法来解放双手。例如我最近在玩《塞尔达传说——王国之泪》,我有一个小需求,就是想找到防御力最大的帽子、衣服和裤子来混搭。这些数据,在一个叫做『Jump』的App上面全都有,如下图所示:防具总共也就几十个,肉眼一个一个看也没问题,就是费点时间而已。那么,如果我想高效一些,有没有什么简单办法通过抓包再加上Python..
更多一日一技:方法不对,代码翻倍。Requests如何正确重试?
程序员是一个需要持续学习的群体,如果你发现你现在写的代码跟你5年前的代码没什么区别,说明你掉队了。我们在做Python开发时,经常使用一些第三方库,这些库很多年来持续添加了新功能。但我发现很多同学在使用这些第三方库时,根本不会使用新的功能。他们的代码跟几年前没有任何区别。举个例子,使用Request发起HTTP请求,请求失败时,不管什么原因,原地重试最多3次。很多人主要有下面3种写法来重试。常见的老方法使用第三方库这类同学会使用一些专业做重试的第三方库,例如tenacity。详见我的这篇文章:Tenacity——Exception Retry 从此无比简单手动写装饰器这类同学会使用装饰器,所以一般会手写装饰器从而复用,例如:123456789101112131415def retry(func): ..
更多