qwen1.8B试玩
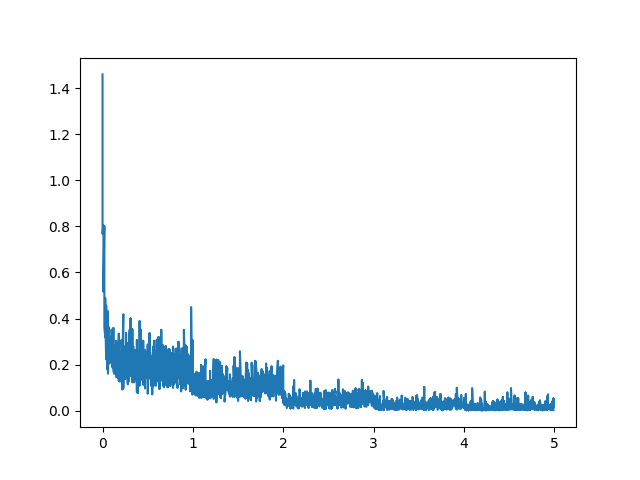
介绍阿里出了个qwen1.8B,对于资源有所要求的场景或者需要支持长文本的场景,应该是目前国内在这个量级内最优的选择了吧。接下来以此来打通微调、部署各个流程,算是一次记录。 微调首先按照要求和快速使用来跑起来,安装flash-attn,先跑下推理,正常,接下来就进入微调阶段。 按照微调流程,这里采用LoRA进行微调,但是需要注意的是,虽然官方给出了显存占用及训练速度,但是我在1080Ti上得到的显存占用还是要更高一些,大家可以将这个指标理解成为运行起来至少需要的显存,在进行训练时,还是会有一些增高。 训练的话采用finetune_lora_single_gpu.sh默认配置,幸亏我没有采用train,而是使用了dev数据集,7500条数据,8个多小时,,不过整个loss还是蛮正常的,没有出现issue里出现的各..
更多ChatGLM微调记录
介绍以ChatGLM-6B ptuning提供的微调代码来进行测试,整体代码在此。 训练和推理训练就直接使用官方代码啦,推理也是滴,整体流程跑通都很顺畅,整体是采用quantization_bit=4,所以单卡(5~6G显存)就能跑的起来。 记录几个有意思的点。 1. p-tuning这个是众多Parameter Efficient fine-tune实现方式之一,其发展历程简单理解有两个阶段,一是人工构造template,二是机器自己学习一个template。 比如一开始做分类,例如“这个沙发怎么样”,那就在这句话前面(当然也可以放到后面)加上一个template,比如情感分析,这个沙发怎么样,你觉得这句话是正向还是负向:这个沙发怎么样,那训练时只对这个template进行微调,因为微调seq_len很少,所..
更多lora原理与实现
介绍Lora,是微软出的一种在低资源场景下进行微调大模型的实现方式,在transformers里有peft这个包进行调用,它通过固定预训练模型权重并只训练新增lora层来实现微调,目前其在比如Baichuan2、ChatGLM上都有相关资料,更多介绍可自行搜索了解。 简单理解其简单理解实现方式为,比如qkv的linear为768*768(更大模型可能会更大),那lora通过新增两个linear(lora_A和lora_B),引入一个超参r来降低训练参数量,其伪代码如下: 1234567891011in_feature, out_feature = 768, 768# oldself.q = nn.Linear(in_feature, out_feature)# Loraself.lora_A = nn.Line..
更多
document-QA-layoutLMv2
介绍书接上文,layoutLM微调FUNSD数据集介绍了layoutlm和layoutxlm如何做named entity recognition,以及多模态-CLIP和多模态-字幕生成介绍多模态是如何融合的,本文继续基于layoutLM系列,基于huggingface document_question_answering来进行debug是如何实现的。 更新:针对layoutxlm在docvqa_zh上的训练代码已经放到document-qa啦。 原始数据在这之前,都是在介绍如何处理数据,也即如下代码: 123456789101112131415161718#from datasets import load_datasetdataset = load_dataset("nielsr/docvqa_1200_..
更多
多模态-CLIP
问题多模态如何做融合,本文是对CLIP模型理解做个记录。 前提目前业界有中文开源版本的,例如Chinese-CLIP以及IDEA/Fengshenbang-LM太乙系列,本文采用Chinese-CLIP来梳理其流程。 数据集采用wukong-dataset,预训练模型使用chinese-clip-vit-base-patch16来进行实验。 流程1. 文本处理1234567891011121314import pandas as pdimport torchfrom PIL import Imagefrom datasets import Datasetfrom transformers import ChineseCLIPProcessor, ChineseCLIPModel, Trainer, Traini..
更多生成式模型相关记录
最近在做生成式模型的一些工作,至今算是能有些总结的了,趁着还有些能记住的地方,赶紧记录下来,后面想到了再补充。 前期调研1. 相关工作目前我们在做的算是业界独创的,搜了一圈,没有相关的工作,所以我把PaddleNLP中generation相关的任务给看了一遍,比如question_generation,用T5预训练模型或unimo-text项目,machine_translation中的transformer部分,对于大致的实现思路以及各自在解码时采用的策略都作了些了解,所以整理实现起来并不复杂。 2. 预训练模型选择这里反而是比较头疼和纠结的地方,从类型选择上有两大类:decoder和encoder-decoder。对于这部分在huggingface course上是怎么解释或者区分的呢,如果你用于文本生成,..
更多
BELLE-使用chatGPT生成训练数据
LoRApefthttps://mp.weixin.qq.com/s/kEGwA_7qAKhIuoxPJyfNuwhttps://aistudio.baidu.com/aistudio/projectdetail/5567217 介绍自从chatGPT出来后,好多人/机构开始尝试使用chatGPT来生成训练数据,简单省事方便。比如google bard,对,就是你,也有在偷偷使用。本文介绍一个项目BELLE,来看看大佬们是怎么做的。注意:此文重点在于如何生成数据。 利用chatGPT生成训练数据最开始BELLE的思想可以说来自stanford_alpaca,不过在我写本文时,发现BELLE代码仓库更新了蛮多,所以此处忽略其他,仅介绍数据生成。 代码入口:generate_instruction_followin..
更多simcse模型
介绍如何使用无监督的方式来判断两个句子的相似度呢?simcse给你答案! 相关资料:中文任务还是SOTA吗?我们给SimCSE补充了一些实验paddleNLP simcse 流程请先看in-batch-negative数据增强这篇文章,模型,推理,所有步骤都不变,就一个地方:构造训练数据集。 train.tsv如下所示: 第一列为query,第二列为doc12如何使用无监督的方式来判断两个句子的相似度呢?simcse给你答案! 如何使用无监督的方式来判断两个句子的相似度呢?simcse给你答案!相关资料 相关资料 query和doc是一模一样的! 那这个模型是如何工作的呢? 分别对同一个句子进行两次dropout,然后判断这两个向量的相似度。 评估评估和in-batch-negative数据增强..
更多in-batch-negative数据增强
介绍这篇文章的思路来源自paddleNLP–>语义检索–>recall–>paddleNLP In-batch negative,它提供了一种非常有特点的数据增强,帮助提升模型训练效果。 任务介绍它是一个语义检索召回阶段任务,输入两个句子s1和s2,判断这两个句子的相似度。 做法0. 数据格式1234我手机丢了,我想换个手机 我想买个新手机,求推荐求秋色之空漫画全集 求秋色之空全集漫画学日语软件手机上的 手机学日语的软件侠盗飞车罪恶都市怎样改车 侠盗飞车罪恶都市怎么改车 注意,每一行的两句话都是相似的。 1. 模型结构123456789101112131415161718192021222324252627282930313233343536..
更多bert向量加权
这个是对bert以首字表示词向量(2)文章的扩充,是对指定span index进行加权。 整体思想来自coreference resolution中#word-level实现demo部分。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657# -*- coding: utf8 -*-#import torchclass WordEncoder(torch.nn.Module): def __init__(self, n_in, p=0.1): super(WordEncoder, self).__init__() sel..
更多