
配置管理工具之kconfig
Foreword 绕了这么大一圈,似乎只有kconfig是比较成熟的,能与之相媲美的管理工具很少 Kconfig 安装 在windows下使用Kconfig,至少得有python,否则界面等内容无法正常显示 python需要先安装这几个包 python -m pip install windows-curses python -m pip install kconfiglib 测试安装,可以正常显示命令 menuconfig -h 测试 参考工程sample_1 https://github.com/bobwenstudy/test_kconfig_system 编译所有 make all 修改配置 menuconfig 运行main.exe就能看到结果了 ..
更多
一日一技:为什么我很讨厌LangChain
一说到RAG或者Agent,很多人就会想到LangChan或者LlamaIndex,他们似乎觉得这两个东西是大模型应用开发的标配。但对我来说,我特别讨厌这两个东西。因为这两个东西就是过度封装的典型代表。特别是里面大量使用依赖注入,让人使用起来非常难受。什么是依赖注入假设我们要在Python里面模拟出各种动物的声音,那么使用依赖注入可以这样写:12345678910111213141516171819202122def make_sound(animal): sound = animal.bark() print(f'这个动物在{sound}')class Duck: def bark(self): return '嘎嘎叫'class Dog: def bark(sel..
更多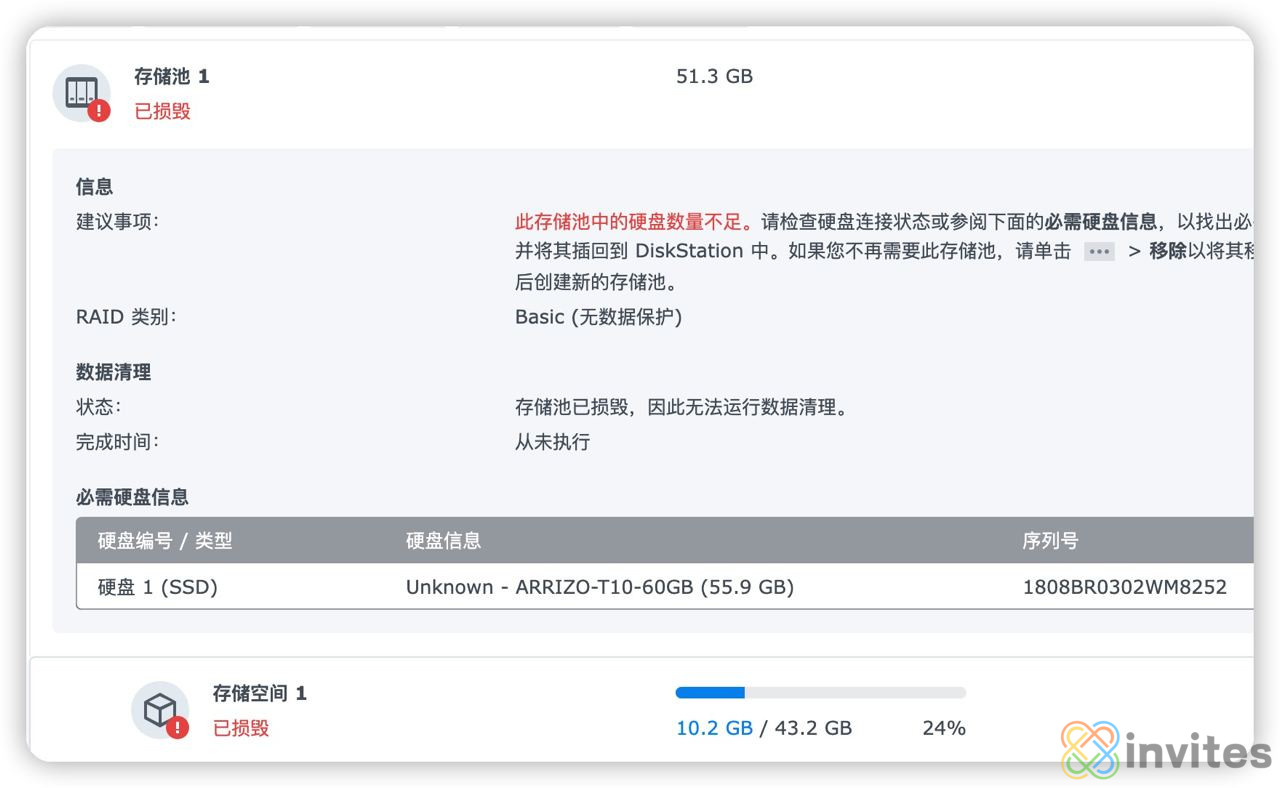
记一次群辉存储空间损毁后 QB 种子恢复尝试
前记应该是 蜗牛星际 电压太高加上 固态不稳定 导致的这块盘我只放服务. 基本不写这块盘. 像 nastool, qb, tr, emby, iyuu, homepage 等全被一套带走了.不幸中的万幸, 之前的 qb 页面开着没关.因为之前我开着 qb 页面没关, 所有抢救下来了 qb 页面(包括所有的种子详情)大约是 1200 种, 因为 qb 页面里面可以拿到 torrent hash, 所以 torrent 有望恢复主要流程⌘ + S, 保存 qb web 页面成单个 html对 qb web 页面结构进行分析从 qb web 页面提取 torrent hash, (分类, 标签, 保存路径)向 iyuu 通过 torrent hash 进行 辅种链接查询根据 iyuu 返回的 sid 和 tor..
更多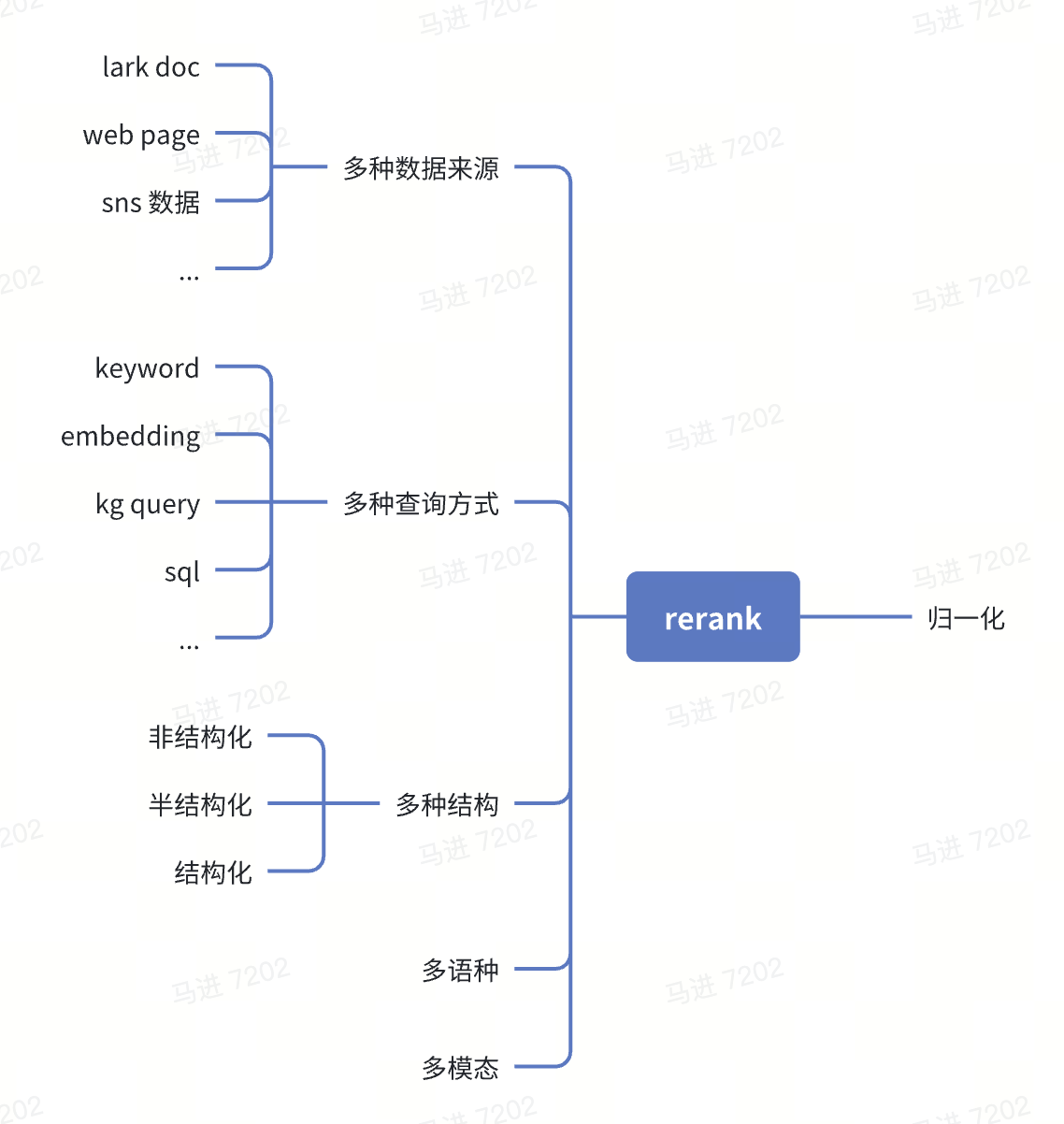
聊聊 Rerank:从 BERT 到大模型的技术旅程
从搜索引擎到大语言模型,Rerank 技术一直在默默发挥着”最后一公里”的关键作用。前言在 NLP 场景中,Rerank 作为一个关键环节,承担着对多路召回、多数据来源、多模态、多结构等不同类型数据的归一化和精筛作用。它能有效地整合和优化各类召回结果,对提升检索系统的整体性能至关重要。本文将介绍 rerank 相关的技术概念、业界进展,以及对业务 产生价值的可能性。 Rerank-从 BERT 到大模型的技术旅程/overall.png 正文什么是 RerankRerank 并不是新兴的技术,其发展历史可追溯到搜索引擎,其历程可浓缩为 3 个主要阶段: Rerank-从 BERT 到大模型的技术旅程/timeline.png 一句话介绍:Rerank 是一种对初步检索结果进行重排序的优化技术,以提..
更多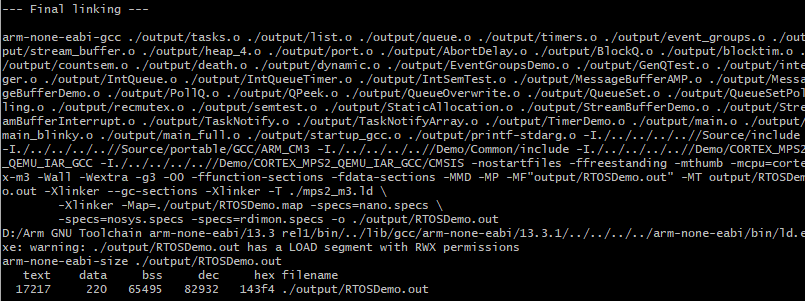
QEMU模拟运行FreeRTOS
Foreword 测试一下QEMU模拟运行FreeRTOS QEMU QEMU安装需要先安装MSYS2 直接下载安装 https://www.msys2.org/ 安装完成以后,QEMU使用pacman包进行安装 https://www.qemu.org/download/#windows pacman -S mingw-w64-x86_64-qemu 添加新的环境变量,把刚才安装的路径加进去 D:\msys64\mingw64\bin 查看版本,显示正确 qemu-system-arm -version QEMU emulator version 9.1.1 Copyright (c) 2003-2024 Fabrice Bellard and the QEM..
更多
畅网 N100 黑群晖踩坑记录
硬件配置畅网 N100 先锋版 V2这个图是旧版的, 新版略有区别槽点必知先锋版 V1 和V2区别节选自某宝 畅网微控品牌店, (只在这个店看到过这个说明, 记录一下)增加多2个 USB2.0、2个USB3.2多了一个标准SATA数据接口,增加了一个信号侦测芯片.当 WiFi接口插了无线网卡或转接卡之后,SATA口自动失效. 当WiFi接口没插东西,SATA口插了硬盘,SATA口生效两者只能二选一另外V2版本用不了 三选一的转接卡 协议冲突, 只能用 WiFi转M2 的转接卡 或无线网卡。V1和V2 BIOS 不通用,不能互刷V2版本多了一个物理自启动开关,如果要通电自启动直接拨杆到 ON就可以了不需要去 BIOS里面修改任何东西。找不到硬盘/不支持 M2 NVME 硬盘RR 引导添加插件 nvmesys..
更多
宏管理工具之lite-manager
Foreword 体验一下群友的宏管理工具 lite-manager https://gitee.com/li-shan-asked/lite-manager 群友的宏管理工具,主要在gitee上更新,github更新不及时,release文件可能不能用 环境 至少需要一个make和gun c的环境,之前系统里一直有一个MinGW32 13年的版本,gcc大概只有6,编译过不去(后来发现应该不是这个问题) 通过下面的方式在线安装MinGW64 https://github.com/Vuniverse0/mingwInstaller/releases/download/1.2.1/mingwInstaller.exe 安装完成以后添加环境路径 如果环境里没有多的make,可以把..
更多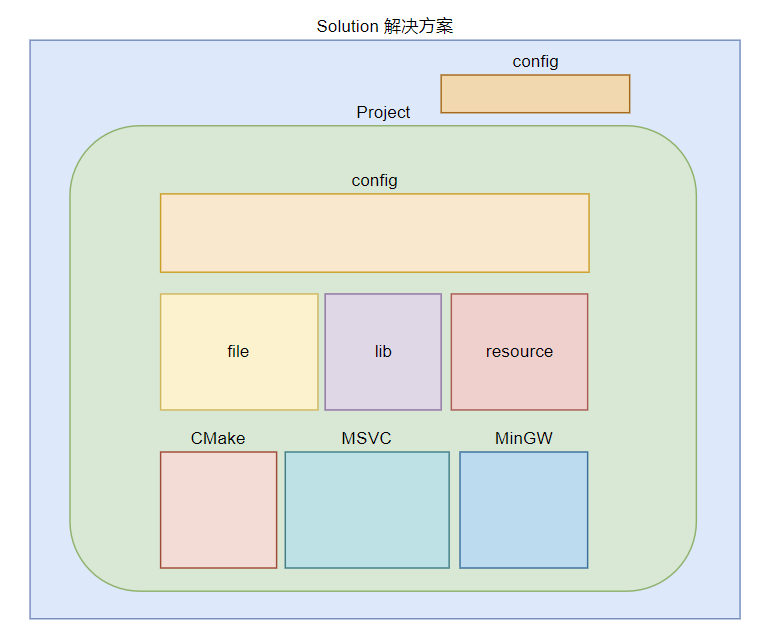
构建工具之xmake
Foreword 当一套代码兼容了多个软件、硬件,需要面对不同情况下,进行不同的build的时候,就需要额外的工具来辅助完成这一个事情。 通常IDE构建 多数情况下,我们使用的各种IDE都有自己的一套UI或者配置文件来完成这个事情。 以VS为例,一般情况对于一个项目的整体构建的配置大概是这样的 顶级就是Solution 一个解决方案,一个方案下面可能有多个工程共同构成,比如某些工程依赖的库、依赖的测试工程、依赖的一些子应用。解决方案里必然也有一个配置,用来指定各个工程在解决方案级别进行构建时,各个工程适用什么配置来进行组合构建。 单独的工程来说,有一个或者多个配置文件,比如debug和release,这种最常见的,剩下就是对于整个项目的源码文件、库文件、依赖文件、资源文件的组合,可能不同配..
更多ss命令抓linux下偶发端口访问
Linux服务器一直有个TCP连上来发数据,跑到对应的机器上发现连接已经断了,对应的进程也退出了。估计是某种定时任务。 排查代码无果,只能通过命令行来监控。这里直接上ss命令 while true; do pid=$(ss -tanpe state established 'dst 10.11.22.33:4455' | awk 'match($0,/pid=([0-9]+)/,a){print a[1]}'); [[ -n $pid ]] && tr '\0' ' ' </proc/$pid/cmdline ; sleep 0.2; done; 解释下: while true; do ...; sleep 0.2; done;每0.2s反复刷新执行指定命令。 ss -ta..
更多kcp 与 kcp-go 的设计与实现
引言 最近深入研究了 KCP 的实现,通读了 KCP 原版及其 Go 语言实现(kcp-go)的源码。在阅读代码的过程中,还参考了许多优秀的博客文章,十分感谢这些博主的分享。有了这些珠玉在前,我也整理了一些自己对 KCP 的理解,作为学习过程中的记录和总结。 两个核心数据结构 ikcpcb 是 KCP 的控制块(KCP Control Block)数据结构,包含一条 KCP 连接的所有状态信息和参数。作为 KCP 协议的核心数据结构,它负责管理数据传输、重传机制以及流量控制等功能。 segment 是表示 KCP 数据段的结构体,用于描述一个数据包或控制包。每个 segment 都包含数据段的头部信息和数据部分。 这两个数据结构定义了 KCP 使用的所有关键字段。关于它们的具体含义,Luyu Huang ..
更多