一些mask的操作理解
mask和index在一起操作挺多的,故关于index操作也可以看: 活到老学到老之index操作。 1. 对矩阵获取句子长度123456from torch.nn.utils.rnn import pad_sequencea = [torch.tensor([1,2, 3]), torch.tensor([4,5])]b = pad_sequence(a, batch_first=True)mask = b.not_equal(0)b[mask].split(mask.sum(1).tolist()) 2. 计算loss的时候把mask加上略. 3. 比如三维矩阵操作mask123456789101112131415161718192021222324252627a = torch.arange(24)..
更多
IE-by-generation-t5
引言本文主要分析CCKS 2022 通用信息抽取 – 基于UIE的基线系统代码实现,代码为DuUIE。本文和目前官方在不停推广的UIE稍微不同的是,本文是采用生成式的方式来做信息提取,也是百度最早论文所实现的方式。目前官方推广的是基于片段抽取的提取方式。对于这两者的不同,可参考DuUIE和UIE的对比。 对于官方宣传的UIE的实现,之前代码也有做过分析UIE-事件提取,感兴趣的可以去看看。 通用信息提取目前对于信息提取没有一个非常严格的定义,但是特点是针对不同的事件定义不同schema。针对给定的句子甚者是文章,来完成对应schema信息的提取。 信息提取形式上可分为三类: 1、flat(即每个schema成分都是平铺的,不存在交叉之类的现象)2、nest(一个schema成分也可作为另外一个schema..
更多
layoutLM微调FUNSD数据集
引言对表单、合同、收据等信息抽取、理解,单从NLP角度来做就丧失了一些比较重要的特征,比如排版、位置、字体大小、字体颜色等特征。 如何引入这些特征对于关键信息抽取(Key Information Extraction)就比较重要。 此篇文章围绕FUNSD数据集来进行,尝试在不同的layoutLM模型上实现,以及对比各自的效果。 FUNSD数据集常见的数据集有FUNSD和XFUND,XFUND是一个融合了多语言的训练集,数据更为丰富。不过此处选择FUNSD来进行实验。 FUNSD全称为Form Understanding in Noisy Scanned Documents,直译过来就是嘈杂的扫描文档的表单理解,因为是扫描件,或多或少都会有些噪点的,也可看官网的描述。 数据集地址。 下载数据后,例如data..
更多textrank关键句
引言最近在面试北京技术负责人一位候选者(学校杠杠的)时,他对现在公司的新闻领域做摘要时说准确率能达99%,并且也通过了他们内部验证以及用户的对外展示(这家公司你就可劲想吧)。心里是有点不太相信可以达到这么高,理由: 新闻常见字数成千上万,对于这种情况人的理解也有所差异,但只要摘要中出现核心关键词/句子基本也认可。 对于所用到的无监督的方式(用到了textrank),目前业界的上限在那,同时受限于特征工程。 对于使用生成式模型,比如使用PGN,这类方式就要有标注数据。以及有个问题就是生成文本不可控,这也是目前业界在研究的方向。 用到了textrank,那么句子都是从原文中获得的,那么连续性无法保证,更应该说从原文提取关键句子,代表原文。 之前没做过这方面,就比较好奇怎么实..
更多self-attention解析
更多
单塔文本匹配
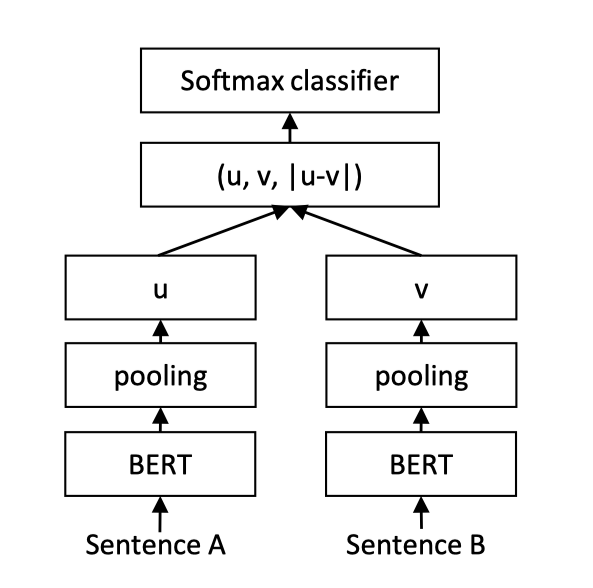
介绍文本匹配是研究两段文本之间的关系。 此处介绍两种,分别是point-wise和pair-wise语义匹配模型。 point-wise是ptm+二分类,判断句子相似度。pair-wise是ptm+score,判断两个句子相似度得分,可用于排序。最近实现了一个,可参考pairwise-match。 粗排方面有sentence transformer以及SimBERT,再比如DSSM。 这些先记下,等后面有时间了再实现总结。 更新关于双塔模型中的sentence transformer,网络结构如下: 其中pooling为比如Sentence的维度为(1,7,768),那么就对7那一维做mean操作。 由于共用同一个pretrained model,将向量提前保存到数据库。当..
更多内容推荐调研
介绍下派一个任务,研究下推荐系统,貌似后面和电信搞一个类似电视视频内容推荐之类的项目. 基于流行度的推荐这个推荐比较简单些,就是根据视频的得分来进行排序,排除掉当前用户已经看过的,剩下的再排序返回给用户就行. 好处是这是一个非常简单但是非常有效的算法,基本来说我们看视频都是根据播放量高、得分高进行播放。坏处是有一个长尾效应,过于小众的基本不会推荐出来,看看京东,其实也有点类似这样~ 关于视频的打分,这个可以根据一些特征工程来获得,比如用户点赞,收藏,喜欢,浏览,基于不同权重进行得分。如果没有这些特征,可以手动构造这些视频的得分(不行可以抓豆瓣。。。)甚者直接根据用户的浏览记录进行排序就能上线。 对于长尾效应,可以运营分出几大类,根据类别再进行排序也是可以一定程度多了新的选择..
更多
求合理路径
今天在群里看到有人问了这么一道题,如下图所示。瞬间让我大呼这不就是我之前想出的一道面试题么,不过有可能是我当时没有表达清楚,发现小伙伴们理解的不是很透彻。 那我的方法就是基于每个元素的position,构成一个有向图即可。 代码如下(也方便未来自己再重新写😂) 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869# -*- coding: utf8 -*-#import mathfrom typing import Listdef trace_path(vec, pathes): if not..
更多图算法基础知识概览
分享一篇文章,这篇文章对图算法做了一个概览,主要分成三块: 路径搜索(DFS、BFS、prime tree, Dijkstra, ranom rank) 中心性计算(度中心性,紧密性中心性,pagerank) 社群发现(聚类,等) 同样更推荐《算法》,是一本系统完备的书,不管从工程还是算法角度都很适合。
更多联邦学习介绍与分享
最近应宋总提议,给各个部门的老大介绍联邦学习。 点进去可以正常显示,此处可能是hexo-pdf插件问题 把他们问的问题再记录下: 领导A关注是共同富裕,比如大企业不愿意跟小企业玩。 领导B只关注自己问问题,解决当下的问题。 领导C在数据融合那里(横向、纵向)问了迁移学习问题。 其他比如标注和不标注的问题,安全问题,联合模型是否能反推出他人数据。 整体下来我觉得没有达到预期的最大的问题是在规则和样本那里,还有就是可能我写的还是太复杂了😂😂😂。 所以还是把这个记录下来,当我某天站在另外一个高度时再回过头来看下,可能会有新的理解。
更多