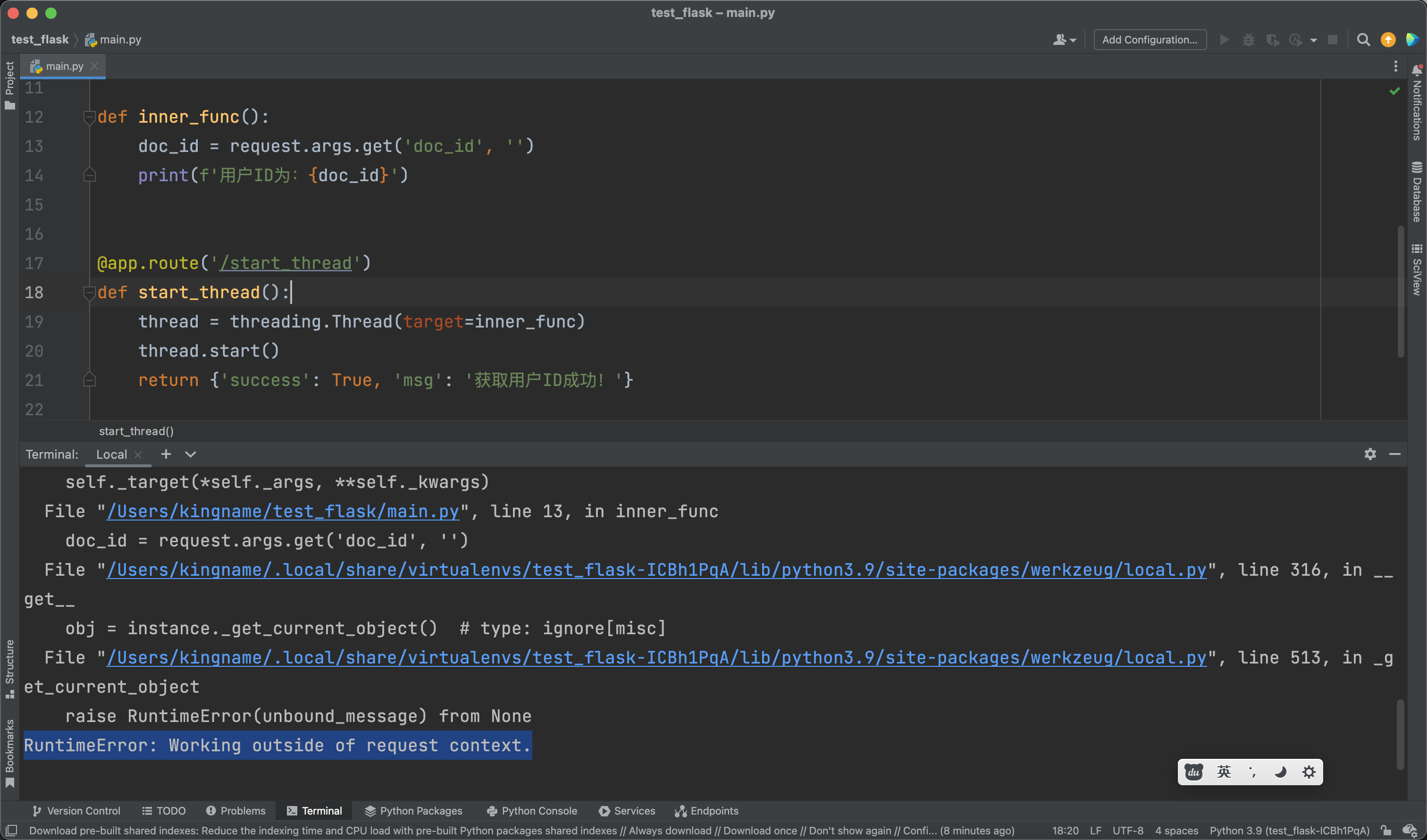
Flask中如何嵌套启动子线程?
如果你在Flask中启动过子线程,然后在子线程中读写过g对象或者尝试从request对象中读取url参数,那么,你肯定对下面这个报错不陌生:RuntimeError: Working outside of request context..例如下面这段Flask代码:123456789101112131415import threadingfrom flask import Flask, requestapp = Flask(__name__)def inner_func(): doc_id = request.args.get('doc_id', '') print(f'用户ID为:{doc_id}')@app.route('/start_thread')def start_thread()..
更多长见识,让大家看看什么是垃圾代码
在以前的文章中,在微信群中,我多次强调,写函数的时候,不要把所有参数放到一个大字典里面作为参数到处传,否则时间久了以后,根本不知道字典里面有哪些数据:1234def parse(data): name = data['name'] age = data['age'] xxx = data['xx']上面这样写,对原作者来说确实简单,但是如果代码还有别人来维护,他就根本不知道这个字典里面有哪些数据。必须要一层一层查找调用链,费时费力。但我是真的万万没想到,还有比上面这种写法更傻X的代码。真的可以称得上是垃圾中的垃圾。我们来看看下面这段代码。现在有一个类A,里面有两千多行代码。还有一个类B,里面有三千多行代码。这两个类里面有一些实例方法,有700多行代码。这些我都忍了。更要命的是,初始化类B..
更多
一日一技:用一个奇技淫巧把字符串转成特定类型
我们有时候可能会需要把一个字符串转换成对应的类型。例如,把'123'转换为int类型的123;或者把'3.14'转成浮点数3.14。前提条件是不能使用eval或者exec。这是一个非常简单的功能,常规做法直接使用if判断就可以了:123456def convert(data, target_type): if target_type == 'int': return int(data) elif target_type == 'float': return float(data) ...有些同学觉得写if判断麻烦,也可能会用字典来处理:1234567def convert(data, target_type): type_map = { '..
更多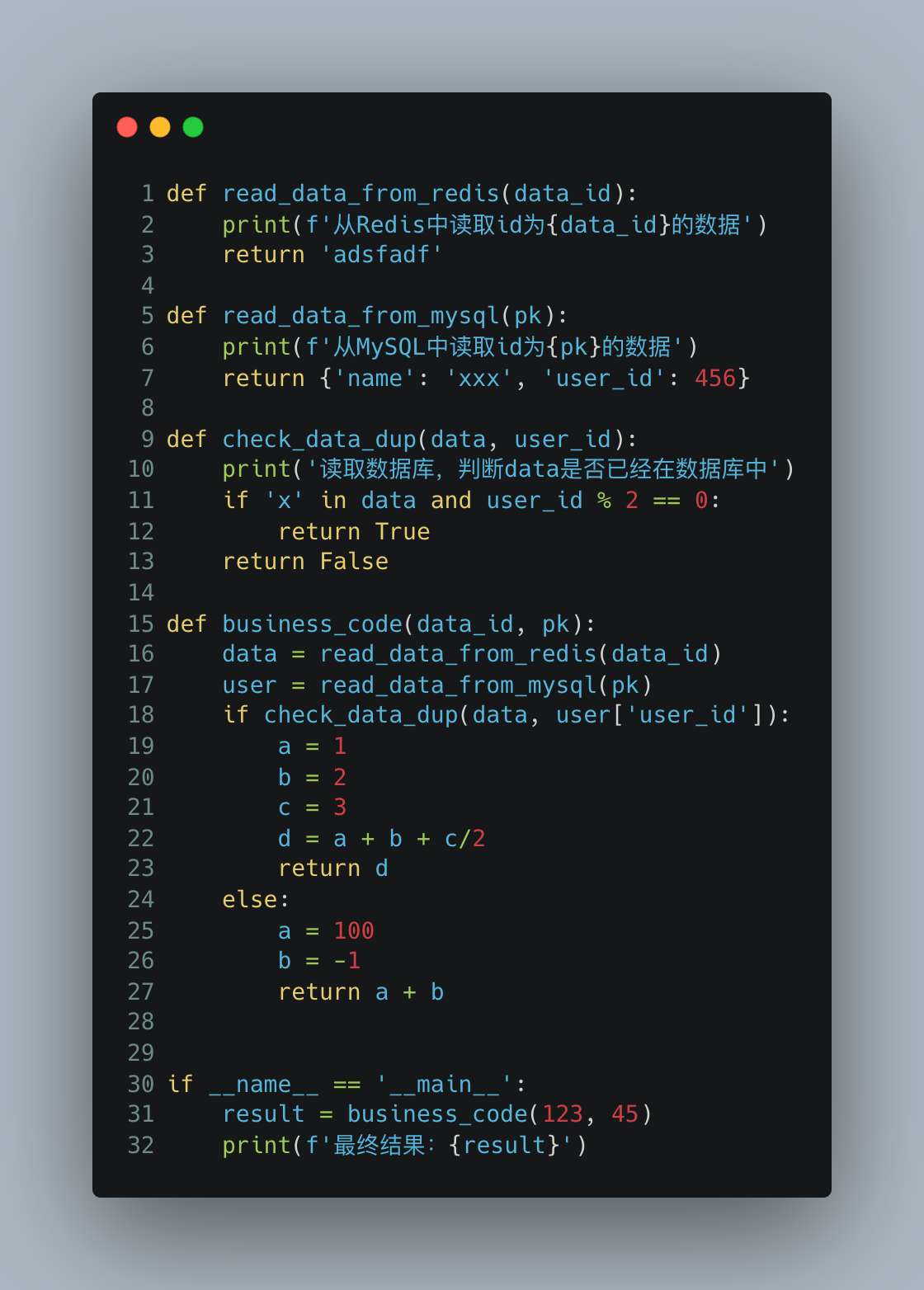
一日一技:如何正确为历史遗留代码补充单元测试?
我们知道,在软件工程中,单元测试是保证软件质量的重要手段之一。一个优秀的代码,单元测试的代码量,经常会超过被测试的代码本身。一个理想化的开发团队,可能有三分之二的时间是在写测试,剩下的三分之一时间才是写业务代码。如果你的项目是从一开始就写单元测试,那么你写起来应该轻松又愉快,因为单元测试会促使你的代码自身变成可测试的代码。但如果你接手了一个大项目,里面已经有几十万行代码了,那么给这些代码补单元测试会让你知道什么叫做痛不欲生。你会发现有一些函数,它让你不知道怎么写测试代码。我们来看一个例子:我想测试的是business_code里面,check_data_dup分别返回True或者False的时候,下面代码的逻辑。也就是说,我只关心第18-27行的逻辑。这个时候不关心MySQL和Redis。但是每次测试都要..
更多
一日一技:Python如何动态替换对象的方法?
今天有同学在公众号粉丝群问了这样一个问题:他的问题,简单来说,就是想动态替换一个对象的实例方法,简化代码如下:123456789101112class Test: def __init__(self, name): self.name = name def work(self, job): print(f'{self.name}正在{job}')def work(self, job1, job2): print(f'{self.name}正在同时做两个工作,分别是{job1}和{job2}')t = Test('kingname')t.work = work当我们在替换之前,直接运行t.work('job'),效果如下:这个同学期望在替换以后,运行t.work..
更多
一日一技:如何实现带timeout的input?
我们知道,在Python里面,可以使用input获取用户的输入。例如:但有一个问题,如果你什么都不输入,程序会永远卡在这里。有没有什么办法,可以给input设置超时时间呢?如果用户在一定时间内不输入,就自动使用默认值。要实现这个需求,在Linux/macOS系统下面,我们可以使用selectors。这是Python自带的模块,不需要额外安装。对应的代码如下:123456789101112131415import sysimport selectorsdef timeout_input(msg, default='', timeout=5): sys.stdout.write(msg) sys.stdout.flush() sel = selectors.DefaultSelector()..
更多
一日一技:把自然语言描述的时间转成标准格式
如果你使用过嘀嗒清单或者Todoist,那你应该知道他们有一个很好用的功能,那就是自动识别任务中的时间,例如:1下周二下午三点给老板发邮件它会自动识别为:今天,公众号粉丝群里面,有一个叫做NowAnti的同学推荐了一个项目,叫做司南,它就可以让Python实现这样的功能。我们来看看这个第三方库怎么使用。首先pip安装它:1python3 -m pip install sinan安装完成以后,使用方法非常简单:1234from sinan import Sinanobj = Sinan('下周二下午三点给老板发邮件')result = obj.parse()print(result)运行效果如下图所示:这个库不仅可以解析时间,它还可以解析更复杂的语句,例如:12>>> obj = Sina..
更多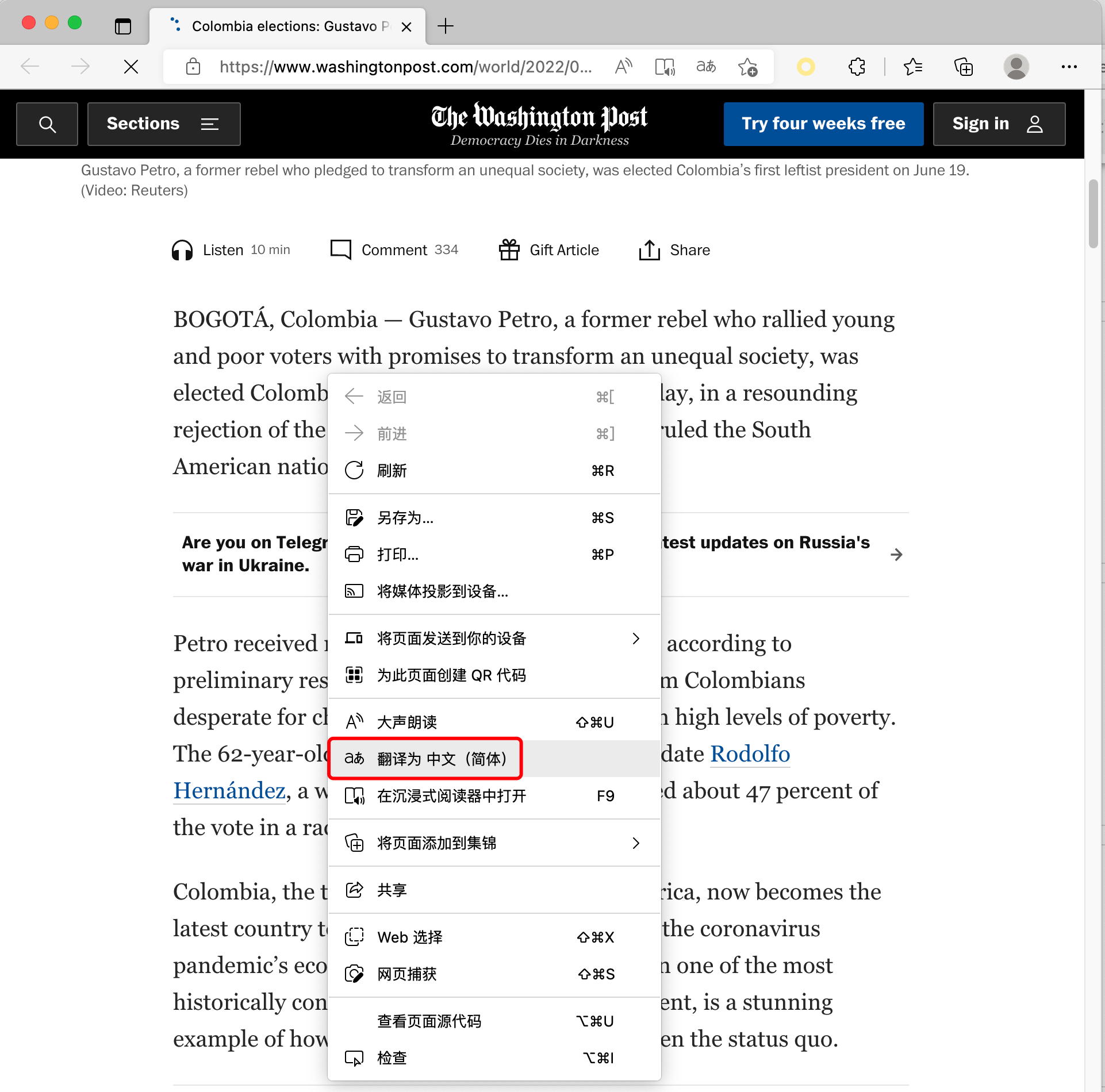
一日一技:使用Python翻译HTML中的文本字符串
相信大家都用过浏览器的翻译网页功能,例如对于下图这个英文网页:一键翻译成中文以后是这样的:你可能会觉得这个功能很简单,不就是字符串替换吗?那你可以试一试把下面这个HTML片段中的标签下面的英文翻译成中文。其它标签中的不要改动:123<div><p>if you want to parse date and time, your could use <em>datetimeem>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()span> this is so easy.p>div>在标签中的dat..
更多
一日一技:让你的正则表达式可读性提高一百倍
正则表达式这个东西,强大是强大,但写出来跟个表情符号一样。自己写的表达式,过一个月来看,自己都不记得是什么意思了。比如下面这个:1pattern = r"((?:\(\s*)?[A-Z]*H\d+[a-z]*(?:\s*\+\s*[A-Z]*H\d+[a-z]*)*(?:\s*[\):+])?)(.*?)(?=(?:\(\s*)?[A-Z]*H\d+[a-z]*(?:\s*\+\s*[A-Z]*H\d+[a-z]*)*(?:\s*[\):+])?(?![^\w\s])|$)"有没有什么办法提高正则表达式的可读性呢?我们知道,提高代码可读性的方法之一就是写注释,那么正则表达式能不能写注释呢?例如对于下面这个句子:1msg = '我叫青南,我的密码是:123kingname456,请注意保密。'我要提取其中的..
更多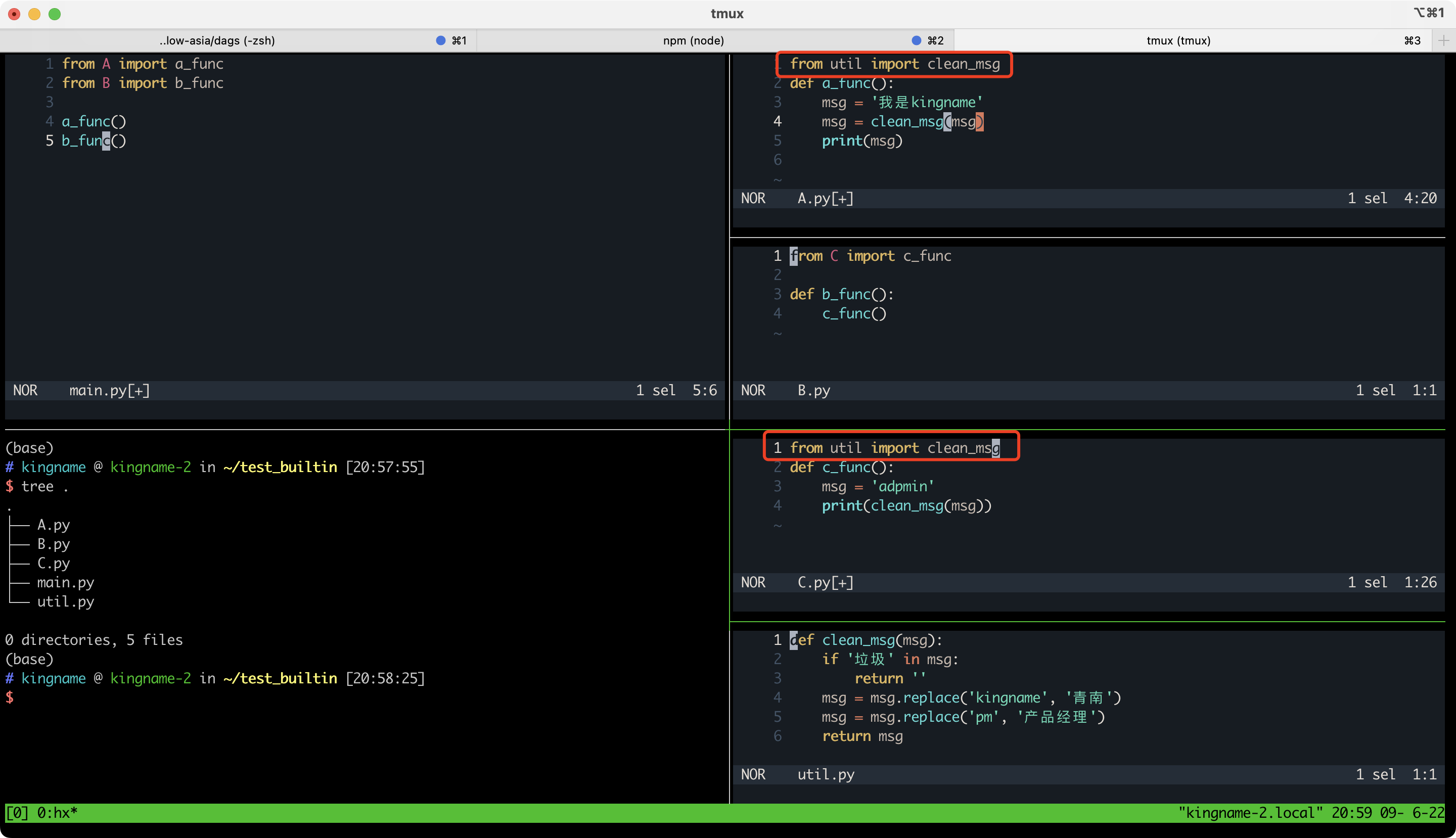
一日一技:如何让自己的工具函数在Python全局可用?
我们在开发Python项目的时候,经常会写一些工具函数。为了在项目里面多个.py文件中使用这个工具函数,就不得不在多个地方都导入它,非常麻烦。例如下面这个例子:在A.py和C.py文件都要使用clean_msg这个工具函数,那么他们就都要从util.py中导入clean_msg。这似乎理所当然。但今天我在看icecream/builtins.py源代码的时候,突然发现了一个高级用法,可以让我们使用工具函数的时候,就像使用Python的print函数一样,不用导入,而是直接使用。我们先来看看效果:大家注意A.py和C.py,我并没有导入clean_msg而是直接使用了这个函数。并且运行完全正常。关键原理就在入口文件main.py,被我框住的3行:1234import builtinsfrom util im..
更多