
GnePro:文章类通用爬虫接口
GnePro是开源项目GNE的付费版,能够实现如下功能:输入任意文章页面的URL,返回标题/作者/正文/发布时间/图片/面包屑等一系列信息支持异步加载文章页提取支持上传自定义的HTML代码提取正文支持自动检测网页编码支持自动提取网页全部URL在8个国家13万个新闻类网站进行测试,准确率高达90%提取文章正文12345678910111213141516171819import requestsimport jsonurl = "https://crawler.kingname.info/gne/crawl"body = { "url": "https://www.kingname.info/2023/10/17/rubbish/", "js": False, "charset": "auto"}he..
更多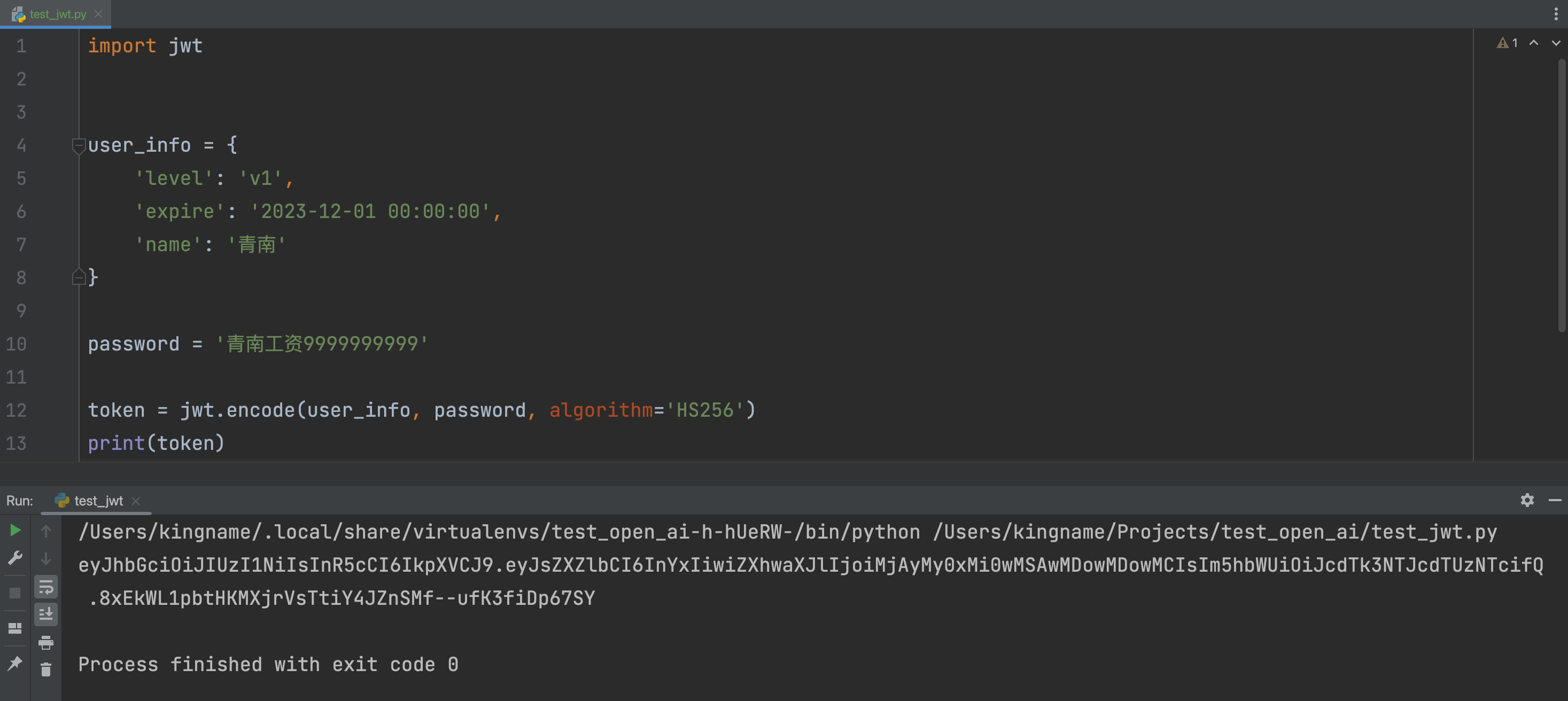
一日一技:分布式系统的低成本权限校验机制
经常关注未闻Code的同学都知道,我做了一个叫做GNE的开源项目,它能够自动提取新闻类网页的正文。效果远远好于市面上其他的开源新闻提取工具。大家可能不知道,GNE还有一个高级版,叫做GnePro。它可以让你输入URL就自动提取新闻的正文,提取的字段比GNE多得多。并且已经在8个国家13万个网站上做过测试,识别准确率100%。GnePro是使用K8S搭建的爬虫集群。背后有几十台服务器,通过一个网关做负载均衡。在设计GnePro权限机制的时候,我希望它能够尽量简单,尽量不依赖第三方的组件。常规的权限校验机制一般是这样的,用户登录以后,在Cookies里面会有一个SessionId.当用户要查询数据时,往后端发起请求。后端从请求中拿到这个SessionId,到Redis或者其他数据库中,查询到这个用户的Sess..
更多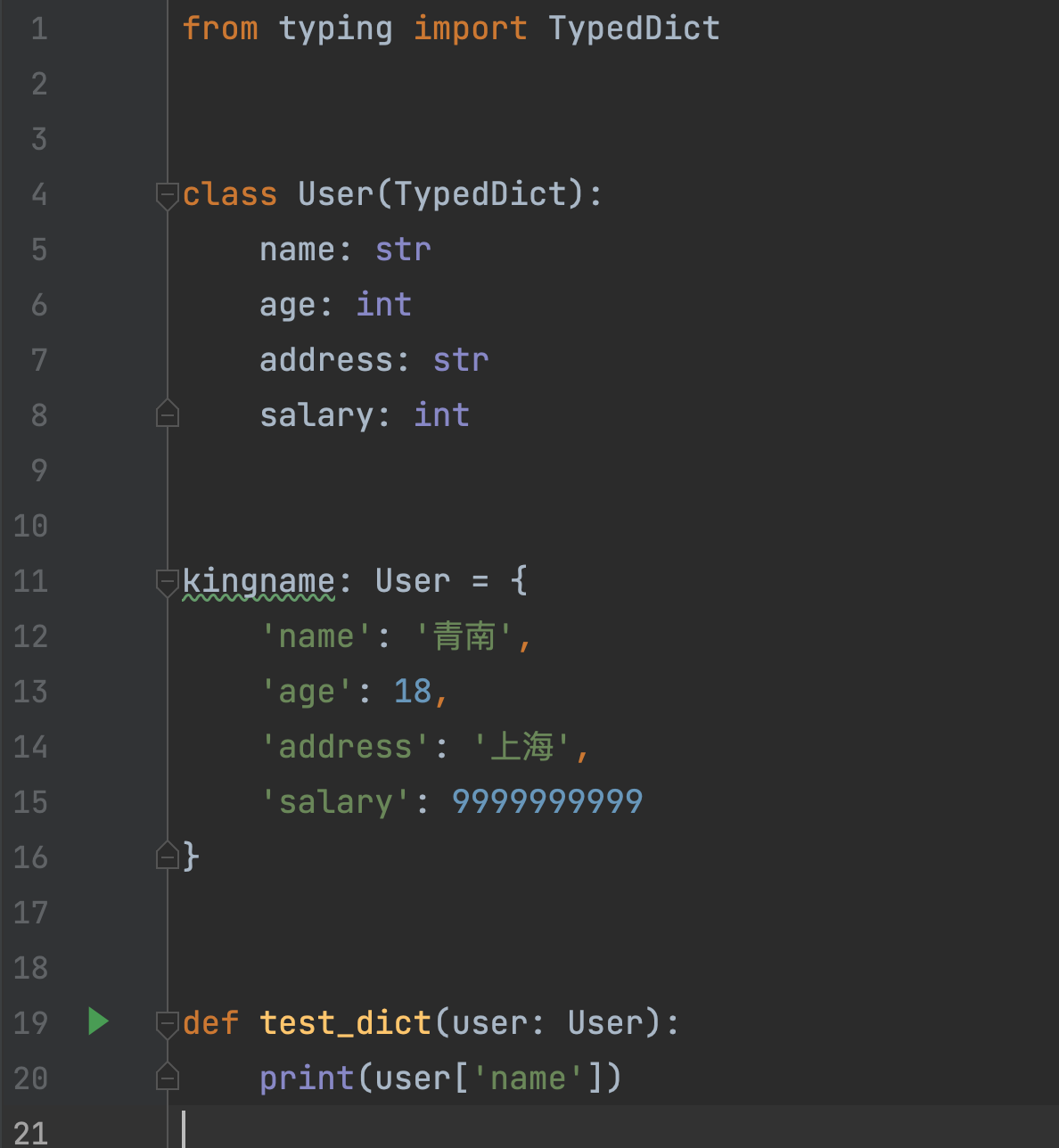
一日一技:警告但不禁止,遗留代码的优化策略
在之前的多篇文章中,我都反复告诫大家,不要滥用字典来传大量数据。因为当你的函数收到一个字典的时候,你根本不知道这个字典里面有哪些Key,你必须有一层一层往上看,找到所有尝试往字典里面添加新Key的地方,你才能知道它总共有哪些Key。但是,在正常公司项目中,我们可能会需要维护一些历史遗留代码。代码规模大,函数调用层级非常深。并且之前的人已经使用字典来传递了大量的数据。短时间内,我们没有办法直接把字典改成Dataclass。那么我们能做的,就是尽量避免后续的维护者往里面加入新的Key。我以前遇到过一个项目,它有一个字典,刚刚开始初始化的时候,只有5个Key。这个字典作为参数被传入了很多个函数,每个函数都会往它里面加很多个Key。到最后,这个字典里面已经有40多个Key了。对历史遗留代码的修改,必须要谨小慎微,..
更多一日一技:如何安全运行别人上传的Python代码?
写后端的同学,有时候需要在网站上实现一个功能,让用户上传或者编写自己的Python代码。后端再运行这些代码。涉及到用户自己上传代码,我们第一个想到的问题,就是如何避免用户编写危险命令。如果用户的代码里面涉及到下面两行,在不做任何安全过滤的情况下,就会导致服务器的Home文件夹被清空。12import osos.system('rm -rf ~/*')有人想的比较简单,直接判断用户的代码里面有没有os.system、exec、subprocess……这些危险关键词不就可以了吗?这种想法乍看起来没有问题,但细想下,就会发现非常天真。如果用户的代码像下面这样写,你又要如何应对?123456789import requestscode = requests.get('https://www.kingname.in..
更多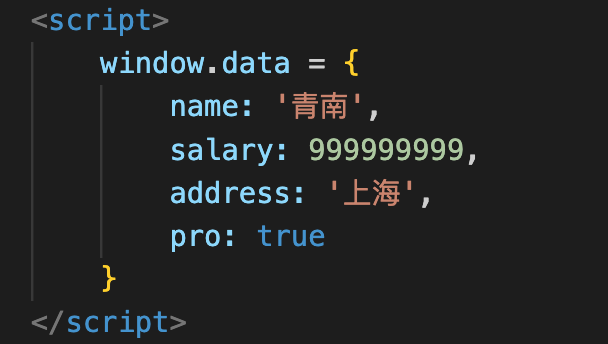
一日一技:爬虫如何解析JavaScript Object?
我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据放到HTML中的<script>标签里面。这些数据长得有点像JSON,但又有差异,如下图所示:这种格式,我们叫做JavaScript Object。长得很像Python的字典,又很像是JSON。但是这个格式在Python里面,无论直接当字典解析,还是当JSON解析,都会报错,如下图所示:遇到这种情况,有同学准备使用正则表达式来解析,又有同学直接放弃。但实际上,这种数据结构,使用Yaml是可以直接解析成Python的字典。我们首先来安装一下Yaml:1pip install pyyaml然后直接像解析JSON一样解析:12345678910import yamldata = '''{ name: '青南', salary: 99..
更多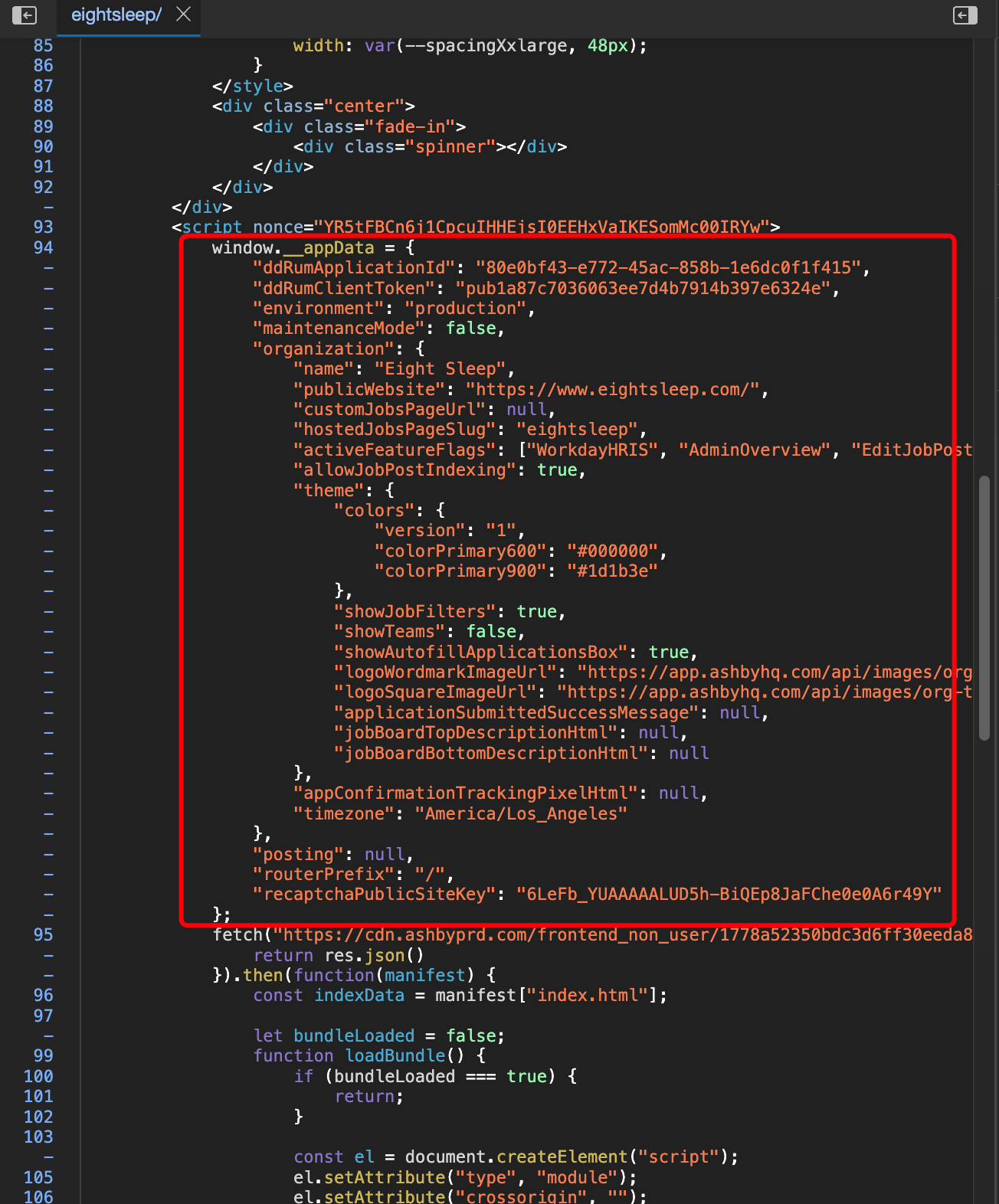
一日一技:HTML里面提取的JSON怎么解析不了?
我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据以JSON的形式,通过<script>标签放到页面源代码中。如下图所示:有时候请求URL拿到HTML的过程比较麻烦,有些同学习惯先把HTML复制到代码里面,先把解析的逻辑写好,然后再去开发请求HTML的代码。这个思路本身是没有什么问题的,于是他们就写了如下的代码:代码中的html_data = '''里面就是原样复制的网页HTML,没有做任何修改,因为太长了,我这里做了折叠。展开以后如下图所示:但当运行这段代码的时候,发现代码报错了,如下图所示:看这个报错信息,难道说是JSON本身有问题?于是,你到网页上,把这个JSON复制下来:使用JSONHero这种验证网站,进行验证,结果发现一切正常:这就见鬼了,为什么正则表达式提取的JSON就不对..
更多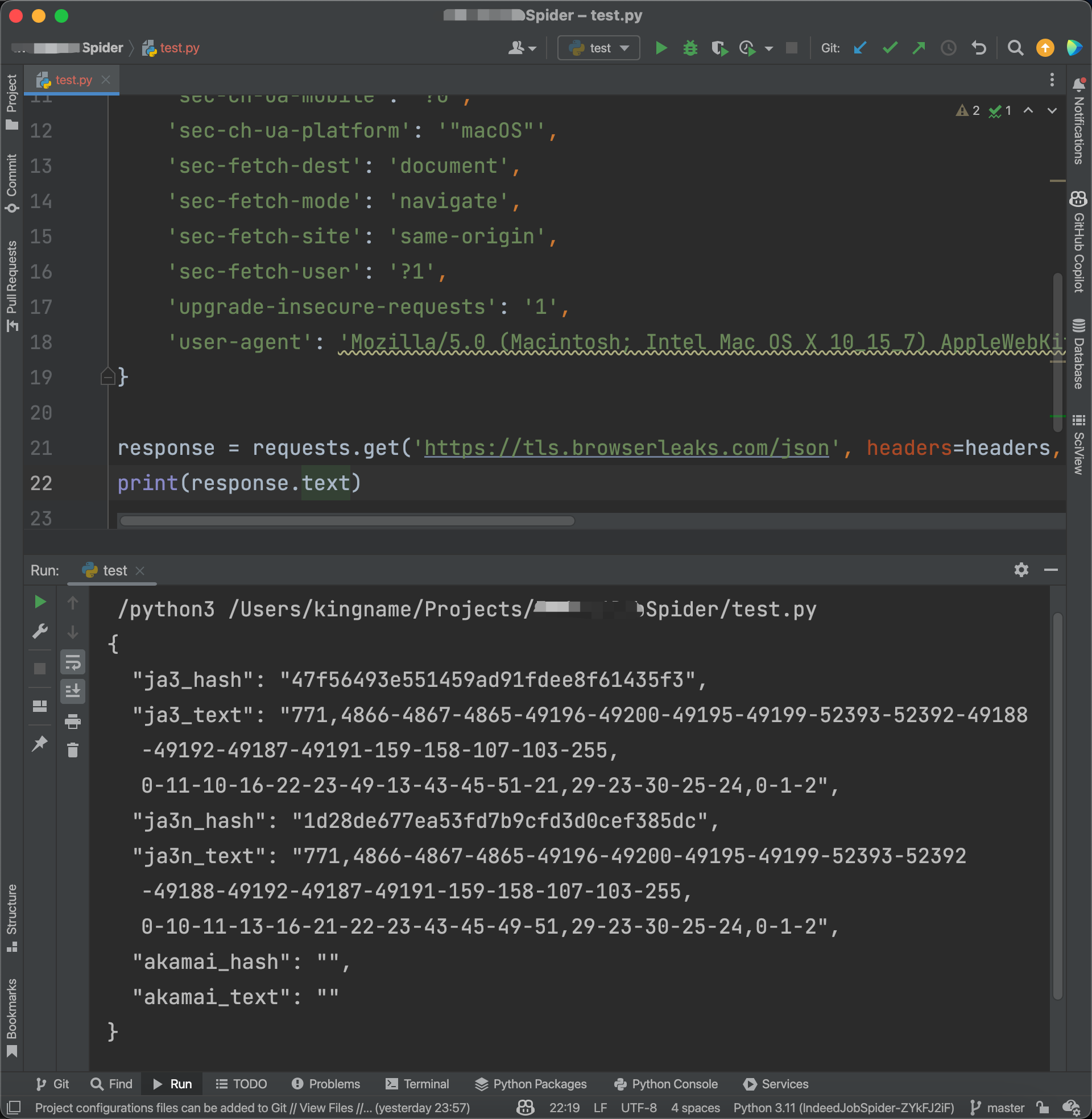
一日一技:Requests被网站识别怎么办?
现在有很多网站,已经能够通过JA3或者其他指纹信息,来识别你的请求是不是Requests发起的。这种情况下,你无论怎么改Headers还是代理,都没有任何意义。我之前写过一篇文章:Python如何突破JA3,但方法非常复杂,很多初学者表示上手有难度。那么今天我来一个更简单的方法,只需要修改两行代码。并且不仅能过JA3,还能过Akamai。先来看一段代码:123456789101112131415161718192021import requests headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/s..
更多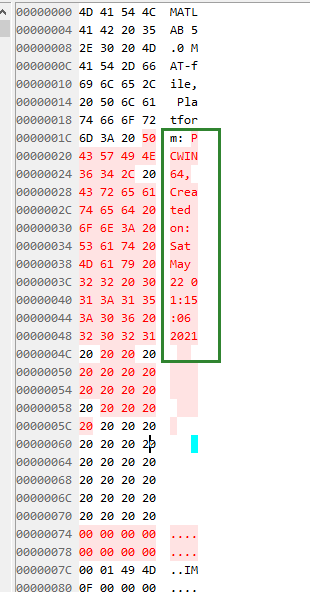
python解析mat文件
Foreword python解析mat文件,mat是matlab的数据集文件 mat文件解析 http://www.mathworks.com/help/pdf_doc/matlab/matfile_format.pdf matlab的官方格式说明,但是这个文档很久没更新了,而且里面图片糊的要死 这里只针对mat v5的格式,目前最新的v7格式,发生的变化比较大,而且其本身也不能向下兼容 mat结构 文件头 固定128字节 数据元素块 - tag,根据tag决定元素块类型,大小 - data,具体内容 - 填充,保证数据对齐用的 Header 前128字节中会有一些mat的文件格式信息,比如是什么版本的mat文件和生成的平台。 这里面比较关键的就..
更多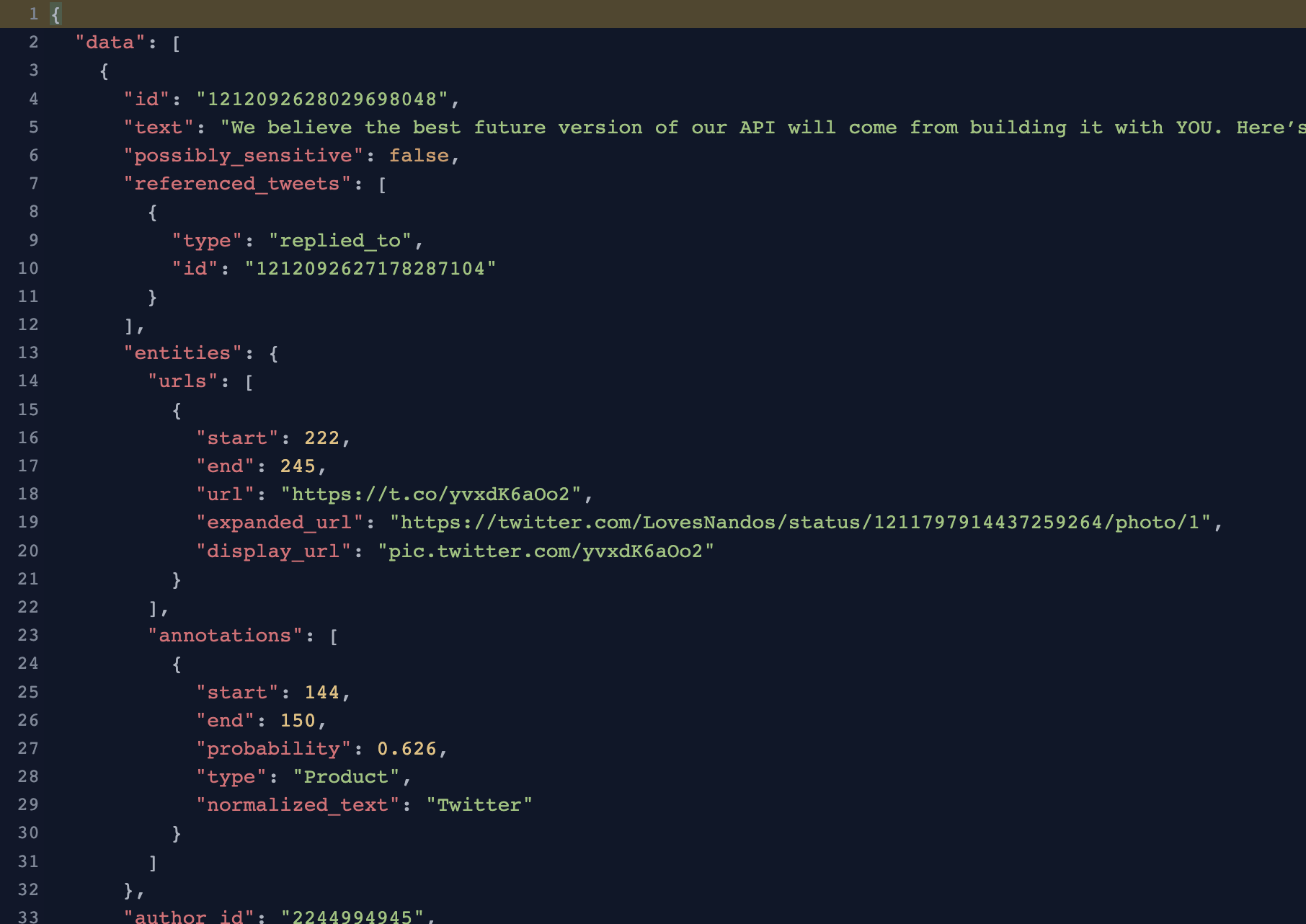
一日一技:JSON如何快速转成对象?
我们知道,在Python里面,要把JSON转成字典是非常容易的,只需要使用json.loads(JSON字符串)就可以了。但如果这个JSON转成的字典,嵌套比较深,那么要读取里面的数据就非常麻烦了。如下图所示:如果我要读取把图中的end减去start字段,那么用字典的时候,代码要写成这样:1result = info['data'][0]['entities']['annotations'][0]['end'] - info['data'][0]['entities']['annotations'][0]['start']光是看到这些方括号和单引号,就够让人头晕了。但如果改成下面这样,看起来就清爽多了:1result = info.data[0].entities.annotations[0].end -..
更多
一日一技:从Pandas DataFrame两个小技巧
今天我从网上下载了一批数据。这些数据是Excel格式,我需要把他们转移到MySQL中。这是一个非常简单的需求。正常情况下,我们只需要5行代码就能解决问题:1234567import pandas as pdfrom sqlalchemy import create_engineengine = create_engine('数据库链接URI', echo=False)df = pd.read_excel('Excel文件路径')df.to_sql(name='表名', con=engine)但我发现,这个下载的文件有两个工作簿(Sheet),第一个Sheet叫做Overall,第二个Sheet叫做Result。我们需要的数据在Result这个工作簿中。那么,在使用Pandas读取时,需要这样写代码:1df..
更多