一日一技:如何同时使用多个GPT的API Key?
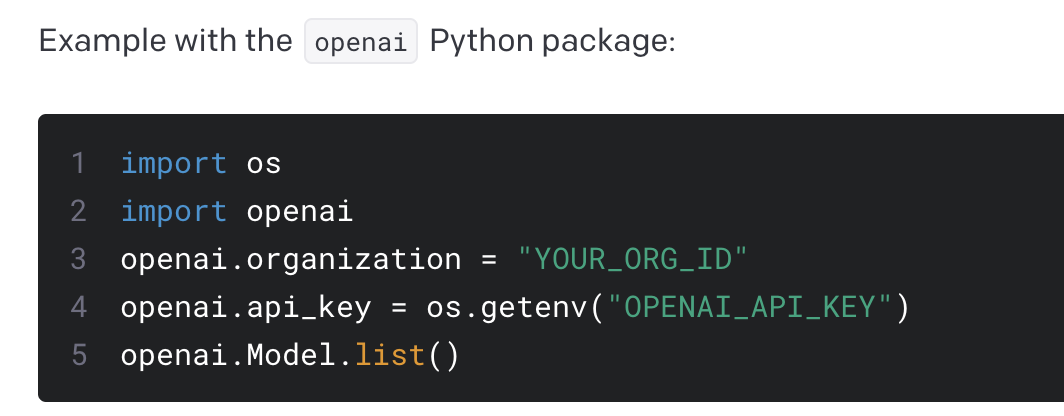
相信很多同学或多或少都在Python中使用过GPT API,通过Python安装openai库,来调用GPT模型。OpenAI官方文档中给出了一个示例,如下图所示:如果你只有一个API账号,那么你可能不觉得这样写有什么问题。但如果你想同时使用两个账号怎么办?有些同学可能知道,微软的Azure也提供GPT接口,在Python中也需要通过openai库来调用,它的调用示例为:当你全局设置了openai.api_type = 'azure'以后,你怎么同时使用OpenAI的GPT接口?这两个文档中给出的示例写法,都是全局写法,一但设定以后,在整个运行时中,所有调用GPT接口的地方,都会使用这里设置的参数:123import openaiopenai.xx = yy有些同学不知道怎么在Python SDK中同时使..
更多
一日一技:从PDF完美提取表格
在之前很长一段时间,从PDF文件中提取表格都是一个老大难的问题。无论你使用的是PyPDF2还是其他什么第三方库,提取出来的表格都会变成纯文本,难以二次利用。但现在好消息来了,专业处理PDF的第三方库PyMuPDF升级到了1.23.0,已经支持完美提取PDF中的表格了。还可以把表格转换为Pandas的DataFrame供你分析。PyMuPDF的使用非常简单,首先我们来安装:1pip install pymupdf pandas openpyxl其中安装pandas是为了能让它转成DataFrame,安装openpyxl是为了能把结果导出为Excel。我们来看一个测试的PDF文件,如下图所示:其中表格在第5页,那么我们编写如下代码,读取第五页的表格:1234567import fitzdoc = fitz.o..
更多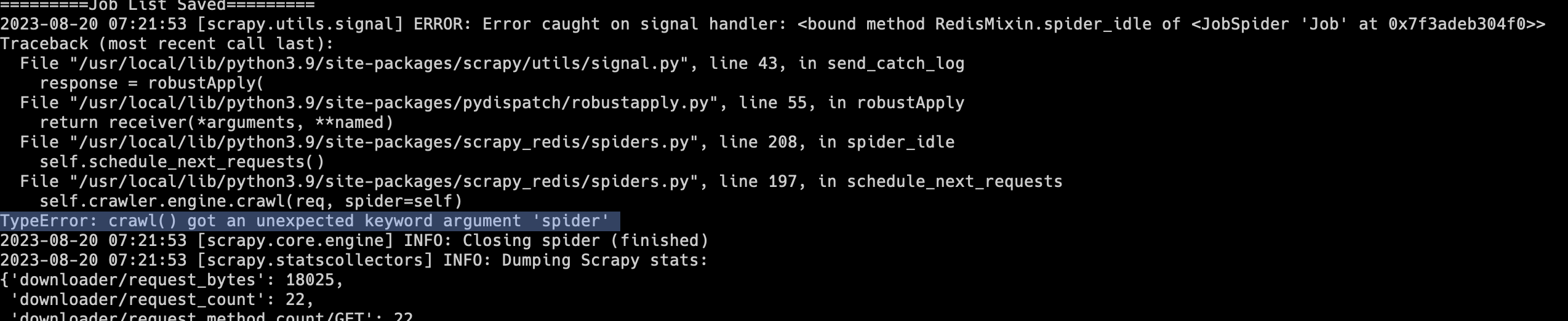
一日一技:Scrapy最新版不兼容scrapy_redis的问题
有不少同学在写爬虫时,会使用Scrapy + scrapy_redis实现分布式爬虫。不过scrapy_redis最近几年更新已经越来越少,有一种廉颇老矣的感觉。Scrapy的很多更新,scrapy_redis已经跟不上了。大家在安装Scrapy时,如果没有指定具体的版本,那么就会默认安装最新版。这两天如果有同学安装了最新版的Scrapy和scrapy_redis,运行以后就会出现下面的报错:1TypeError: crawl() got an unexpected keyword argument 'spider'如下图所示:遇到这种情况,解决方法非常简单,不要安装Scrapy最新版就可以了。在使用pip安装时,绑定Scrapy版本:1python3 -m pip install scrapy==2.9..
更多
一日一技:如何对Python代码进行混淆
目前市面上没有任何方法能够完全避免你的程序被人反编译。即便是3A游戏大作,发布出来没多久也会被人破解。现在只能做到增大反编译的难度,让程序相对无法那么快被破解。我们知道,Python代码默认是公开的。当你要把一个Python项目给别人运行的时候,一般来说别人就能看到你的全部源代码。我们可以使用Cython、Nuitka对代码进行打包,编译成.so文件、.dll文件或者是可执行文件,从而在一定程度上避免别人看到你的源代码。我在字节的时候,内部的一个系统就是使用Cython打包的,然后部署到客户的服务器上。Cython、Nuitka在打包大型项目时,需要写大量的配置文件甚至是额外的程序,有一定的使用成本。如果你对安全的要求并没有那么高,那么其实你只需要对Python代码进行混淆,就能防止自己的代码被人轻易看到..
更多一日一技:方法不对,代码翻倍。Requests如何正确重试?
程序员是一个需要持续学习的群体,如果你发现你现在写的代码跟你5年前的代码没什么区别,说明你掉队了。我们在做Python开发时,经常使用一些第三方库,这些库很多年来持续添加了新功能。但我发现很多同学在使用这些第三方库时,根本不会使用新的功能。他们的代码跟几年前没有任何区别。举个例子,使用Request发起HTTP请求,请求失败时,不管什么原因,原地重试最多3次。很多人主要有下面3种写法来重试。常见的老方法使用第三方库这类同学会使用一些专业做重试的第三方库,例如tenacity。详见我的这篇文章:Tenacity——Exception Retry 从此无比简单手动写装饰器这类同学会使用装饰器,所以一般会手写装饰器从而复用,例如:123456789101112131415def retry(func): ..
更多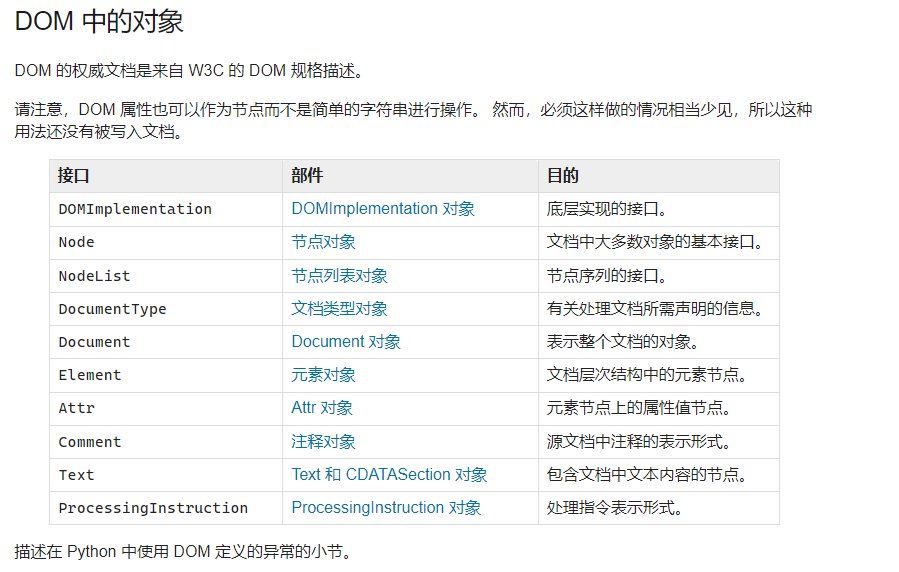
Python读取XML并修改导出
Foreword SES的排除编译文件非常蠢,他不能将这个设置继承给其他配置文件,这就导致如果配置文件很多,每次变动需要把每个配置文件重新设置一次,手动的话很容易设置漏了,所以写个脚本来直接处理这个事情 XML 简单说现在有4个主配置,基于他们每个衍生出来2个配置,也就是一共12个配置,目标是每次只要配置这四个主配置,其他配置就能自动同步他们的排除编译文件的配置。 想了想用批处理或者shell实现,有点麻烦,还是XML,光是分析什么的写起来就很复杂,所以干脆用python写了,CI调用 XML DOM基础 DOM将XML以树状的方式进行构建或者展示,所以每个节点都有子节点或者父节点 <collection shelf="New Arrivals"> <m ovie..
更多
Houdini python 入门
Foreword 很久之前写过一次导出,但是代码找不到了,然后新版本的Houdini很多东西都变了,老代码很多地方不兼容了 新版的Houdini我选了19.5 python3.7,很多东西和以前的python2.7 不同了 Houdini Houdini有三种脚本语言,python,Vex,C++,类似Maya 有MEL、python、C++等 传统的python,由于单线程,很多地方都有瓶颈 C++,效率级别,但是开发起来比较麻烦 而Vex 有点类似C或者C++的语言设计,是直接编译运行的,并且可以并发多线程,所以效率上比python高很多,同时程序写起来也比较简单,算是既要又要的结合体。 当然这里Vex性能这么高,也是有代价的,Vex能干的事情是有限的,python和C++能够使用的A..
更多
一日一技:Python装饰器的执行顺序
说到Python装饰器的执行顺序,有很多半吊子张口就来:靠近函数名的装饰器先执行,远离函数名的装饰器后执行。这种说法是不准确的。但是这些半吊子多半还会不服,他们会甩出一段代码给你,来『证明』自己的观点:123456789101112131415161718def decorator_outer(func): print("我是外层装饰器") def wrapper(): func() return wrapperdef decorator_inner(func): print("我是内层装饰器") def wrapper(): func() return wrapper @decorator_outer@decorator_innerdef..
更多
轻声低语,藏在光芒下的语音转文字模型Whisper
ChatGPT的模型gpt-3.5-turbo发布当天,OpenAI还开源了一个语音转文本的模型:Whisper。但由于ChatGPT本身太过于耀眼,很多人都忽略了Whisper的存在。我当时也是这样,我一度以为,Whisper也是一个API,需要发送POST请求到OpenAI的服务器上,然后它传回识别的结果。所以我很长一段时间一直都没有试用过这个模型。直到前几天,我看到有人在少数派上面发了一篇文章,介绍他刚做的语音识别App,并且说这个App基于Whisper,完全不需要联网。我当时还奇怪,不联网你怎么调Whisper的API?于是我终于去认真了解了一下Whisper,发现它是OpenAI开源的语音转文字的模型,并不是API服务。这个模型只需要有Python就能本地离线运行,不需要联网。Whisper的..
更多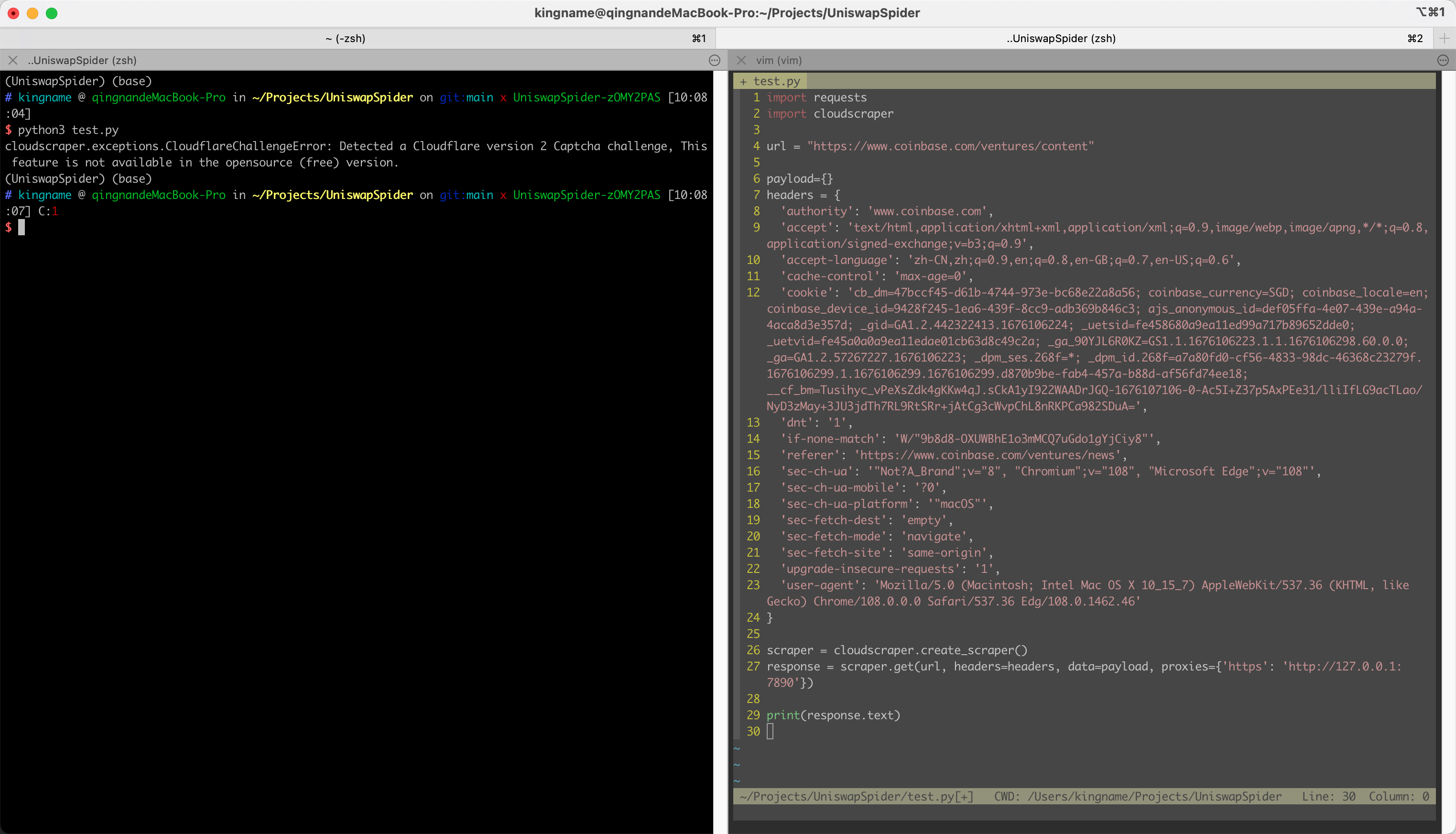
一日一技:【最新】再次突破CloudFlare五秒盾付费版
去年我写了一篇文章:一日一技:如何捅穿Cloud Flare的5秒盾 ,这篇文章使用的第三方库『cloudscraper』可以绕过免费版的五秒盾。但遇到付费版就无能为力了。最近在爬币圈的网站,其中有一个网站叫做:Codebase使用的就是付费版的CloudFlare五秒盾。当我们使用CloudScraper去爬时,报错如下:那么现阶段,付费版的CloudFlare五秒盾,有没有什么办法绕过呢?其实方法非常简单。只需要使用Docker运行一个容器就可以了。启动命令为:123456docker run -d \ --name=flaresolverr \ -p 8191:8191 \ -e LOG_LEVEL=info \ --restart unless-stopped \ ghcr.io/fla..
更多