
一日一技:如何正确修复有异常的JSON?
当我们使用大模型生成JSON,或者爬虫抓取数据时,可能会遇到一些有异常的JSON,例如:括号不闭合1{"profile": {"name": "xx", "age": 20}没有引号1{name: 青南, age: 20, salary: "99999999, }反斜杠异常1{"name": "青南", "age": 20, "salary: "\"very big\\""}Python的json模块解析这些有问题的JSON时就会报错。这个时候,可以使用一个叫做json-repair的第三方库来解决问题。使用pip就可以安装json-repair。导入以后,就可以像json.loads一样使用了,运行效果如下图所示:对于双引号异常和反斜杠异常,也能正常解析:字符串型的Python字典,也能正常解析,如下图..
更多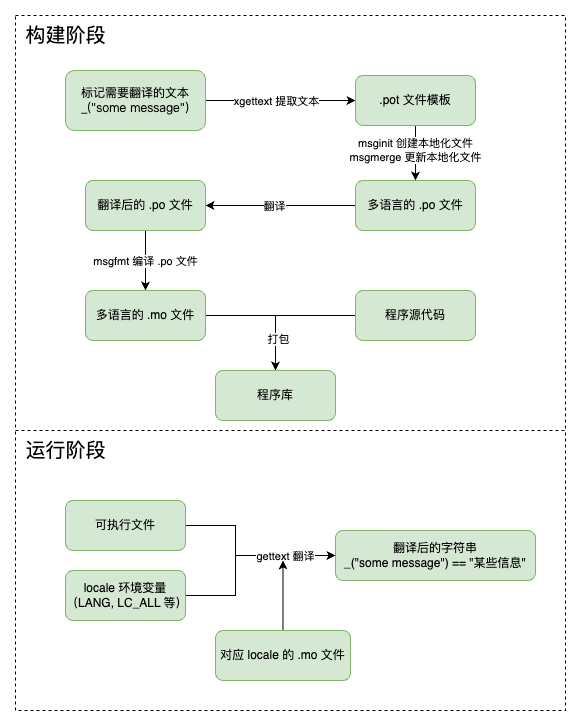
为 Python 项目提供多语言支持
突发奇想,给自己的 beancount-bot 接入了多语言支持。本文简单记录了接入和使用的流程。 在很久很久以前,我曾经在 Django 中使用过多语言支持,但还未尝试过使用底层框架为任意项目提供多语言支持。正巧昨天想将最近开源的 beancount-bot 推荐给 awesome-beancount 项目,而之前的所有文本几乎都是用中文写的。于是,我打算为它提供多语言支持,顺便学习一下 gettext. 背景 在企业中,我们通常将涉及到多语言的工作称为“国际化”工作,但提到相关领域,我们通常绕不开两个意思相近的词:国际化(internationalization,缩写为 i18n)和本地化(localization,缩写为 l10n)。 按照我的理解,国际化工作更偏向框架层面,旨在为程序提供支持多..
更多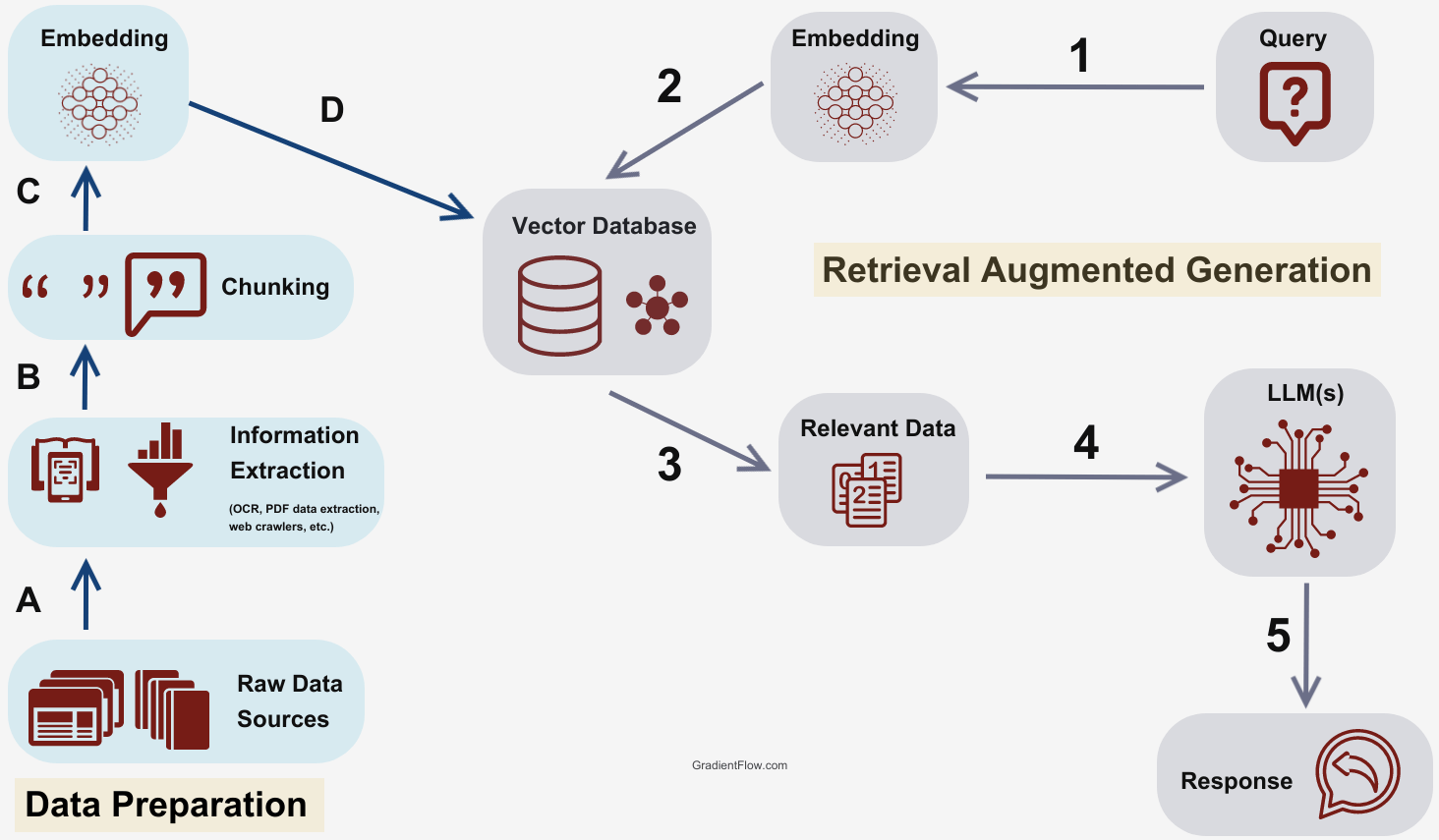
RAG 基本应用——Beancount 记账效率优化
本文来自于一个手工记账博主的脑洞大开,尝试通过向量数据库和 RAG 来想办法让自己少打几个字。顺便宣传一下最近开源的记账 bot. 背景 自从 2020 年将记账系统迁移到 Beancount 后,我就开发了一个 Telegram Bot 来辅助我记账。通过它,我可以使用 {金额} {流出账户} [{流入账户}] {payee} {narration} [{tag1} {tag2}] 的文法来快速生成一条交易记录并落库。虽然后来将这个 Bot 迁移到了 Mattermost 上,但四年以来,核心逻辑并没有做任何改动。 最近经常骑车去打球,每次骑完车之后总需要掏出手机去记账,输入诸如 1.5 支付宝 哈啰单车 自行车 的文本。虽然已经手动记账记了七年,但完全相同的内容记得次数太多了,也难免会有些枯燥。 ..
更多
一日一技:如何正确保护Python代码
去年我写过一篇文章《一日一技:如何对Python代码进行混淆》介绍过一个混淆Python代码的工具,叫做pyminifier,这个东西混淆出来的代码,咋看起来有模有样,但仔细一看,本质上就是变量名替换而已,只要耐下心来就能看懂,如下图所示:而我今天要介绍另一个工具,叫做pyarmor。pyminifier跟它比起来,就跟玩具一样。pyarmor使用pip就可以安装:pip install pyarmor。pyarmor是一个收费工具,但免费也能使用。免费版有绝大部分功能,加密小的脚本足够了。我们今天要测试的脚本如下图所示:运行以后如下图所示:现在,执行命令pyarmor g json_path_finder.py。对这个脚本进行加密,会在dist文件夹中生成加密后的文件,如下图所示:加密后的文件打开以后长..
更多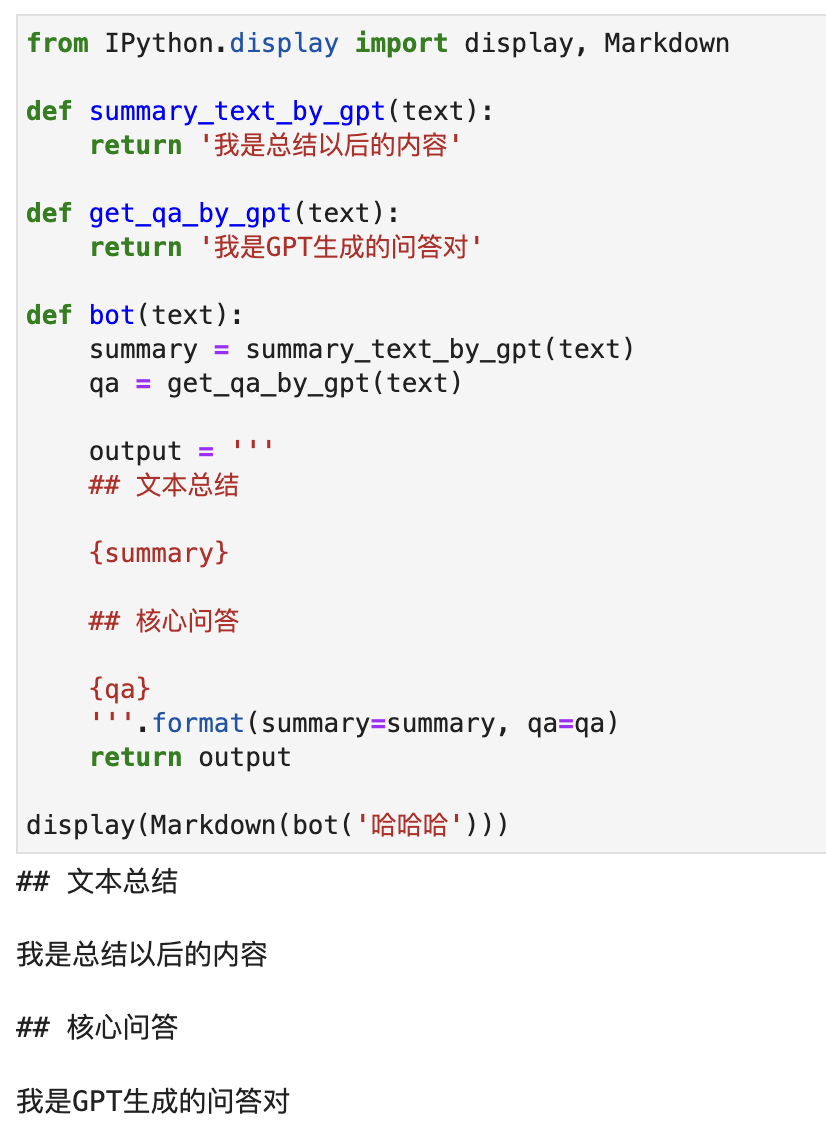
一日一技:如何正确处理多行字符串的缩进问题
有时候,我们需要使用多行字符串配合format格式化函数来生成Markdown文本。例如,我现在开发了一个AI对话机器人,我发送一个txt文件过去,他首先帮我总结整个文件的内容,然后以问答的形式列出10个要点。你的代码可能是这样写的:1234567891011121314def bot(text):summary = summary_text_by_gpt(text)qa = get_qa_by_gpt(text)output = '''## 文本总结{summary}## 核心问答{qa}'''return output返回Markdown以后,通过前端渲染出正常的文本。但如果你直接这样写,你会发现Markdown的渲染好像出问题了。如下图所示:为什么会出现这个问题呢?其实很简单,因为你的Markdow..
更多
一日一技:为什么这个JSON无法解析?
我们知道,Python里面,json.dumps是序列化操作,json.loads是反序列化操作。当我使用json.dumps把一个字典转换为字符串以后,也可以使用json.loads把这个字符串转换为字典。那么,有没有可能出现这样的情况:某个字典,使用json.dumps转换成了字符串s。但是当我使用json.loads(s)时,却会报错?你别不信,我们来做一个实验。执行下面这段代码,打印出一段JSON字符串:12345678910111213import jsontext = '''## 摘要这篇文章主要包含xx和yy## 详情1. abc2. def'''item = {'title': '关于abc', 'raw': text}output = json.dumps(item, ensure_as..
更多
一日一技:setup.py里面的两个小技巧
当你要自己发布一个Python包时,下面这两个小技巧可能对你有用。pip安装后执行代码今天公众号粉丝群里面,有同学提问:这个同学自己开发了一个Python包,这个包在使用pip安装时,会产生一些临时文件。他希望安装完成以后,能够自动清理这些临时文件。要实现这个需求,可以使用Python自带的setuptools来实现。代码如下:12345678910111213141516171819202122import osfrom setuptools import setup, find_packagesfrom setuptools.command.install import installclass CustomInstallCommand(install): """自定义安装命令,执行标准安装后跟..
更多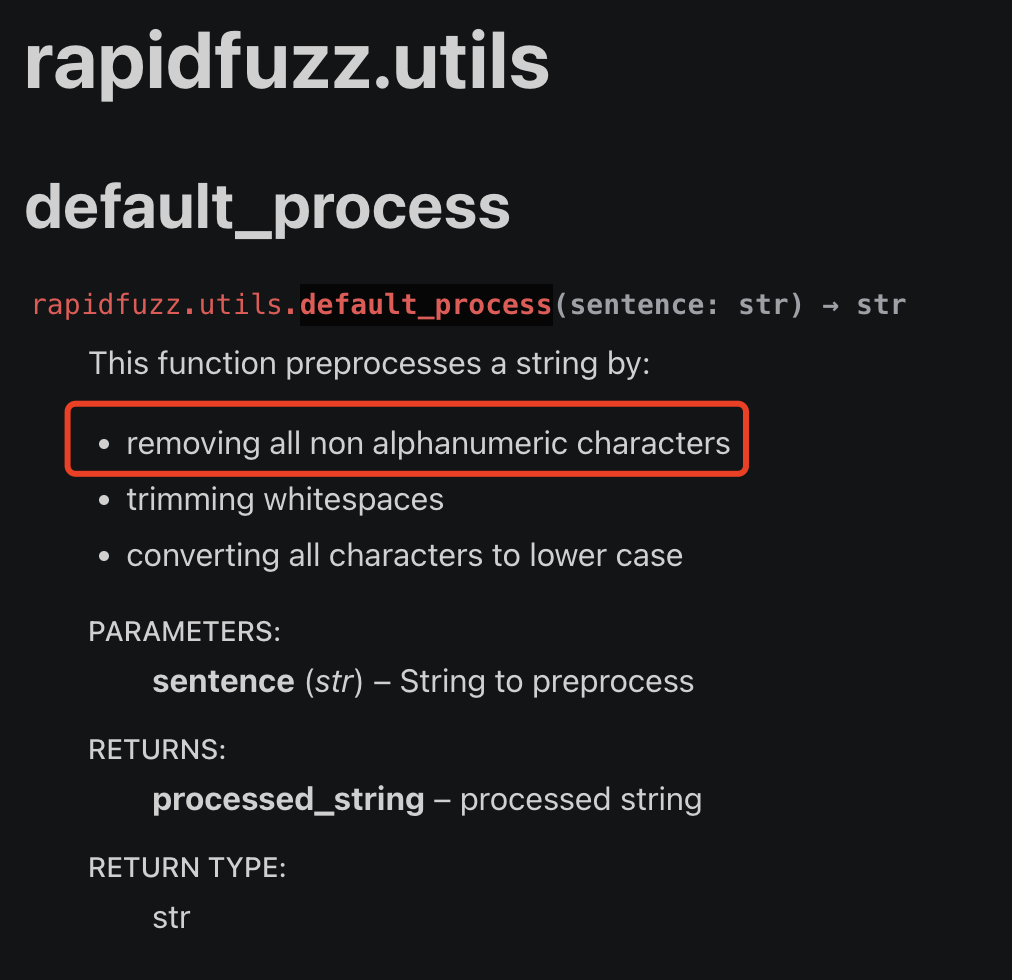
一日一技:怎么中文也属于字母?
我最近在使用一个第三方库,叫做RapidFuzz。它有一个工具函数,叫做utils.default_process,在官方文档里面,是这样介绍的:红色方框里面说,这个函数可以移除所有的非alphanumeric字符。如果我们使用翻译软件,会发现alphanumeric的意思是字母和数字。如下图所示:因此,我想当然的觉得,这个功能函数,只会保留26个英文字母的大小写加上10个数字,一共62个字符。把除此之外的所有其他字符都移除掉。但我经过测试,它竟然没有办法过滤掉中文字符,如下图所示。难道终于也属于字母?于是我到Github上面去给这个项目提Issue。但作者却说这个函数没有问题,并且使用Python的.isalnum()来做测试,发现Python也会认为中文也是alphanumeric。如下图所示:这就非..
更多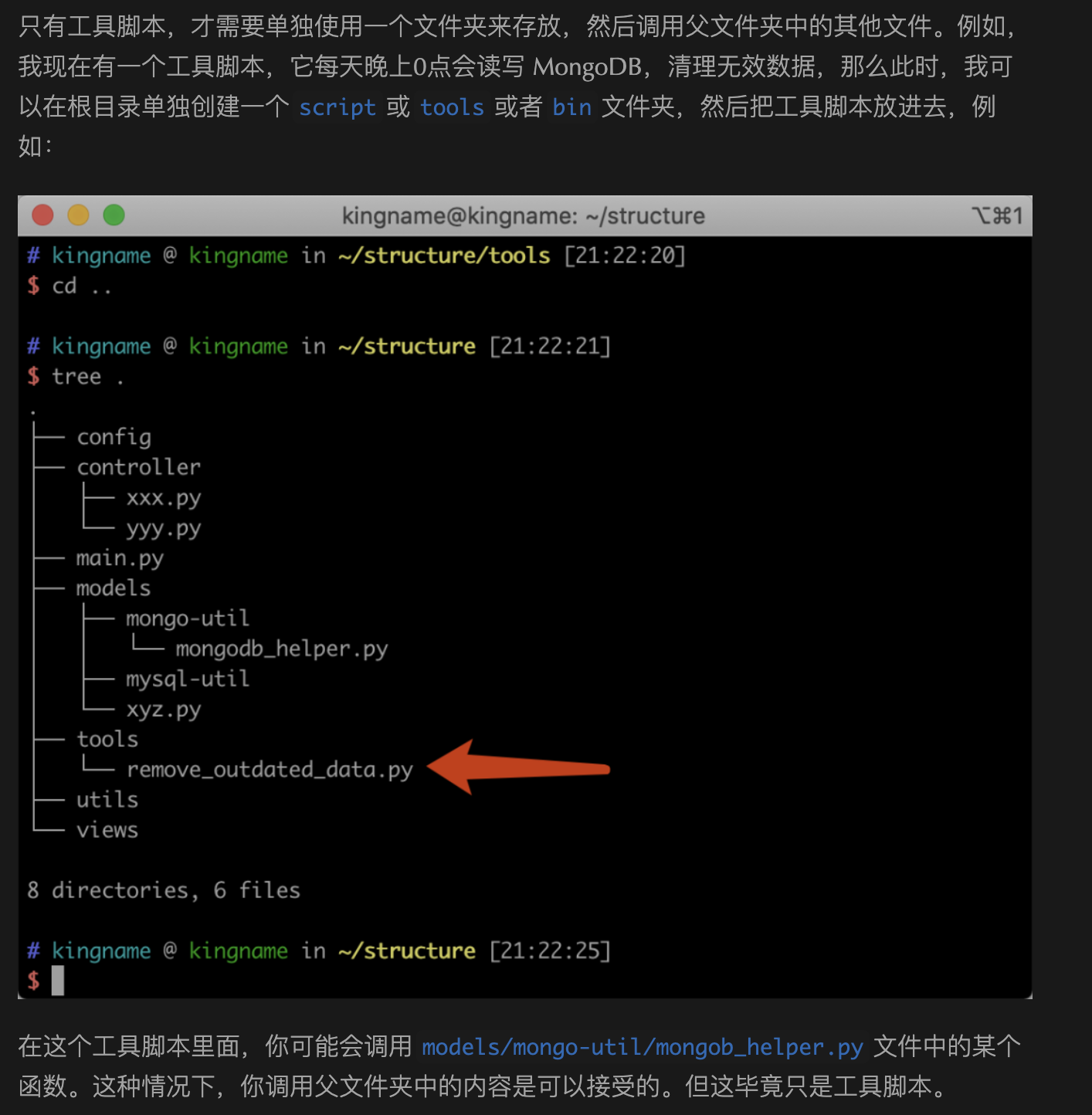
一日一技:Python工具脚本如何调用外层模块
我三年前写过一篇文章:《小问题大隐患:如何正确设置 Python 项目的入口文件?》。讲到Python项目应该如何正确组织代码结构。入口文件应该在最外面,调用关系应该是从外向内调用。而不要学Java,从一个很深层的文件夹里面往外调用。不过我在这篇文章的最后,也提到了一种例外情况,那就是工具脚本不受这个规则的限制。如下图所示。今天有同学在问我,这种情况应该怎么调用,才能让remove_outdated_data.py正确导入models里面的模块。我们今天就来说明一下。首先,我们来创建一个示例程序,结构如下图所示:其中,aa.py文件的内容为:12def i_am_func(): print('我是一个函数')test.py文件的内容为:1234from models.aa import i_am_f..
更多
一日一技:iOS下的开源免费消息推送服务
我们在部署代码到线上以后,可能会需要在一些情况下给自己发报警通知。如果是公司的线上业务,一般会有公司内部的各种通知工具。但如果是自己的个人服务,我们应该怎么推送消息呢?有些同学可能使用过叮叮或者飞书机器人,但是这些机器人要发送通知还需要拉个群,稍微有点麻烦。有些同学可能使用的是Telegram,但使用它需要梯子也不太方便。如果你的手机是iPhone,那么你可以使用一个开源免费超级轻量级的消息推送服务:Bark.使用Bark只需要简单调用接口即可给自己的iPhone发送推送。它只依赖苹果APNs,及时、稳定、可靠。不会消耗设备的电量, 基于系统推送服务与推送扩展,APP本体并不需要运行。能够使用点对点加密,实现隐私安全,确保即使是Bark的开发者在内的所有人都无法窃取你的隐私。使用Bark非常简单,首先在A..
更多