基于企业微信搭建一个ChatGPT应用
Foreword 基于企业微信搭建一个ChatGPT服务,比较巧妙的是刚好这个GPT是不想公开的,又想限制权限,又怕被滥用,在企微里使用刚刚好。最好这个服务还是不需要我去专门找VPS,解锁ChatGPT等服务的IP,也不用管国内能不能正常访问。 chatgpt-on-wechat 主要是基于以下项目 https://github.com/zhayujie/chatgpt-on-wechat Wechat robot based on ChatGPT, which using OpenAI api and itchat library. 使用ChatGPT搭建微信聊天机器人,基于GPT3.5/4.0 API实现,支持个人微信、公众号、企业微信部署,能处理文本、语音和图片,访问操作系统和..
更多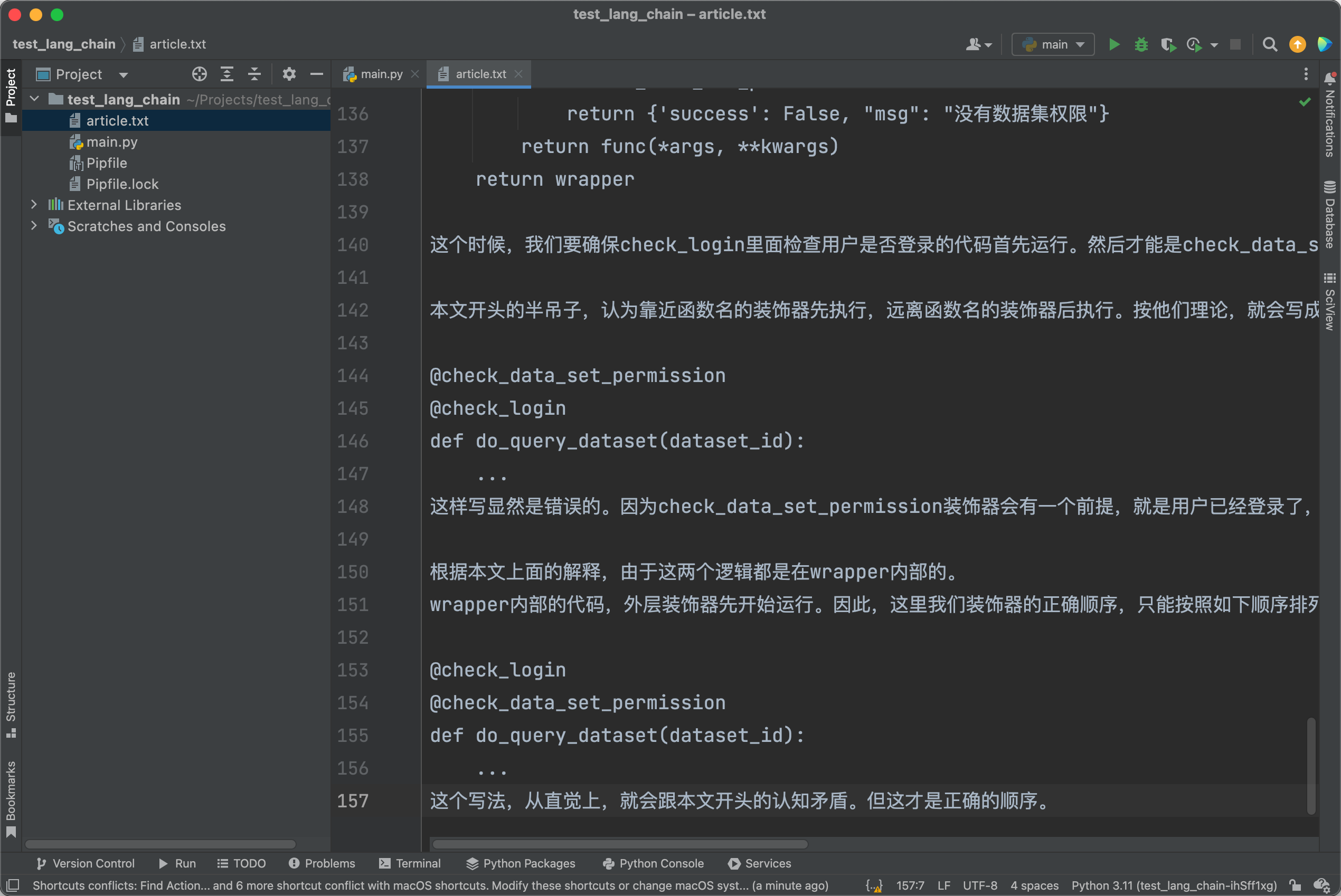
一日一技:在LangChain中使用Azure OpenAI Embedding服务
如果大家深入使用过ChatGPT的API,或者用过听说过AutoGPT,那么可能会知道,它背后所依赖的语言框架LangChain。LangChain能够让大语言模型具有访问互联网的能力,以及与其他各种API互动交互,甚至是执行系统命令的能力。ChatGPT的prompt支持的Token数量是有限的,但是使用LangChain,能够很容易实现ChatPDF/ChatDoc的效果。即使一段文本有几百万字,也能让ChatGPT对其中的内容进行总结,也能让你针对文本中的内容进行提问。Question Answering over Docs这是LangChain官方文档给出的示例,如果你使用的是OpenAI官方的API,你只需要复制粘贴上面的代码,就可以实现针对大文本进行提问。如果你使用的是Azure OpenAI..
更多
助力大语言模型训练,无压力爬取六百亿网页
ChatGPT一炮而红,让国内很多公司开始做大语言模型。然后他们很快就遇到了第一个问题,训练数据怎么来。有些公司去买数据,有些公司招聘爬虫工程师。但如果现在才开发爬虫,那恐怕已经来不及了。即使爬虫工程师非常厉害,可以破解任意反爬虫机制,可以让爬虫跑满网络带宽,可是要训练出GPT-3这种规模的大语言模型,这个数据并不是一天两天就能爬完的。并且,有很多老网站的数据,早就被删除了,爬虫想爬也爬不到。如果你看了今天这篇文章,那么恭喜你,你即将知道如何快速获取600亿网站的数据。从2008年开始爬取,这些网站数据横跨40多种语言。截止我写这篇文章的时候,最新的数据积累到了2023年2月。只要是Google现在或者曾经搜索得到的网站,你在这里都能找到。唯一制约你的,就是你的硬盘大小——仅仅2023年1月和2月的网页加..
更多Facebook的类ChatGPT大语言模型LLaMA模型下载地址
分享一个 前几天泄露出来的Facebook的AI语言模型,LLaMA,总共220G运行有官方和第三方的运行示例,里面没有模型下载地址,官方途径是需要邮箱申请。官方例子: https://github.com/facebookresearch/llama内存优化版: https://github.com/tloen/llama-int8 据说只要3090可以运行,作者4090测试完成计算优化版: https://github.com/markasoftware/llama-cpu CPU可以运行,但是需要32G内存下载下载的脚本地址来自这里, https://github.com/shawwn/llama-dl下载速度还行,下了一个晚上, 我已经下载好了。下载链接导出来之后,百度云离线下载不了,..
更多