prompt系列-OpenPrompt入门一
介绍此次开辟一个新的话题,叫做prompting learning。prompting learning常用于零样本、小样本领域,通过将下游训练数据转换成预训练模型任务,进行小样本微调或者零样本进行预测。 之前在UIE-事件提取中也有涉及prompt,但是UIE的做法是构造prompt输入,再和原句一起微调模型,完成提取任务。那这里我们来看看OpenPrompt是怎么做的。 关于OpenPrompt,此处不做过多介绍,请直接看官网。 官方有张图阐述了OpenPrompt的架构,请看下图。 下面通过官方示例来说明它的工作原理。 主要模块介绍1. Template这个从网上一搜prompting learning,不可避免搜到template,这个是将下游训练数据通过template转换成符合预训练模型任务的..
更多UIE-情感分类
引言在上一篇文章UIE-事件提取中,介绍了doccano的用法,也介绍了基于prompt事件提取的做法。本篇文章继续介绍基于prompt情感分类的做法。 数据标注关于doccano使用,请看构建分类式任务标签和句子级分类任务。标注完成后生成下面文件。 doccano_txt.json 12{"id": 7, "data": "这个产品用起来真的很流畅,我非常喜欢", "label": ["正向"]}{"id": 8, "data": "这个产品非常low", "label": ["负向"]} 使用句子级分类任务数据转换转换后,生成的样本如下所示: train.txt 1{"content": "这个产品用起来真的很流畅,我非常喜欢", "result_list": [{"text": "正向", ..
更多UIE-实体识别
引言这是关于UIE的第三篇文章,但是呢,我更倾向上一篇是UIE-事件提取,因为UIE-情感分类做法上和本篇关系不大。 本篇文章继续介绍基于prompt实体识别的做法。 数据标注如果你看懂了UIE-事件提取的做法,那这里也是同一类任务,都是属于抽取式任务项目。 doccano_txt.json 12{"id": 11, "data": "2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!", "label": {"entities": [{"id": 45, "start_offset": 0, "end_offset": 6, "label": "时间"}, {"id": 46, "start_offset": 24, "end_offset": 31, "lab..
更多UIE-跨任务抽取
引言关于跨任务抽取,搜了圈没发现准确定义的,有介绍多任务的,有介绍prompt来做多任务的。 所以此处暂不纠结具体细节了,看下paddleNLP UIE怎么做的。 训练关于数据标注,官方没有给具体的方式,那么就从推理的角度来看是怎么实现的。 推理官方代码: 12345678from paddlenlp import Taskflow# 跨任务抽取schema = ['法院', {'原告': '委托代理人'}, {'被告': '委托代理人'}]ie = Taskflow('information_extraction', schema=schema)ie.set_schema(schema)print(ie("北京市海淀区人民法院\n民事判决书\n(199x)建初字第xxx号\n原告:张三。\n委托代理人李..
更多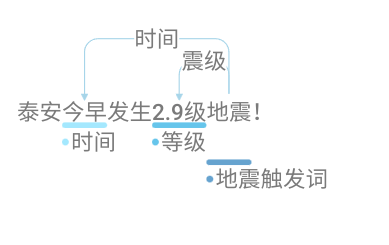
UIE-事件提取
引言此篇文章分析paddlenlp中universal information extraction(UIE)对于事件提取的实现方式。 后续在没有特殊声明的情况下,UIE均代表paddlenlp的实现方式。 在这篇文章产业级信息抽取技术开源,为什么Prompt更有效? 中,作者突出UIE的优势: 多任务统一建模 零样本抽取和少样本快速迁移能力(基于Prompt的信息抽取) 而上述两点,基本也突出了目前深度学习算法的几个问题: 一、多任务统一建模 每个模型的建模方式都不同,希望在decoder(bert外的layers)更有效简单的解决问题。encoder(bert)端更多利用具备更深层次语义表达能力。 目前国内外也在研究这种多任务统一建模,在一个模型中输入不同的schema来得到相应的问题解。..
更多
讯飞2020年事件提取比赛第一名-主客体提取
引言这是第二篇文章,因为主客体提取需要依赖触发词识别。上一篇是讯飞2020年事件提取比赛第一名-触发词提取。 1. 跑通代码123456789101112131415161718192021args = TrainArgs().get_parser()args.gpu_ids = '0'args.mode = "train"args.raw_data_dir = './data/final/raw_data'args.mid_data_dir = './data/final/mid_data'args.aux_data_dir = "./data/final/preliminary_clean"args.bert_dir = '/home/yuzhang/PycharmProjects/xf_event_..
更多bert融入外部特征
引言此文不是对预训练模型融入实体信息、知识图谱等类似ERNIE,k-bert这种,而是在拿到bert输出后,突出指定位置信息进去,从而控制判定的结果。 问题比如这句话: 该报还报道,法国达能集团日前宣布将投资1亿欧元,加强在中国市场的奶粉生产和研发,并表示“我们对中国市场的长期增长能力充满信心”。 谁加强和谁表示呢?是法国达能集团,而不是该报。 主体 触发词 客体 法国达能集团 加强 在中国市场的奶粉生产和研发 法国达能集团 表示 “我们对中国市场的长期增长能力充满信心” 那假设,我们在知道触发词和客体的情况下,如何从原句中获取主体呢? 思路1. 引入其他layer和bert进行concat这怕是最容易想到的方法了。比如将句子、触发词和客体分别输入到bert,然后将这三者con..
更多活到老学到老之index操作
快速想一想,你能想到torch有哪些常见的index操作?? 1. gather12345>>> a = torch.tensor([[1, 2, 3], [4, 5, 6]])>>> a.gather(dim=1, index=torch.tensor([[0,1], [1,2]]))tensor([[1, 2], [5, 6]]) 2. index_select123456>>> atensor([[1, 2, 3], [4, 5, 6]])>>> a.index_select(dim=1, index=torch.tensor([1,2]))tensor(..
更多最大堆的原理与实现
基本原理最大堆是一个二叉树,要求这个二叉树的父节点大于它的子节点,同时这个二叉树是一个完全二叉树,也就是说这个二叉树除了最底层之外的其它节点都应该被填满,最底层应该从左到右被填满。显然,最大堆的顶部节点的值是整个二叉树中最大的。我们使用数组来构建一个最大堆,使用数组构建一个二叉树最大堆存在如下性质。假设二叉树某节点在数组中的下标索引为index,则它的父节点在数组中的下标索引为parent = (index - 1) // 2,它的左子节点的下标索引为child_left = index * 2 + 1,右子节点的下标索引为child_right = index * 2 + 2。如果计算出来parent小于0或者child大于了数组最大值,就说明没有父节点或者子节点。代码实现接下来我们创建最大堆类,存储一..
更多
简单了解一下动态规划
动态规划是一种求最优解的方式,个人了解也不是很深,胡乱写写,算是一点点自己的理解,有不对的地方欢迎批评。动态规划是一种在多个状态间进行转移时,由上一个最优状态推导出下一个最优状态的方式,而上一个最优状态又是由上上个最优状态推导得到的,如此不断向前推进,最后我们只需要知道初始最优状态即可。通过初始最优状态和状态间转移的逻辑和方式,我们就能获得全局最优状态。(是不是感觉有点像数学归纳法?)举一个斐波拉契数列的例子,最简单的解法自然是使用递归实现123456def fab(n): if n == 0: return 0 if n == 1: return 1 return fab(n - 1) + fab(n - 2)简单分析就可以发现,以上例子中,很多的数字被重复..
更多